







本节主要是参考了别人的构建方案,然后自己配置的时候优化了一下。
安装过程主要有以下几个步骤:
一、建立hadoop运行帐号
分别运行下面命令
sudo groupadd hadoop 创建用户组
sudo useradd hadoop -g hadoop 创建用户
cd /home/ 切换用户目录
sudo mkdir hadoop/ 创建hadoop目录
sudo chown -R hadoop:hadoop hadoop/ 设置目录的所有者为hadoop用户
执行完上面,运行帐号的建立就完成了
二、安装虚拟机jdk
这里安装的版本是:jdk-8u72-linux-x64.gz
上传文件方式两种:FTP和rz/sz上传和下载工具
sudo apt-get install lrzsz 开启rz/sz上传下载功能,用rz选择文件上传至linux
sudo tar -zxvf jdk-8u72-linux-x64.gz -C /opt/ 命令将其解压到/opt目录下
sudo mv jdk1.8.0_72 java文件夹重命名为java
配置环境变量了,使用vi /etc/profile命令编辑添加如下内容:
export JAVA_HOME=/opt/java/
export PATH=$JAVA_HOME/bin:$PATH
配置好之后要用命令source /etc/profile使配置文件生效
使用命令sudo chown -R hadoop:hadoop java/将所有者设置为hadoop
这样jdk就安装完毕了,检查jdk环境变量是否配置正确,输入java -version,如下图,则安装配置成功

二、hadoop的安装
下载hadoop-2.6.3.tar.gz,点击下载
先解压到hadoop目录下,sudo tar -zxvf hadoop-2.6.3.tar.gz -C /home/hadoop/
然后设置所有者,sudo chown -R hadoop:hadoop hadoop-2.6.3/
再vi /etc/profile配置环境变量
新增:export HADOOP_HOME=/home/hadoop/hadoop-2.6.3
修改:export PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin
使用source /etc/profile使配置生效。安装方法和jdk类似。
三、配置hadoop-2.6.3
cd etc/hadoop/
配置 hadoop-env.sh文件-->修改JAVA_HOME
export JAVA_HOME=/home/java/
配置 yarn-env.sh 文件-->>修改JAVA_HOME
export JAVA_HOME=/home/java/
配置slaves文件-->>增加slave节点
slave1
slave2
配置 core-site.xml文件-->>增加hadoop核心配置(hdfs文件端口是9000、file:/home/spark/opt/hadoop-2.6.0/tmp、)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property><span style="white-space:pre"> </span><!--指定hadoop的工作目录 -->
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop-2.6.3/tmp</value>
<description>Abasefor other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.spark.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.spark.groups</name>
<value>*</value>
</property>
</configuration>配置 hdfs-site.xml 文件-->>增加hdfs配置信息(namenode、datanode端口和目录位置)
<configuration>
<pre name="code" class="html" style="font-size: 13.3333px;"><!--指定<span style="font-size: 13.3333px; font-family: Arial, Helvetica, sans-serif;">secondnamenode,建议和master不在一个机器保证数据安全</span> -->
<property> <name>dfs.namenode.secondary.http-address</name> <value>slave1:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop/hadoop-2.6.3/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop/hadoop-2.6.3/dfs/data</value> </property> <property>
<pre name="code" class="html" style="font-size: 13.3333px;"><!--设置datanode的数量,除了master以外-->
<name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property></configuration>配置 mapred-site.xml 文件-->>增加mapreduce配置(使用yarn框架、jobhistory使用地址以及web地址)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>配置方面到这里先结束。
三、克隆虚拟机
关闭"VMware Workstation上面的master虚拟机。
然后右键这个虚拟机-->管理-->克隆

一直下一步,到下图位置停下来,选择“创建完整克隆”

这里名称选择slave1,点击完成后,重新再重复一遍复制一个slave2

克隆好之后,分别进入机器,重命名机器名。因为是克隆的,默认的名字都会和原来的名字一样。
vim /etc/hostname 分别命名机器为slave1,slave2
使用ifconfig 查看3太机器的ip地址,然后分别在三台机器下配置hosts文件

hosts文件路径为;/etc/hosts,我的hosts文件配置如下,大家可以参考自己的IP地址以及相应的主机名完成配置

至此,3台服务器都准备好了。
四、格式化namenode
格式化namenode:进入master主机的hadoop-2.6.3目录下:./bin/hdfs namenode -format,出现如下界面基本完成

五、启动hadoop
这一步也在主结点master上进行操作:
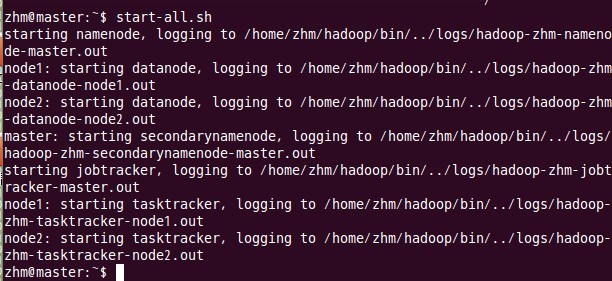
六、 用jps检验各后台进程是否成功启动
在主结点master上查看namenode,jobtracker,secondarynamenode进程是否启动。

如果出现以上进程则表示正确。
不出现则:ufw disable 关闭防火墙
如果jps指令输入后
七、 通过网站查看集群情况
在浏览器中输入:http://192.168.23.128:8088/,网址为master结点所对应的IP:

在浏览器中输入:http://192.168.1.100:50070,网址为master结点所对应的IP:

至此,hadoop2.6.3的完全分布式集群安装已经全部完成,
















 4116
4116











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











