







Kuberners的网络模型假定了所有Pod都在一个可以直接连通的扁平的网络空间中,这在GCE(Google Compute Engine) 里面是现成的网络模型,Kubernets假定这个网络已经存在。
而在私有云里搭建Kubernets集群,就不能假定这个网络已经存在了。我们需要自己实现这个网络假设,将不通节点上的Docker容器之间的互相访问先打通,然后运行kubernetes
一、Kubernetes网络模型
在Kubernetes网络中存在两种IP(Pod IP和Service Cluster IP),Pod IP 地址是实际存在于某个网卡(可以是虚拟设备)上的,Service Cluster IP它是一个虚拟IP,是由kube-proxy使用Iptables规则重新定向到其本地端口,再均衡到后端Pod的。下面讲讲Kubernetes Pod网络设计模型:
1、基本原则:
每个Pod都拥有一个独立的IP地址(IPper Pod),而且假定所有的pod都在一个可以直接连通的、扁平的网络空间中。
2、设计原因:
用户不需要额外考虑如何建立Pod之间的连接,也不需要考虑将容器端口映射到主机端口等问题。
3、网络要求:
所有的容器都可以在不用NAT的方式下同别的容器通讯;所有节点都可在不用NAT的方式下同所有容器通讯;容器的地址和别人看到的地址是同一个地址。
二、Kubernetes网络基础
访问场景:
1、同一个Pod内的多个容器之间的访问
第一种通信 Pod内容器之间的通信 ,其中图中有三个网卡, 包括两个eth0 和一个 docker0, 第一个eth0是 用作于pod的虚拟网卡, 第二个eth0是物理机的真实网卡,Docker0就是 第一个eth0虚拟IP的 网关, 这容器1与容器2 访问的过程中,只需要eth0内部完成, 不涉及docker0 和 eth0 ,因为一个 Pod内部的所有容器通过 pause容器共享同一个网络命名空间,包括它们的 IP地址、网络设备、配置等都是共享的,所以它们之间的访问可以用localhost地址 + 容器端口就可以访问。和docker0 以及 物理网卡是没有交互的。
这里说一下pause容器,在Kubernetes中,pause容器是pod中所有容器的父容器,运行了一个非常简单的进程,它不执行任何函数,本质上永远休眠。

那如果两个pod在同一个宿主机上 ,如何访问呢?
2、同一Node中Pod间通信:
这这张图上 node1上 运行了 pod1 和pod2 , 地址分别是IP1 IP2
同一Node中Pod的默认路由都是docker0的地址,由于它们关联在同一个docker0网桥上,IP1、IP2都是从docker0网段上动态获取的,它们之间可以通过docker0作为路由量进行通信,
所以理所应当是能直接通信的。而且不需要使用DNS、etcd这种其他的发现机制 去 辅助通信

3、不同Node中Pod间通信:
基于以上两种网络访问场景,我们知道 Pod之间要想实现访问 必须是 通过Pod IP进行通信的,Pod的IP地址是由各Node上的docker0网桥动态分配的。
因为不同Node之间的通信只能通过Node的物理网卡进行。我们想要实现跨Node的Pod之间的通信,至少需要满足下面三个条件:
1、知道Pod IP 和Node IP之间的映射关系
2、在整个集群中对Pod的IP分配不能出现冲突;
3、pod发起的数据包一层一层的正确的转发最终到达目的pod IP
那这三个条件如何实现呢?
Kubernetes会记录所有正在运行的Pod的IP分配信息,并将这些信息保存到etcd中(作为Service的Endpoint),这样我们就可以知道Pod
IP和Node IP之间的映射关系。
那既然etcd已经记录了IP地址的分配信息,那自然不会出现的重复现象了,我只会把没有分配过的地址给到新的pod。OK ,那第三条件,我们应该如何实现呢?
其实就是加了一层二次封装。后面我会以flanel插件为例详细为大家讲解 条件三的实现方式、

4、Pod与Service之间的通信:
首先Client 管理员或用户 对Service对象的创建或更改操作,后提交到API Server存储、 完成后触发各节点上的kube-proxy,
并根据代理模式的不同将其定义为相应节点上的iptables规则或ipvs规则,借此完成从Service与Pod-IP之间的报文转发
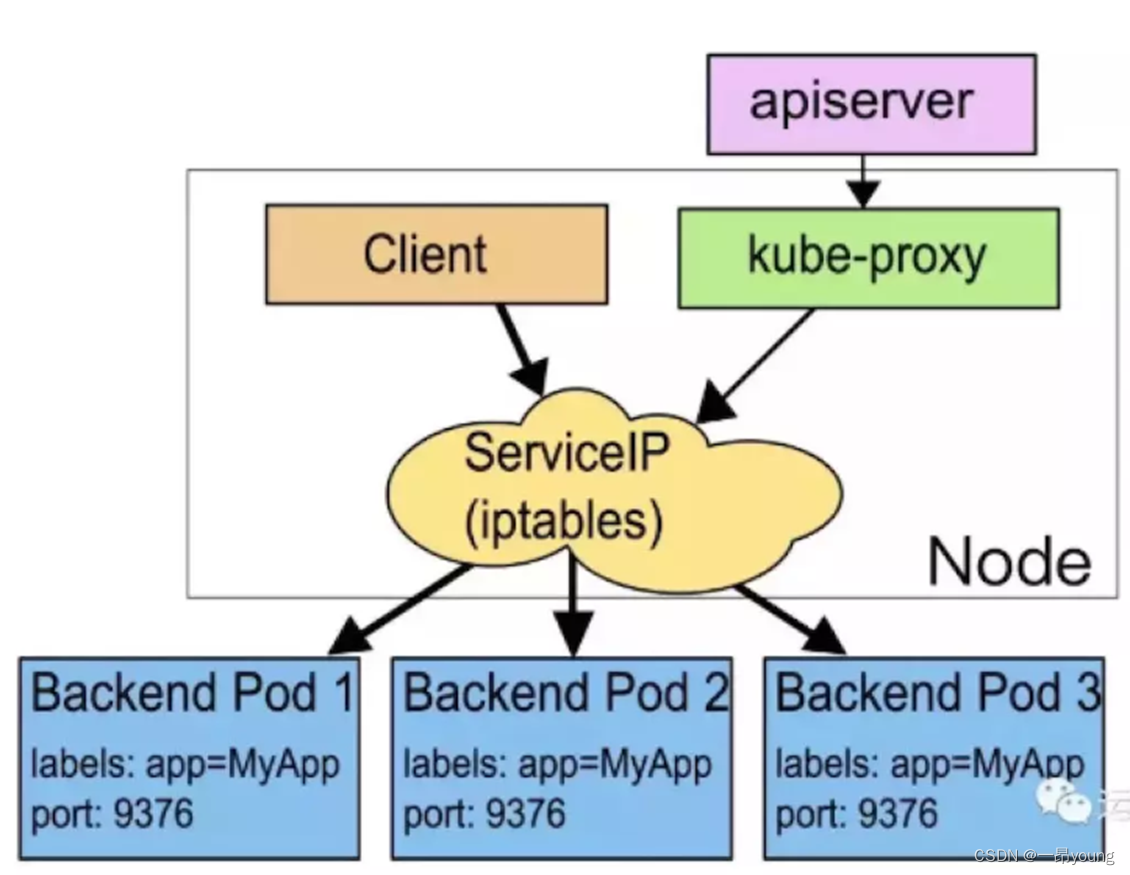
这里我们在生产环境中部署2副本的nginx deployment pod,
创建一个clusterip的service
 我们随便登陆一台node节点上查看ipvs规则,可以看到 10.244.184.123的80端口作为外部提供服务,使用轮训的负载均衡方式代理后端的 2个endpoint 10.244.1.9 和10.244.2.13的80端口
我们随便登陆一台node节点上查看ipvs规则,可以看到 10.244.184.123的80端口作为外部提供服务,使用轮训的负载均衡方式代理后端的 2个endpoint 10.244.1.9 和10.244.2.13的80端口
 那K8S网络的访问 具体是怎么实现的呢?我接下来我们讲一下 CNI
那K8S网络的访问 具体是怎么实现的呢?我接下来我们讲一下 CNI
三、网络插件CNI
Flannel插件
Flannel是Centos团队针对Kubernets设计的一个网络规划服务,简单的说,它的功能是让集群中的不同节点主机创建的Docker容器都具有全集群中唯一的虚拟IP地址,而且它还能在这些IP地址之间建立一个覆盖网络(Overlay Network),通过这个覆盖网络将数据包原封不动的传到目标容器内
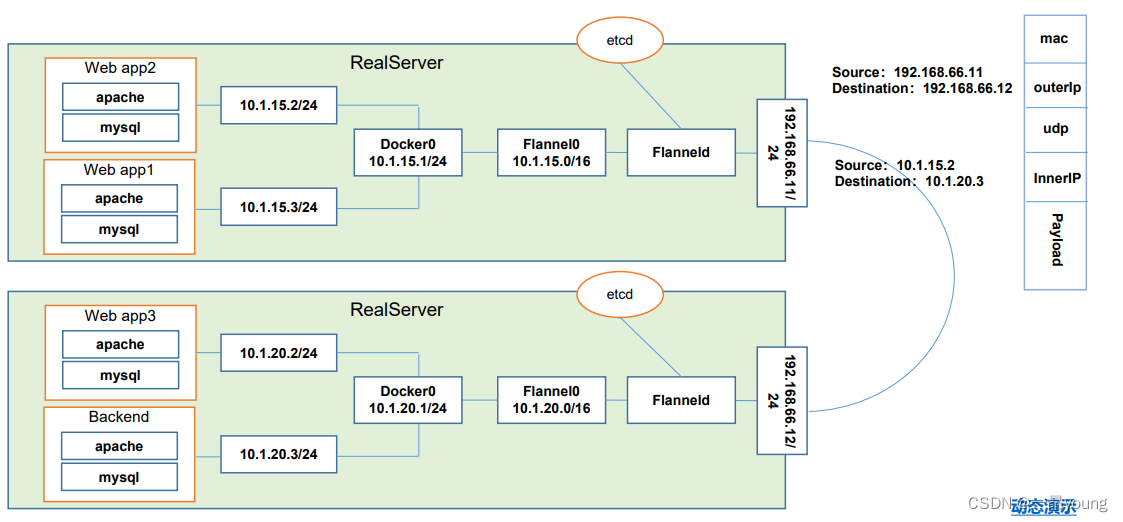
这里有两台物理机,一个是192.168.66.11 一个是12 ,那这里运行了4个pod,一个是 app1 app2 app3 前端组件 backend作为后端,那他们的结构 就 前端提交请求
向后端获取数据,好,那就意味着 web app2 想要跟 backend 通训的时候,就需要跨主机了,
1、首先flanneld作为守护进程运行在每个Node节点之上,监听端口用于接受和转发数据包,那这个flanel进程一旦启动以后会开启一个Flannel0的网桥用于收集Docker0网桥转发的数据报文
1、当请求开始后,webapp2发送数据报文的源地址为10.1.15.2,目标地址为10.1.20.3,因为目标地址与源地址不是同一个网段,于是请求报文发往Docker0网桥
2、Docker0上会有钩子函数把数据包抓到Flannel0网桥,并从etcd中获取路由表,判断数据包被发送往哪台目的机器。
3、到Flannel0网桥以后,因为flannel0是由Flanneld守护进程开启,所以数据报文被传到Flanneld后进行UDP协议封装、怎么封装呢?
有这么一个结构:
Mac地址部分,然后是下一层 源目IP,下一层是udp封装,也就意味着flanned它使用的是udp的数据报文去转发数据的!因为UDP协议不需要三次握手,更快。
下一层是内部ip,封装到这一层以后外面再加一层 数据包实体,数据包就被物理机转发到对端的物理机网卡,端口应该是flanneld的端口,所以会被flanned截获,
拆封完了以后 这个数据包线路和11宿主机的数据包线路反过来, 会转发到 flannel0 docker0 backend,并且 报文是二次解封的,docker0是看不到outerip层的数据,只能看到interip这一层信息,
所以它得到的 是 10.1.15.2的源IP发过来的 ,目标找的就是我自己 那这样的话 就可以完成了跨主机的pod访问。
其实这里的资源消耗还是比较高的,首先在flanned这里进行二次封装,解封装。这就是flanned的网络通信解决方案
Calico插件
Calico 是一套开源的网络及安全方案,用于容器和宿主机之前的网络连接,可以用在kubernetes、OpenShift等PaaS平台上。
实际上,Calico 项目提供的 BGP 网络解决方案,与 Flannel 的 host-gw 模式几乎一样。
也就是说,Calico也是基于路由表实现容器数据包转发,但不同于Flannel使用flanneld进程来维护路由信息的做法,而Calico项目使用BGP协议来自动维护整个集群的路由信息

Calico网络模型主要工作组件:
1、Felix:Felix会监听ECTD中心的存储,从它获取事件,比如说用户在这台机器上加了一个IP,或者是创建了一个容器等。用户创建pod后,Felix负责将其网卡、IP、MAC都设置好,然后在内核的路由表里面写一条,注明这个IP应该到这张网卡。同样如果用户制定了隔离策略,Felix同样会将该策略创建到ACL中,以实现隔离。
也就是说 felix主要的功能有接口管理、路由规则、ACL规则和状态报告等
2、etcd:分布式键值存储,主要负责数据一致性的数据库,存储集群中节点的所有路由信息。为保证数据的可靠和容错建议至少三个以上etcd节点
3、BGP Client(BIRD):BIRD是一个标准的路由程序,它会从内核里面获取哪一些IP的路由发生了变化,然后通过标准BGP的路由协议扩散到整个其他的宿主机上,让外界都知道这个IP在这里,你们路由的时候得到这里来,从而实现网络互通。
由于Calico是一种纯三层的实现,中间没有任何的NAT和overlay,所以它的转发效率可能是所有方案中最高的,因为它的包直接走原生TCP/IP的协议栈。
提供了一整套的防火墙的规则,所以它可以通过IPTABLES的规则达到比较复杂的隔离逻辑。
Calico插件类型之IPIP模式
从字面来理解,就是把一个IP数据包又套在一个IP包里,即把 IP 层封装到 IP 层的一个 tunnel。它的作用其实基本上就相当于一个基于IP层的网桥!
一般来说,普通的网桥是基于mac层的,根本不需 IP,而这个 ipip 则是通过两端的路由做一个 tunnel,把两个本来不通的网络通过点对点连接起来。

Calico插件类型之BGP模式
边界网关协议(Border Gateway Protocol, BGP)是互联网上一个核心的去中心化自治路由协议。它通过维护IP路由表或‘前缀’表来实现自治系统(AS)之间的可达性
全互联模式(node-to-node mesh)
全互联模式,每一个BGP Speaker都需要和其他BGP Speaker建立BGP连接,这样BGP连接总数就是N^2,如果数量过大会消耗大量连接。如果集群数量超过100台官方不建议使用此种模式。
路由反射模式Router Reflection(RR)
RR模式 中会指定一个或多个BGP Speaker为RouterReflection,它与网络中其他Speaker建立连接,每个Speaker只要与Router Reflection建立BGP就可以获得全网的路由信息。在calico中可以通过Global Peer实现RR模式。
四、网络策略
Network Policy是kubernetes中的一种资源类型,它从属于某个namespace。
两个关键部分:
-POD选择器
- 规则
网络策略包含两个关键部分,一是pod选择器,基于标签选择相同namespace下的pod,将其中定义的规则作用于选中的pod。
另一个就是规则了,就是网络流量进出pod的规则,其采用的是白名单模式,符合规则的通过,不符合规则的拒绝。


对象创建方法与其它如ReplicaSet相同。apiVersion、kind、metadata与其它类型对象含义相同
.spec.PodSelector 顾名思义,这个就是我要选择什么属性的pod。
.spec.PolicyTypes Ingress是是入pod的规则,Egress是出pod的规则。
本字段可以看作是一个开关,如果其中包含Ingress,则Ingress部分定义的规则生效,如果是Egress则Egress部分定义的规则生效,如果都包含则全部生效。如果没有指定的话,则默认Ingress生效。
例子中ingress与egress都只包含一条规则,两者都是数组,可以包含多条规则。当包含多条时,条目之间的逻辑关系是“或”,只要匹配其中一条就可以。
那我们来看看这个最终达成的效果就是:
【网段172.17.0.0/16】中 带有project: myproject标签的namesapce下的 带有 role: frontend标签的所有pod 可以正常访问default命名空间下所有带有role=db标签的pod的 6379端口,但172.17.1.0/24 不能访问
default命名空间下所有带有role=db标签的pod 可以正常访问 【10.0.0.0/24网段】下的 所有pod的 5978端口














 329
329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









