







1.准备文件
join1目录下放入文件内容
key0 value1_
key1 value1_a
key2 value1_b
key3 value1_c
key4 value1_d
join2目录下放入文件内容
key1 value2_a
key2 value2_b
key3 value2_c
key5 value2_e
2.实现效果是关联两个表。
代码:
package test;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.KeyValueTextInputFormat;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.hadoop.mapred.join.CompositeInputFormat;
import org.apache.hadoop.mapred.join.TupleWritable;
import org.apache.hadoop.mapreduce.lib.input.KeyValueLineRecordReader;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class TestJoin extends Configured implements Tool {
static int printUsage() {
System.out.println("join" +
"[input]* <input> <output>");
ToolRunner.printGenericCommandUsage(System.out);
return -1;
}
public int run(String[] args) throws Exception {
JobConf jobConf = new JobConf(getConf(), TestJoin.class);
jobConf.setJobName("join");
<span style="color:#ff0000;"> jobConf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, " "); // 使用空格分割</span>
jobConf.setMapperClass(MapClass.class);
jobConf.setReducerClass(ReduceClass.class);
<span style="color:#ff0000;">String op = "outer"; //inner outer override tbl 使用outer</span>
List<String> otherArgs = new ArrayList<String>();
for(int i=0; i < args.length; ++i) {
otherArgs.add(args[i]);
}
FileOutputFormat.setOutputPath(jobConf, new Path(otherArgs.remove(otherArgs.size() - 1)));
List<Path> plist = new ArrayList<Path>(otherArgs.size());
for (String s : otherArgs) {
plist.add(new Path(s));
}
jobConf.setInputFormat(CompositeInputFormat.class);
jobConf.set("mapred.join.expr", CompositeInputFormat.compose(
op, <span style="color:#ff0000;">KeyValueTextInputFormat</span>.class, plist.toArray(new Path[0]))); //使用key value 读入
jobConf.setOutputFormat(TextOutputFormat.class);
jobConf.setOutputKeyClass(Text.class);
jobConf.setOutputValueClass(TupleWritable.class);
JobClient.runJob(jobConf);
return 0;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new TestJoin(), args);
System.exit(res);
}
public static class MapClass extends MapReduceBase implements
Mapper<Text, TupleWritable, Text, TupleWritable> {
public void map(Text key, TupleWritable value,
OutputCollector<Text, TupleWritable> output, Reporter reporter)
throws IOException {
output.collect(key, value);
}
}
public static class ReduceClass extends MapReduceBase implements
Reducer<Text, TupleWritable, Text, Text> {
@Override
public void reduce(Text key, Iterator<TupleWritable> values,
OutputCollector<Text, Text> output, Reporter reporter)
throws IOException {
while (values.hasNext()) {
TupleWritable val = values.next();
Writable a = val.get(0);
System.out.println("val===0====" + a);
String av = "-";
if(a != null){
av = a.toString();
}
Writable b = val.get(1);
System.out.println("val===1====" + b);
String bv = "-";
if(b != null){
bv = b.toString();
}
output.collect(key, new Text(av + " " + bv));
}
}
}
}
4.执行命令携带参数 hdfs://cdh1:8020/user/hdfs/join1 hdfs://cdh1:8020/user/hdfs/join2 hdfs://cdh1:8020/user/hdfs/joinoutput 前两个是输入目录,最后一个是输入目录
5.输出结果:
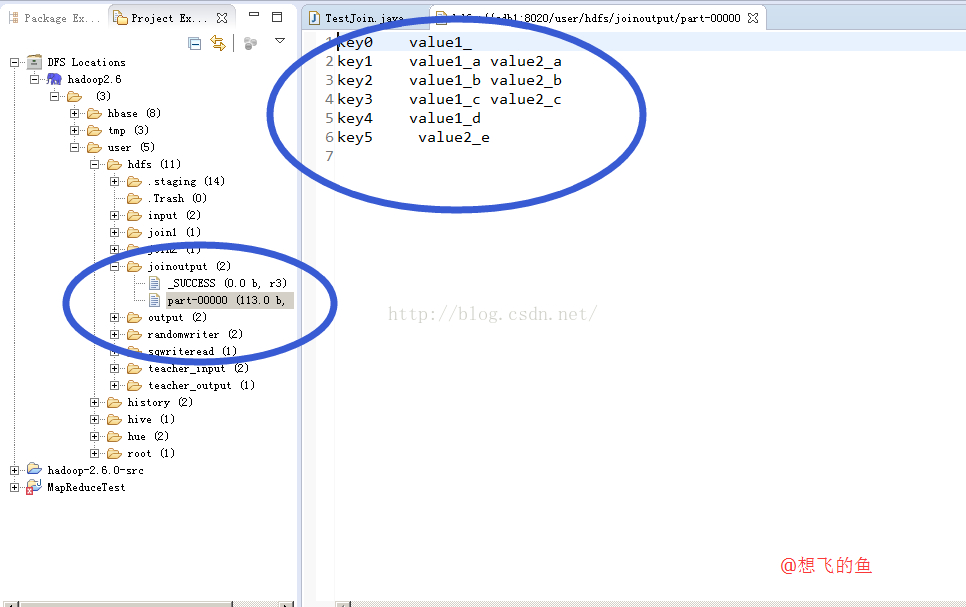















 186
186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









