







这是我自学python以来的第一篇博文,自学python其实不难,但不可避免的也踩过很多坑,所以这里我尽量地详细介绍爬取和解析的过程,希望能给初学者带来帮助!
- 皮肤图片来源
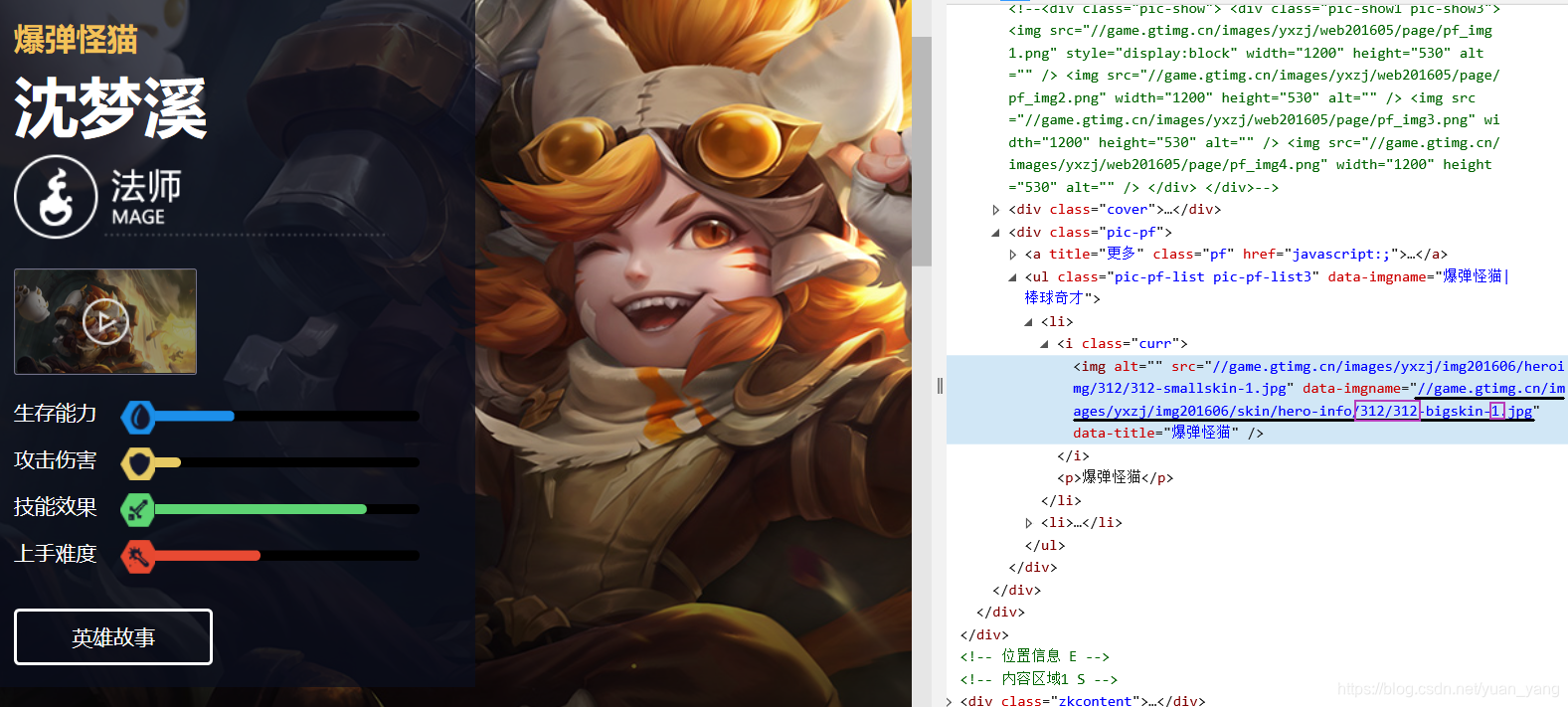
因为官网没有直接的英雄皮肤接口,所以我们这里从 http://pvp.qq.com/ 的 “英雄资料”进入所有英雄列表, 选择一个英雄(以第一个英雄 沈梦溪 为例),进去该英雄资料页面 http://pvp.qq.com/web201605/herodetail/312.shtml ,可以看到皮肤资料

- 审查元素
按F12审查皮肤元素可以看到皮肤图片地址 //game.gtimg.cn/images/yxzj/img201606/skin/hero-info/312/312-bigskin-1.jpg ,但进源码中你是看不到这个地址的,所以抓源码是不可行的。但你如果多审查几个皮肤元素,就会发现这个网址就两个变量“312”和“1”。
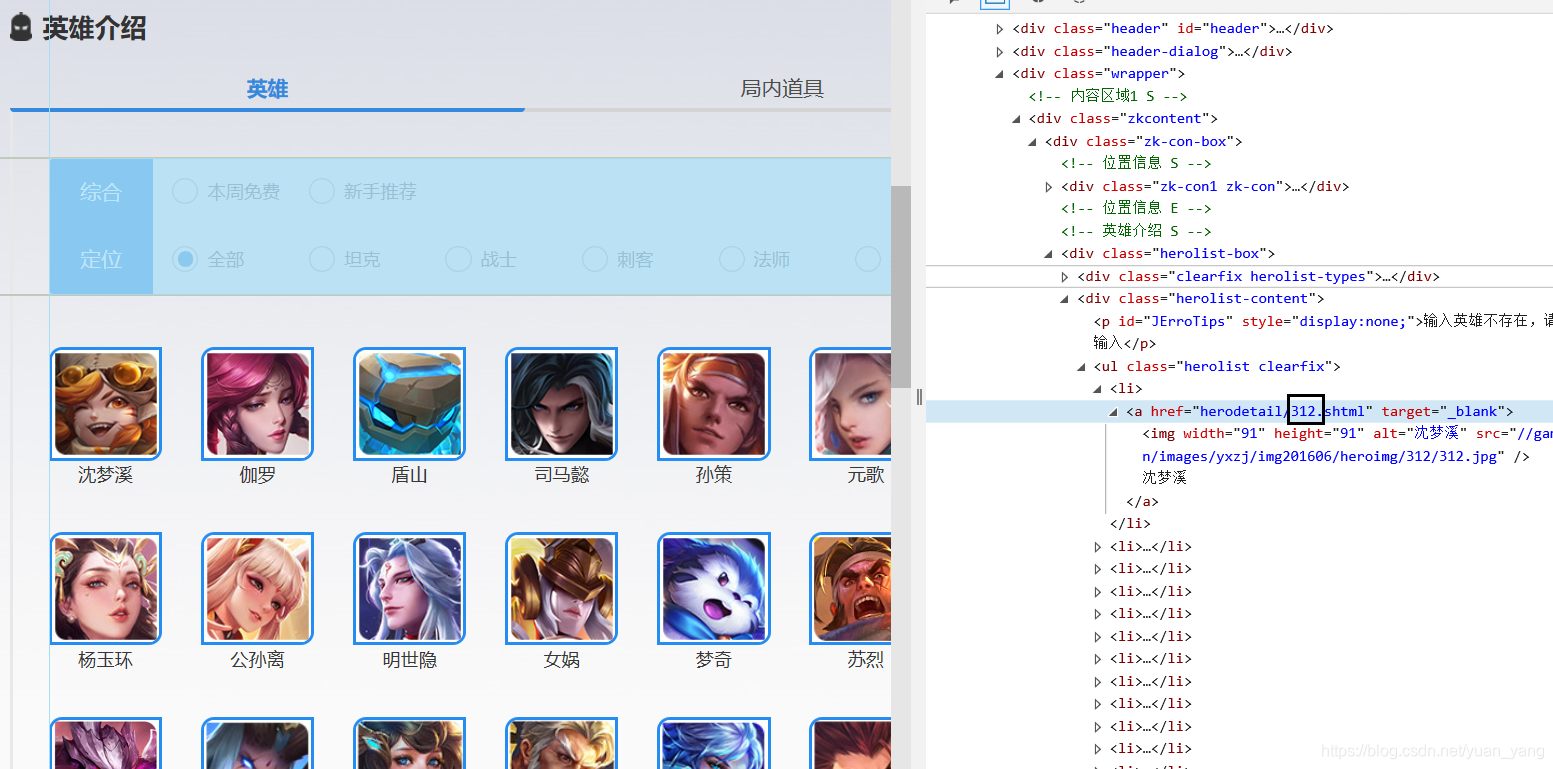
1、 “312”曾出现在该网页的url中 http://pvp.qq.com/web201605/herodetail/312.shtml ,每个英雄的url这个值是变动的,很显然,这就是英雄的id。在所有英雄列表中审查单个英雄元素,可以很轻松的看到英雄id。
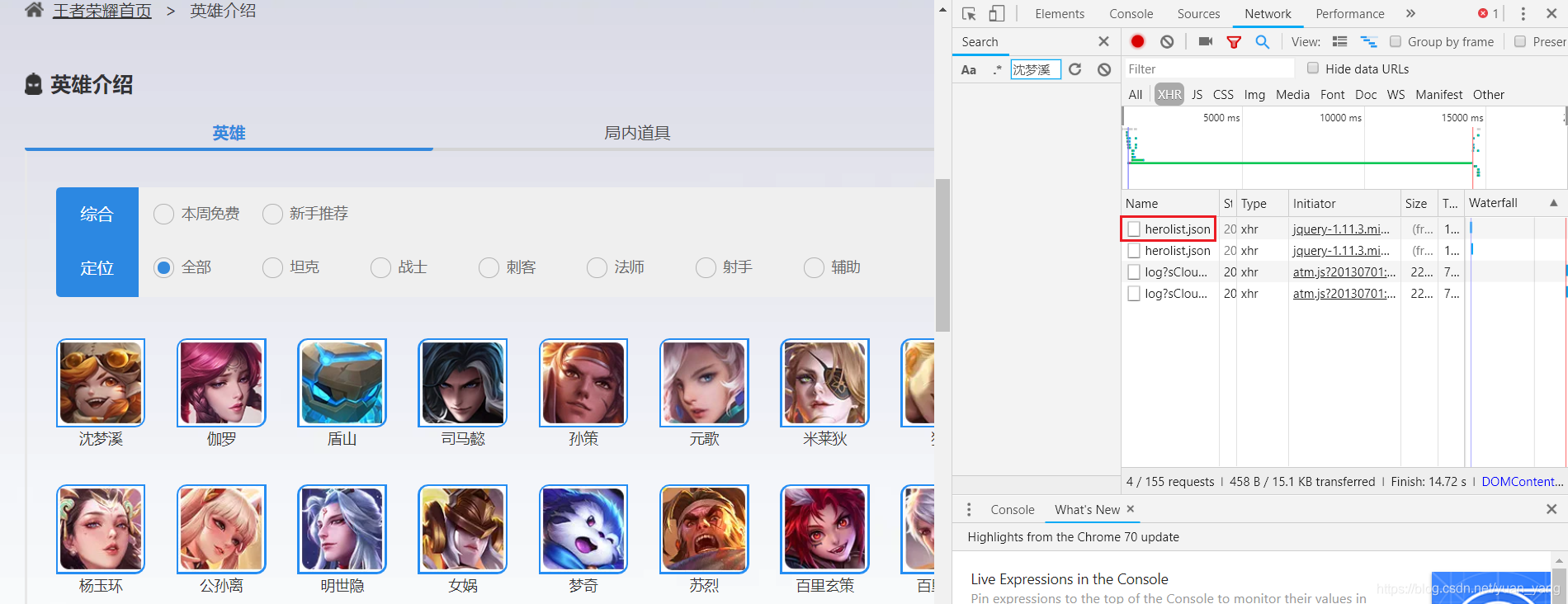
但查看源码你又会发现什么也没有,应该是后台传输的数据,所以我重新加载一下在F12的网络中找后台加载的数据,找到了herolist.json这个文件。
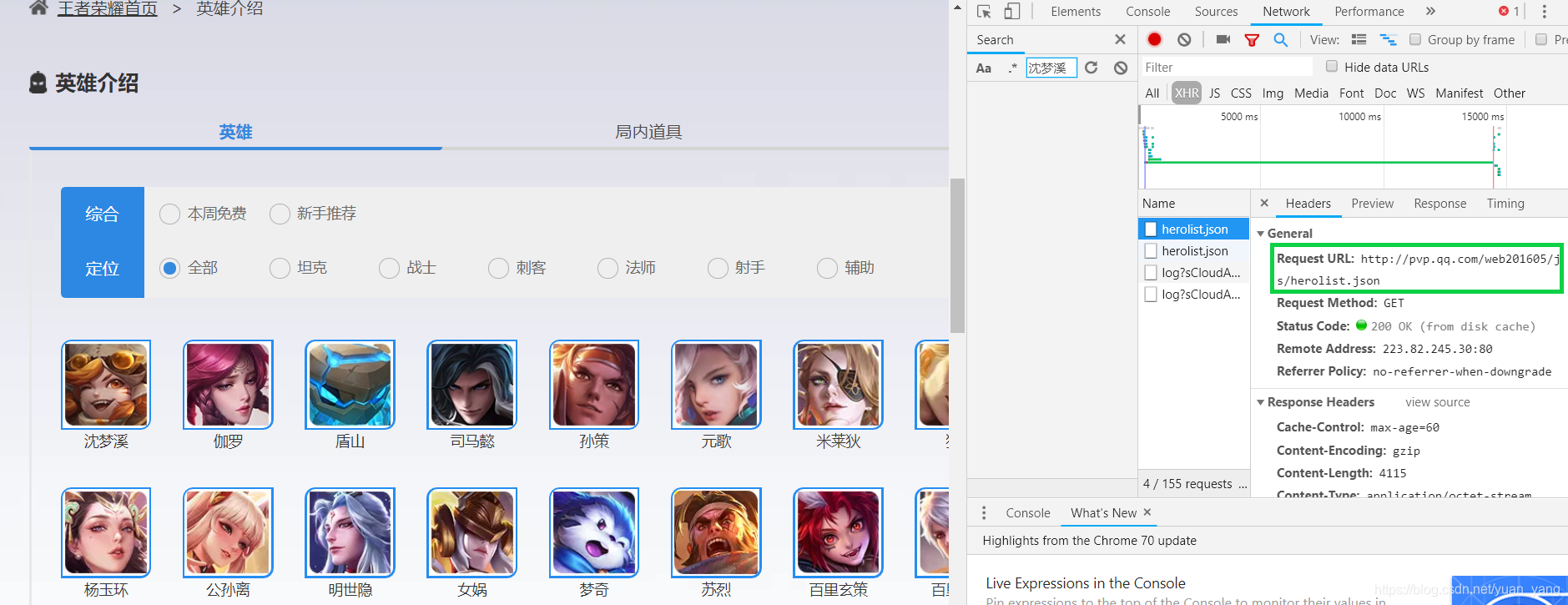
这样的文件右击在新窗口打开,会直接下载在本地,内容如下:

这里ename不难发现就是英雄id,cname是英雄,skin_name就是皮肤,我们取这三个数据即可,herolist.json的网址是 http://pvp.qq.com/web201605/js/herolist.json 。
2、沈梦溪就两个皮肤,第一个爆弹怪猫的皮肤地址 :
//game.gtimg.cn/images/yxzj/img201606/skin/hero-info/312/312-bigskin-1.jpg
第二个棒球奇才的皮肤地址:
//game.gtimg.cn/images/yxzj/img201606/skin/hero-info/312/312-bigskin-2.jpg
很明显,这里的“1”或者“2”只是皮肤的序号而已,取决于皮肤的数量,这里抓取皮肤名称即可。
- 代码逻辑
如上分析,我们思路如下:
1、获取英雄信息:从 http://pvp.qq.com/web201605/js/herolist.json 网址获取英雄名称、id、皮肤名称;
2、获取单个英雄所有皮肤:遍历皮肤名称,英雄id与皮肤序号一起组建皮肤url,发送请求,响应写入文件;
3、获取所有英雄皮肤:遍历英雄,创建文件夹。
def get_heroinfo():
pass
def save_skinimg():
pass
def main():
if not os.path.exists(os.path.join(os.getcwd(), '皮肤')):
os.mkdir('皮肤')
os.chdir('皮肤')
pass
if __name__ == "__main__":
main()
- 代码实现
1、获取英雄信息
目标:所有英雄的名称、id、皮肤名称
值得一提的是,解析内容我这里用的是正则,其实也可以用json.loads()转成字典来解析,但正则貌似比较直接。
另外,经过尝试,所有英雄页面的herolist.json不是唯一包含英雄id信息的文件,在单个英雄资料页面,后台你同样可以抓到一个名为heroid.js的文件,也包含id信息,但没有皮肤信息,如果后面图片要以皮肤名称命名的话,就还要从该网页抓取皮肤信息。
def get_heroinfo():
url = 'http://pvp.qq.com/web201605/js/herolist.json'
response = requests.get(url, headers=headers).text
# 匹配英雄信息(id,英雄名称,皮肤名称),形成元组组成的列表
hero_infos = re.findall('"ename":(\d+),"cname":"(\S+?)".*?skin_name":"(.*?)"', response)
return hero_infos
2、获取单个英雄所有皮肤
目标:写单个英雄的图片文件
第一步我们得到的是一个列表hero_infos,里面的hero_info包含一个英雄的名称、id和皮肤名称,接下来我们就拿来组建图片地址,hero_info[0]是id,hero_info[1]是英雄的名字,hero_info[2]是皮肤的名字,但这是几个皮肤名字组合在一起的字符串,格式是
"魅惑之狐|女仆咖啡|魅力维加斯|仙境爱丽丝|少女阿狸|热情桑巴"
所以这里需要切片成列表,然后遍历皮肤,计算皮肤序号num,而皮肤名称的作用仅仅是用来命名的。所以如果你没有命名要求,完全可以不抓取它,妲己的皮肤已经算多的了,我们完全可以从1遍历到10(有10个皮肤的英雄吗……),用try……except来结束异常的遍历,图片命名直接取链接切片后的.jpg部分,这样无疑更省事(八大浪费之加工过剩浪费……),所以代码都是根据需求来写的。
def save_skinimg(hero_info):
num = 1
# 处理皮肤名称中的“|”
skin_names = hero_info[2].split('|')
for skin in skin_names:
url = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{}/{}-bigskin-{}.jpg'.format(hero_info[0], hero_info[0], num)
num += 1
response = requests.get(url, headers=headers).content
filename = '{}-{}.jpg'.format(hero_info[1], skin)
print('正在下载 {}……'.format(filename))
with open(filename, 'wb') as f:
f.write(response)
3、获取所有英雄皮肤
目标:主函数……创建文件的保存路径,遍历所有英雄
调用前面两函数,实现所有英雄的皮肤下载
def main():
if not os.path.exists(os.path.join(os.getcwd(), '皮肤')):
os.mkdir('皮肤')
os.chdir('皮肤')
# 获取英雄信息(id,英雄名称,皮肤名称)
hero_infos = get_heroinfo()
for hero_info in hero_infos:
# 打开图片链接并保存图片
save_skinimg(hero_info)
- 代码总览
好了,代码基本上就这样,整合在一起看看
import requests, re, os
from lxml import etree
def get_heroinfo():
url = 'http://pvp.qq.com/web201605/js/herolist.json'
response = requests.get(url, headers=headers).text
# 匹配英雄信息(id,英雄名称,皮肤名称),形成元组组成的列表
hero_infos = re.findall('"ename":(\d+),"cname":"(\S+?)".*?skin_name":"(.*?)"', response)
return hero_infos
def save_skinimg(hero_info):
num = 1
# 处理皮肤名称中的“|”
skin_names = hero_info[2].split('|')
for skin in skin_names:
url = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{}/{}-bigskin-{}.jpg'.format(hero_info[0], hero_info[0], num)
num += 1
response = requests.get(url, headers=headers).content
filename = '{}-{}.jpg'.format(hero_info[1], skin)
print('正在下载 {}……'.format(filename))
with open(filename, 'wb') as f:
f.write(response)
def main():
if not os.path.exists(os.path.join(os.getcwd(), '皮肤')):
os.mkdir('皮肤')
os.chdir('皮肤')
# 获取英雄信息(id,英雄名称,皮肤名称)
hero_infos = get_heroinfo()
for hero_info in hero_infos:
# 打开图片链接并保存图片
save_skinimg(hero_info)
if __name__ == "__main__":
headers = {'User-Agent': 'Opera/9.27 (Windows NT 5.2; U; zh-cn)'}
main()
总共36行,含注释和空行,代码很简单,关键就是抓这个json!
ok,最后附上一段它的姊妹篇 - 王者荣耀高清壁纸下载,因为没抓到后台数据,所以只能用selenium+Chrome,这里用了递归。
from selenium import webdriver
from lxml import etree
import time, requests, os
def get_imglink():
global i
time.sleep(3)
content = driver.page_source
html = etree.HTML(content)
links = html.xpath('//div[@id="Work_List_Container_267733"]//li[@class="sProdImgDown sProdImgL6"]/a/@href')
print('正在获取第 %d 壁纸link列表……' % i)
for link in links:
response = requests.get(link, headers=headers)
time.sleep(1)
filename = link.split('/')[-2]
with open(filename, 'wb') as f:
f.write(response.content)
driver.find_element_by_xpath('//a[@href="javascript:Work_267733.Page(1,0);"] | //a[@href="javascript:Work_267733.Page(1, 0);"]').click()
driver.switch_to.default_content()
i += 1
try:
get_imglink()
except Exception as e:
print(e)
driver.close()
driver = webdriver.Chrome()
imglinks = []
start_url = 'http://pvp.qq.com/web201605/wallpaper.shtml###'
driver.get(start_url)
i = 1
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; PPC Mac OS X; U; en) Opera 8.0',
'Referer':'http://pvp.qq.com/web201605/wallpap'}
if not os.path.exists(os.path.join(os.getcwd(), '壁纸')):
os.mkdir('壁纸')
os.chdir('壁纸')
get_imglink()
- 效果展示
壁纸好多就是皮肤来着,腾讯好偷懒……
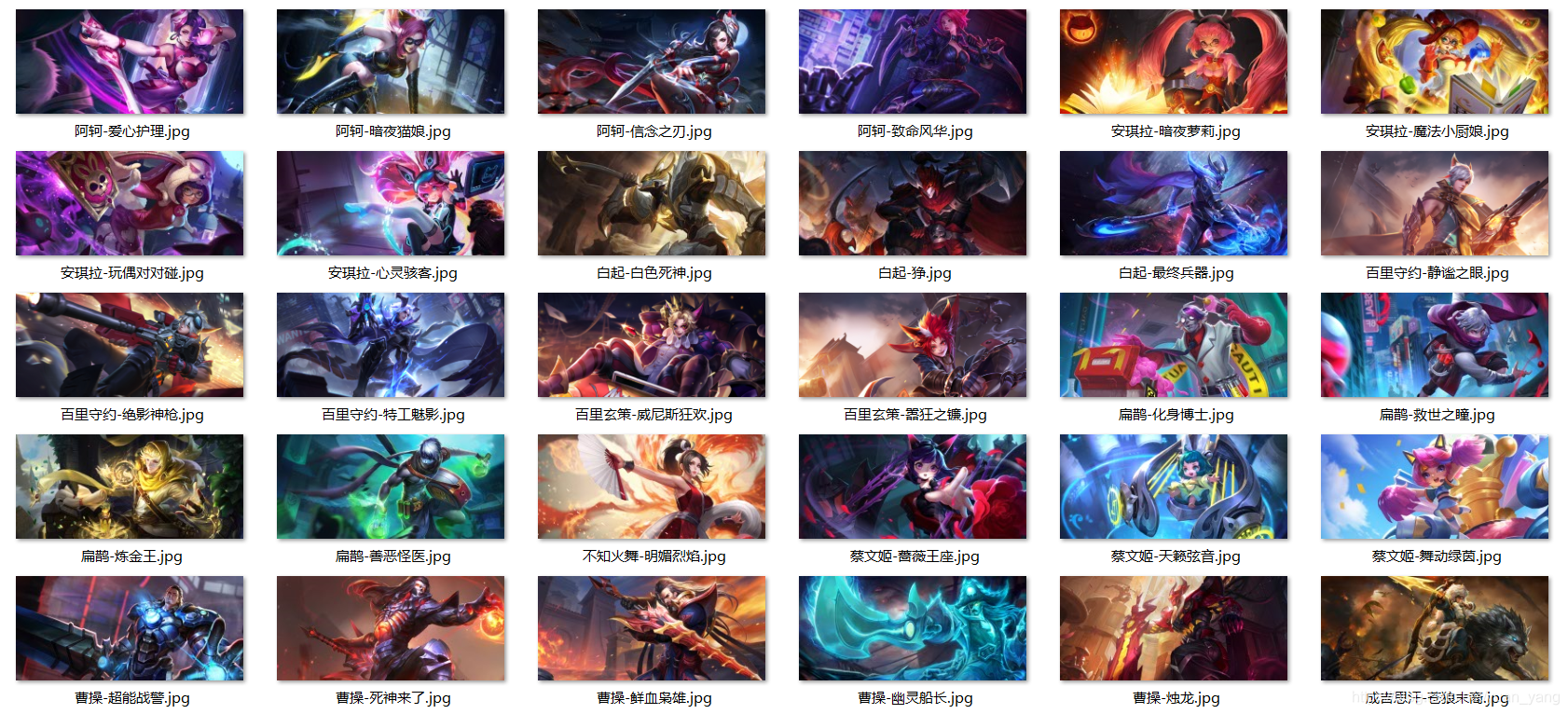

^ _ ^ 对于文章和代码,有什么问题或建议,欢迎与我联系,谢谢~

















 741
741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}