







偶尔看到http协议中用到base64编码,了解一下,记录一下
编码
1.既然说到编码,那就要说一下什么是编码?
简单说编码就是一个字符集到另一个字符集的映射关系。
比如规定了1,2,3,4四个数字到A,B,C,D的一一映射关系,那么就可以在编码时把这四个数字替换为对应的字母,在解码是做一个反向的映射替换。
2.为什么要编码?
按照存在即合理的思路这种问题基本是废话。既然要从一种字符集变换到另一种字符集,那么就说明新的字符集肯定在某种情况下更满足人们的需求。
举最常见的例子来说:计算机使用的是二进制,在硬件层次来说及其处理的数据都是以0和1来表示的,那网络上展示的各种资源(比如这些文字)是怎么存储的呢,编码转换!可见的这些字符转换成01二进制串。这是信息载体的限制。
再举个栗子:英语到汉语的翻译,语义是一致的,由汉语字符集转换到英语字符集,这也是信息载体的限制。
除此之外,有些时候为了提高信息传输的效率会对信息进行编码,常见的是各种音视频的压缩编码。
校验码:(以下引自百度百科)代码作为数据在向计算机或其它设备进行输入时,容易产生输入错误,为了减少输入错误,编码专家发明了各种校验检错方法,并依据这些方法设置了校验码
加密:明文到密文的映射。
文本协议、二进制协议
再回来说http用到的base64编码,按照上面说到的既然用了base64编码,那肯定是有原因的?在找到原因之前,先了解这两个概念。
文本协议和二进制协议
首先说http是一种文本协议,此外xml也是一种文本协议,我们使用的各种编程语言也可以理解为一种文本协议,甚至于我们正常使用各种语言文字也可以理解为文本协议。在我们掌握了协议的基本的语法语义规则后,给我们一段遵守协议规范的文本,我们就可以理解文本表达的意义。其实文本协议更多的是一种相对的概念,相对二进制协议来说,如果我们都能以二进制机器的思维来思考,这种相对性也就不那么明显了,大家都能直接看懂二进制,又何必费劲让机器再转成文本了呢,直接跟机器用二进制交流得了。
好吧,因为二进制相对我们人类的思维来说实在是太非人类了,为了让人能更好的理解交互内容,文本协议诞生了。
也正因为文本协议一般是面向人的,所以一般文本协议都是高层协议,而二进制协议一般则比较偏向底层,用于机器的交互(这里的一般是因为实在不清楚是不是有什么特例)。
最常见的就是http协议和tcp协议了,从报文格式上就可以看出来,tcp报文格式可以参考Tcp/IP协议详解,一般通讯类的教材也会有介绍,报文头,标志位,字段长度,控制,校验····头大,真不是给人看的。下面看一段http报文。
拿到一段http报文
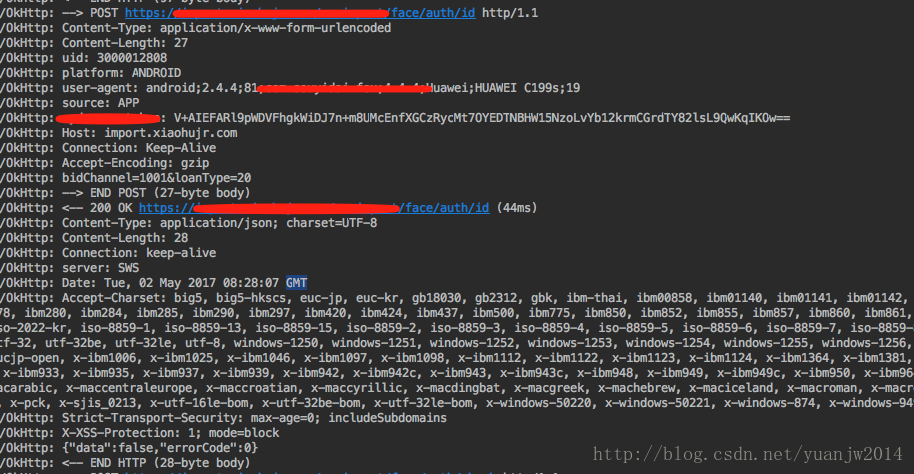
根据http报文语法,我可以知道这是以post方式去请求服务端的某一个接口,传递了那些参数,设置了那些header;我的请求是成功了还是失败了,服务端又返回了什么结果;如果是一堆二进制01的话,想知道这些就不是掌握http协议语法那么简单了。
扯这多,一句话就是文本协议是给人看的,二进制协议是给机器用的。
既然已经扯了这么多,不妨扯远点,既然是文本协议,那就是由可见文本构成的,所有可见文本必定是由有限字符集来表示。
http字符集与字符编码
http协议是用人类可读字符来表示的,但是协议报文是在网络上传输,使用的机器,必然在传输过程中要转换成二进制形式,传到对面二进制又要转成文本供给对方阅读。这就需要编码和解码。
那么问题来了:如果所有人使用的都是一套字符集,是不存在困难的,字符集跟二进制一一对应,同一套规则。问题在于,中国人用汉字,英国人用字母,日本人的平假名片假名,还有什么谚文,各种文字,现实世界的翻译问题在机器中依然存在。二进制在转回文字的时候应该采用哪一套规则(一套规则就对应一套字符集和编码)?
解决这个问题需要通讯双方的约定,这也就是协议需要解决的问题。http给出了Accept-Charset/Accept-Encoding/Accept-Language/Content-Type/Content-Encoding/Content-Language这些header来供双方约定使用的字符集,编码方式和语言。Accept-用于告诉对方我能识别的字符集和字符编码,我不认识的你不要发给我,发给我我也看不懂;Content-用于告诉对方我发给你的内容使用了什么字符集和字符编码,你按这个来解码。
在上面的http报文中我们可以看到返回报文 Content-Type的设置
"application/json; charset=utf-8"这里就指明了字符集类型utf-8
双方要交互就要求至少有一方要掌握对方的“语言”,这实在是非人道的,相信大部分需要学习英语的人都有这种想法。那有么有一种语言大家都去用它,其实英语作为国际通用语就承担了这种功能,那么字符集界是否也能有一种类似的扛把子存在呢?
“Unicode编码系统为表达任意语言的任意字符而设计。它使用4字节的数字来表达每个字母、符号,或者表意文字(ideograph)。每个数字代表唯一的至少在某种语言中使用的符号。(并不是所有的数字都用上了,但是总数已经超过了65535,所以2个字节的数字是不够用的。)被几种语言共用的字符通常使用相同的数字来编码,除非存在一个在理的语源学(etymological)理由使不这样做。不考虑这种情况的话,每个字符对应一个数字,每个数字对应一个字符。即不存在二义性。不再需要记录”模式”了。U+0041总是代表’A’,即使这种语言没有’A’这个字符。”
这段摘自参考文献对字符集的介绍。好了包罗万象,大家都用这个就好,皆大欢喜。
扯这么多貌似跟Base64没有毛关系,Base64又是为了解决什么问题的呢?
先看一下Base64用在什么地方。
前面说unicode编码解决了不同语言字符集的兼容问题,这是文本的编码问题,但是我们使用http也会传输一些图片等二进制的文件,这些是非文本的,在http协议报文里怎么表示这些文件呢?一种解决方式就是把二进制数据用文本来表示。Base64 就是一种能够把二进制数据表示成文本形式的编码方式。
字符集
标准Base64的字符集是ASCII字符集的一个子集,包含64个字符
A-Za-z0-9+/
如果使用二级制表示的话需要满足2^n=64,n=6,正好需要6位。
内存中数据是按字节存储的,一字节8bit,二进制数据怎么映射字符集?
映射关系
为了保证二进制数据完整映射到base64字符集,取6和8的最小公约数24(3*8=4*6).每24位为一组进行映射。24位分成四组,每组高位补0到8位,以在计算机中表示。
不足24位的情况先用0补足到6的整数倍,映射成字符,不足四个字符用=补足字符位数。
解码时每四个字符为一组,去掉字符=,映射到二进制,去掉高位补0,保证8的整数倍,如必要(不是8的整数倍)截尾
思路就是这样














 212
212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









