






方法一:
在计算图的构建中,把图像增强的方法应用到x_image中去;
方法二:
在feed_dict传入图像之前,将图像从一维向量变为三维向量,即在feed_dict之前就将图像做处理;


*本文使用方法一:
1.修改输入:
将:

改为:
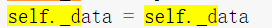
将:
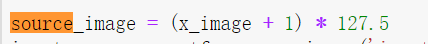
改为:

将:
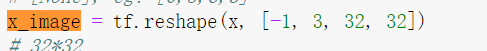
因为x_image已经是一个四维的向量,所以就不需要再reshape了
2.处理cifar10样本的三种技术:
(1)随机翻转:

(2)光照:

(3)对比度:
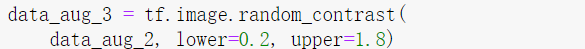
3.将图像增强后的效果加到模型中去:
因为api要求必须是三维的(即一张图像)图像,而我们的图像是四维的(即很多张),所以要将这些图像一张一张做拆分,然后在单个的图像上做图像增强,然后再把单个的图像合并起来(即还是变成一个minibatch):
(1)将batchsize的定义挪到上面去,j再将x,y里的none改成batchsize:
原:

现:

(2)这样x就可以进行切分了:

(3)设置一个数组来保留切分后的结果:

(4)对x中的每个图像都做这个数据增强:

(5)合并数组,将reshape再变回来:

把初始后的结果添加到列表中去:

再把最后的列表合并成minibatch:

(6)对这个minibatch做归一化:


以上就可以打印出来了经过图像增强后的一个结果
4.训练效果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









