






Spark3源码在IDEA中编译
之前可以在linux环境进行spark源码的修改和编译,没有在笔记本上走通过编译流程,今天使用使用IDEA版本是社区版2021.1.1编译源码,记录遇到的问题和解决方案。
-
下载Spark3的源码,直接下载master分支代码或spark 3.1.1 tag源码zip包,解压。
-
使用IDEA“Open”spark源码文件夹,等待自动识别为
Maven项目并加载完毕。 -
开始编译前,在MAVEN Profiles选择必要的模块:hadoop、hive、hive-thriftserver、kubernetes、sparkr、yarn
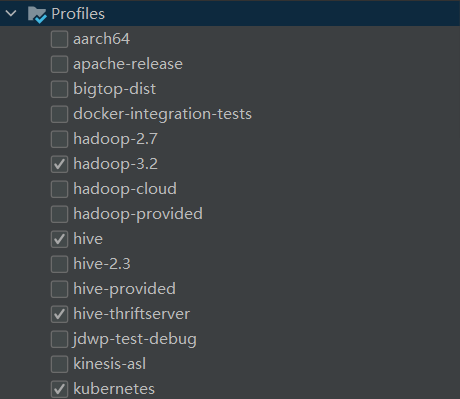
-
从MAVEN窗口工程列表找到root的Spark Project Parent POM开始
clean package:编译到Spark Core模块时遇到第一个错误:Cannot run program "bash": CreateProcess error=2, 系统找不到指定的文件。这个是本地Windows环境不能执行bash导致的,需要本机安装Git工具(IDEA也可以直接安装,默认位置是C:\Program Files\Git),将这个C:\Program Files\Git\bin路径添加到系统环境变量Path中,然后重启电脑就可以解决。 -
直接按照官网提示设置
MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=1g"环境变量,会提示参数无效,无法启动JVM。 -
继续编译遇到提示:
CodeCache is full. Compiler has been disabled.Try increasing the code cache size using -XX:ReservedCodeCacheSize=,应该跟第5步不设置导致的。解决办法: 工程右上角“Add/Edit Configurations”->在弹出的"Add New Configuration"列表中选择"maven",在Runner选项卡添加虚拟机选项:-Xmx2g -XX:ReservedCodeCacheSize=1g(在这设置也是无效的!)。
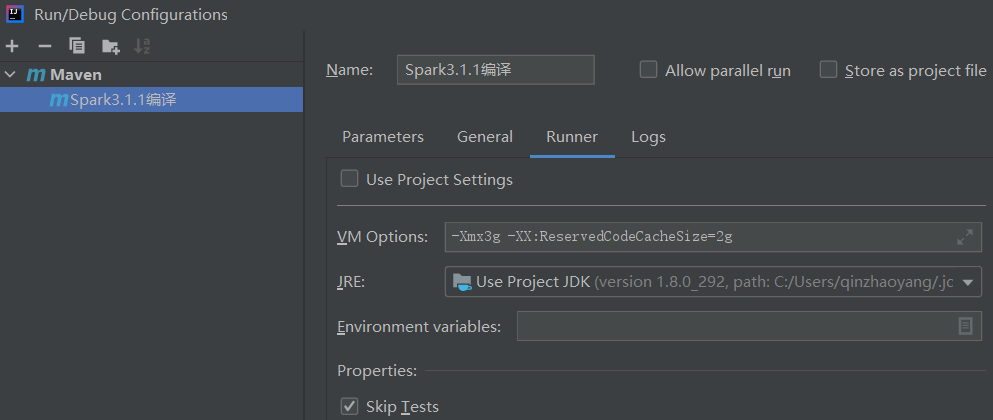
末尾还是有警告,不过不影响编译:CodeCache is full. Compiler has been disabled.
OpenJDK 64-Bit Server VM warning: Try increasing the code cache size using -XX:ReservedCodeCacheSize=

最终在Scala Compile Server增加设置-XX:ReservedCodeCacheSize=1g:

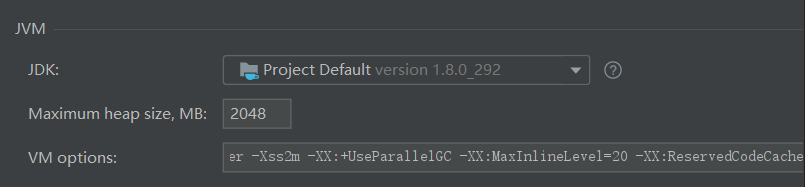
- 全部编译成功。(如遇到jar下载中断、网络连接失败等依赖问题,无需理会,重新clean、package即可)
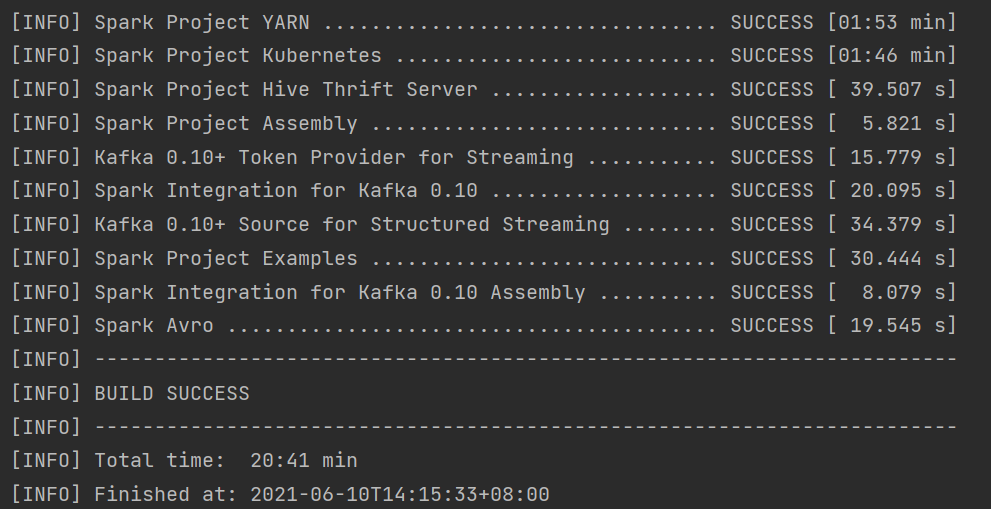
点:Spark源码编译、IDEA、Spark3
线:Spark
面:内存计算
















 1368
1368











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











