







 Pointview-GCN是一种新型3D形状分类方法,它利用多级图卷积网络从不同视角的部分点云中聚合形状特征。该方法不仅能够有效编码物体的几何信息,还能捕捉多视角之间的关系,实现fine-to-coarse级别的特征聚合。
Pointview-GCN是一种新型3D形状分类方法,它利用多级图卷积网络从不同视角的部分点云中聚合形状特征。该方法不仅能够有效编码物体的几何信息,还能捕捉多视角之间的关系,实现fine-to-coarse级别的特征聚合。
Pointview-GCN: 3D Shape Classification With Multi-View Point Clouds
摘要
- 绕着物体从多个视点捕获部分点云进行3D shape classification
- Pointview-GCN具有multi-level的Graph Convolutional Networks (GCNs),以fine-to-coarse的方式聚合单个视角点云的形状特征,从而达到对物体的几何信息和多视角关系进行编码的目的
- 代码详见:https://github.com/SMohammadi89/PointView-GCN PyTorch版本
1.引言
- 现实生活中捕获到的点云数据都是从不同视角下获得的部分点云
- Graph Convolutional Networks (GCNs)证明了其在多视角下对语义关系编码进行特征聚合的强大能力
- Pointview-GCN提出了一个具有multi-level GCNs的网络,从多个视图的部分点云中聚合形状特征,以fine-to-coarse的方式挖掘相邻视图中的语义关系
- 在不同层的GCNs间加入skip connection
- 提出了一个新的数据集,该数据集包含单个视角的点云数据
2.相关工作
MVCNN使用max-pooling从不同的视图中聚合特征,最终得到一个全局形状descriptor,缺点是 没有考虑多视图数据之间的语义关系。
View-GCN提出了一个基于view的图卷积网络,在数据中捕获结构关系,但是以上方法都是在图像上聚合特征。
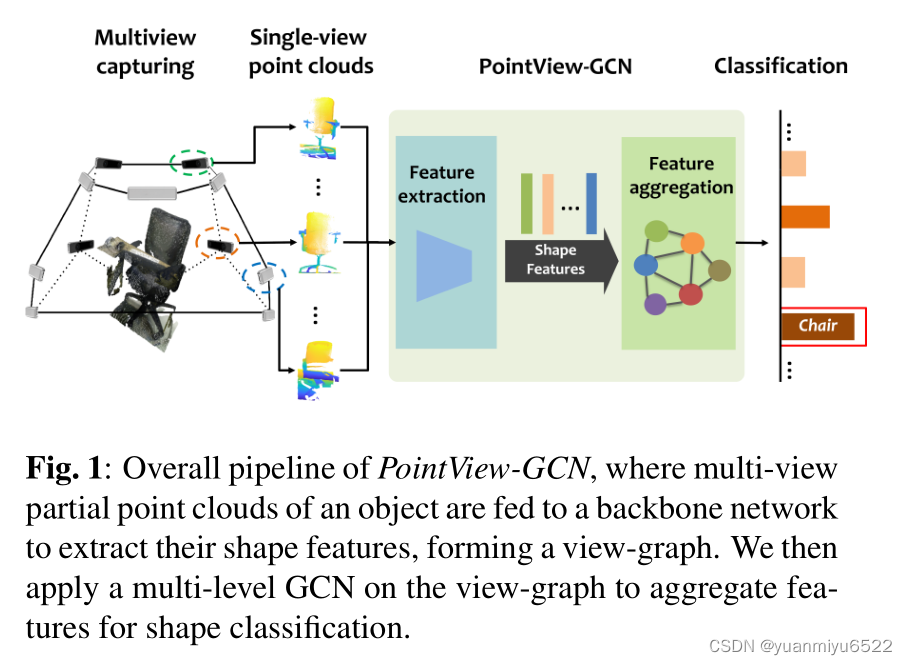
3.方法
- 首先从物体的不同视角下拍摄多个部分点数据
- 利用backbone提取每个部分点云的特征
- 创建一个带有 N N N个节点的图 G = { v i } i ∈ N G=\left\{ {v_i} \right\}_{i \in N} G={vi}i∈N,通过第 i i i个单视角点云数据的形状特征 F i F_i Fi表示节点 v i v_i vi,其中 F = { F i } i ∈ N \mathbf{F}=\left\{ {F_i} \right\}_{i \in N} F={Fi}i∈N是 G G G的所有节点特征, v p v_p vp是 v i v_i vi的相邻点(kNN), G G G的邻接矩阵为 A \mathbf{A} A
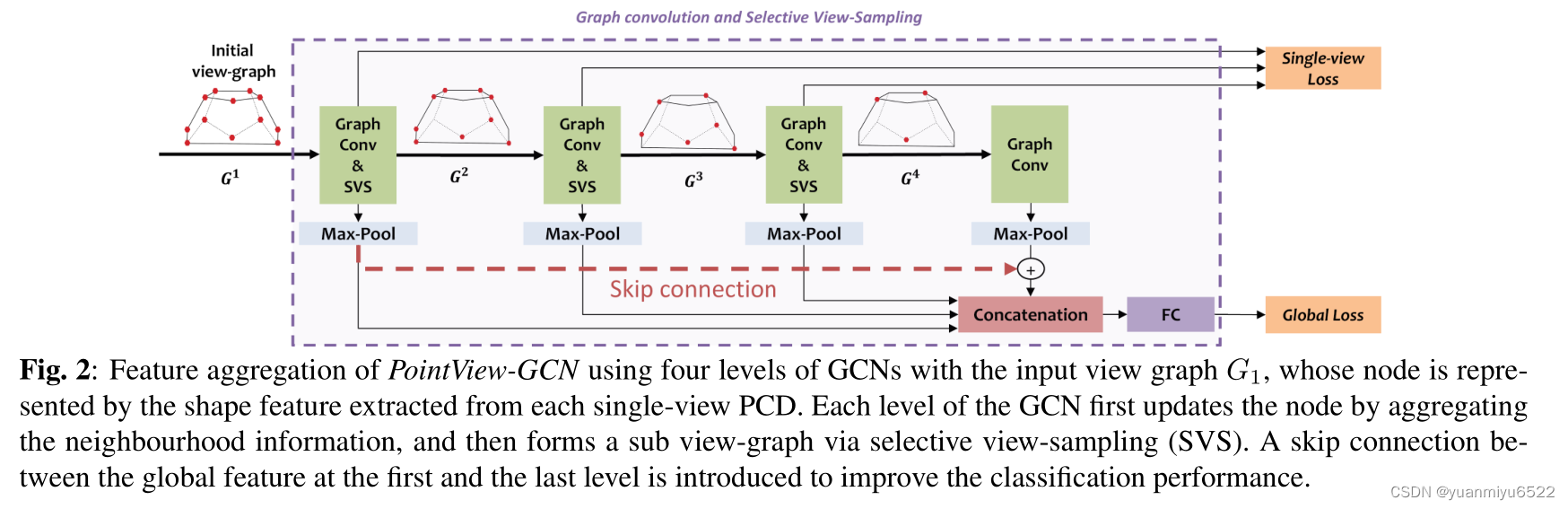
提出网络的特征聚合包含了多个level的GCNs,如图2所示,level的最优数量 M M M通过实验确定。
在第 j j j个level 中,对输入的 G j G^j Gj执行graph convolution操作,更新节点特征 F i F_i Fi,随后跟一个可选择性的 view-sampling,得到更小的graph G j + 1 G^{j+1} Gj+1, G j + 1 G^{j+1} Gj+1中包含了 G j G^{j} Gj最重要的视图信息。
G j + 1 G^{j+1} Gj+1又被作为输入被放入第 j + 1 j+1 j+1个level中。
3.1. Graph convolution and Selective View Sampling
在第 j j j个level中,执行了以下三个操作:
- local graph convolution
- non-local message passing
- selective view sampling (SVS)
Local graph convolution
考虑节点
v
i
j
v_i^j
vij及其相邻节点,local graph convolution通过下式更新节点
v
i
j
v_i^j
vij的特征:
F
~
j
=
L
(
A
j
F
j
W
j
;
α
j
)
\tilde{\mathbf{F}}^{j}=\mathcal{L}\left(\mathbf{A}^{j} \mathbf{F}^{j} \mathbf{W}^{j} ; \alpha^{j}\right)
F~j=L(AjFjWj;αj)
其中
L
(
⋅
)
\mathcal{L}(\cdot)
L(⋅)表示LeakyReLU操作,
α
j
\alpha^{j}
αj 和
W
j
\mathbf{W}^{j}
Wj为权值矩阵。
non-local message passing
接下来还要再通过non-local message passing更新 F ~ j \tilde{\mathbf{F}}^{j} F~j,考虑 G j G^{j} Gj中所有节点间的长距离关系。每个节点 v i v_i vi首先更新其到相邻顶点间边的状态:
m i , p j = R ( F ~ i j , F ~ p j ; β j ) i , p ∈ N j m_{i, p}^{j}=\mathcal{R}\left(\tilde{F}_{i}^{j}, \tilde{F}_{p}^{j} ; \beta^{j}\right)_{i, p \in N^{j}} mi,pj=R(F~ij,F~pj;βj)i,p∈Nj
其中 R ( ⋅ ) \mathcal{R}(\cdot) R(⋅)表示一对视图间的relation function, β j \beta^{j} βj是related parameters。
之后通过下式更新顶点的特征:
F
~
i
j
=
C
(
F
~
i
j
,
∑
p
=
1
,
p
≠
i
N
j
m
i
,
p
j
;
γ
j
)
\tilde{F}_{i}^{j}=\mathcal{C}\left(\tilde{F}_{i}^{j}, \sum_{p=1, p \neq i}^{N_{j}} m_{i, p}^{j} ; \gamma^{j}\right)
F~ij=C⎝⎛F~ij,p=1,p=i∑Njmi,pj;γj⎠⎞
其中
C
(
⋅
)
\mathcal{C}(\cdot)
C(⋅)是combination function,
γ
j
\gamma^{j}
γj是related parameters。
在通过non-local message passing后,特征是在考虑整个图的关系上更新的。
selective view sampling (SVS)
- 使用Farthest Point Sampling (FPS)对 G j G^{j} Gj进行下采样
- 每个下采样后的节点 v i v_i vi的最近邻 V i j \mathbf{V}_{i}^{j} Vij中,使用view-selector选择softmax函数响应最大的节点
- 将coarsened G j + 1 G^{j+1} Gj+1和更新好的 F j + 1 \mathbf{F}^{j+1} Fj+1放入下一层继续处理
3.2. Multi-level feature aggregation and training loss
在每一层graph convolution后,都有一层max-pooling作用在 F j \mathbf{F}^{j} Fj上,目的是得到每个level上的全局形状特征 F global F_{\text {global }} Fglobal 。
最终的全局形状特征 F global F_{\text {global }} Fglobal 是所有level中被pool后特征的拼接。
从第一层的convolution level 到最后一层的convolution level 之间加入了一个residual connection,避免当GCNs level的数量增加导致的梯度消失现象。
训练损失包含两个元素,全局形状损失
L
global
L_{\text {global }}
Lglobal 和selective-view形状损失
L
selective
L_{\text {selective }}
Lselective :
L
=
L
global
(
S
(
F
global
)
,
y
)
+
∑
j
=
1
M
∑
i
=
1
N
j
+
1
∑
v
s
∈
V
i
j
L
selective
(
V
(
F
s
j
;
θ
j
)
,
y
)
\begin{aligned} L=& L_{\text {global }}\left(\mathcal{S}\left(F_{\text {global }}\right), y\right)+\\ & \sum_{j=1}^{M} \sum_{i=1}^{N^{j+1}} \sum_{v_{s} \in \mathbf{V}_{i}^{j}} L_{\text {selective }}\left(\mathcal{V}\left(F_{s}^{j} ; \theta^{j}\right), y\right) \end{aligned}
L=Lglobal (S(Fglobal ),y)+j=1∑Mi=1∑Nj+1vs∈Vij∑Lselective (V(Fsj;θj),y)
其中
L
global
L_{\text {global }}
Lglobal 是交叉熵损失,
S
\mathcal{S}
S是包含了全连接层和softmax函数的分类器,
y
y
y是形状分类。
L
selective
L_{\text {selective }}
Lselective 是用于view selector的交叉熵,保证所选的视图可以识别形状形状分类。
V
(
⋅
)
\mathcal{V}(\cdot)
V(⋅)是用于view selector的函数,参数为
θ
j
\theta^{j}
θj。
F
s
j
F_{s}^{j}
Fsj是下采样后的节点。
在训练时,只有 L global L_{\text {global }} Lglobal 参与。
4.实验
Dataset generation
ModelNet40包含了12311个model,40个类别
ScanObjectNN包含了2909个model,15个类别
基于此构建了4个数据集:Model-D, Model-H, Scan-D 和 Scan-H
D表示二十面体(20个viewpoints),H表示半球(12个viewpoints)
Implementation details
backbone:PointNet++ /DGCNN
4.1. Comparison against state-of-the-art methods
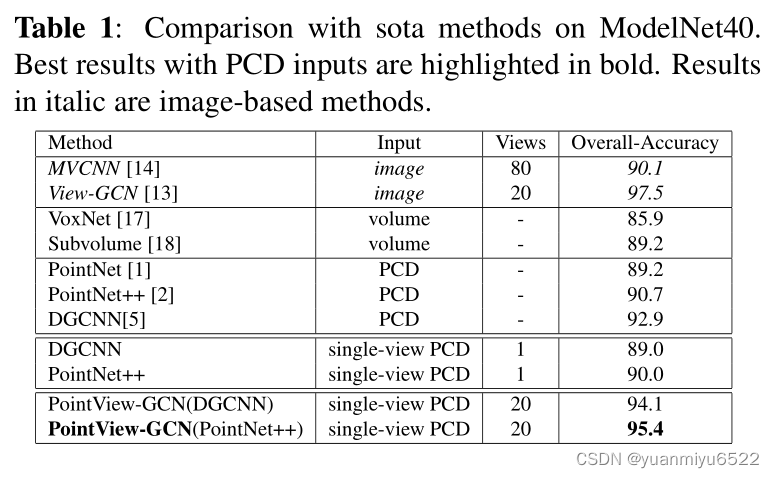
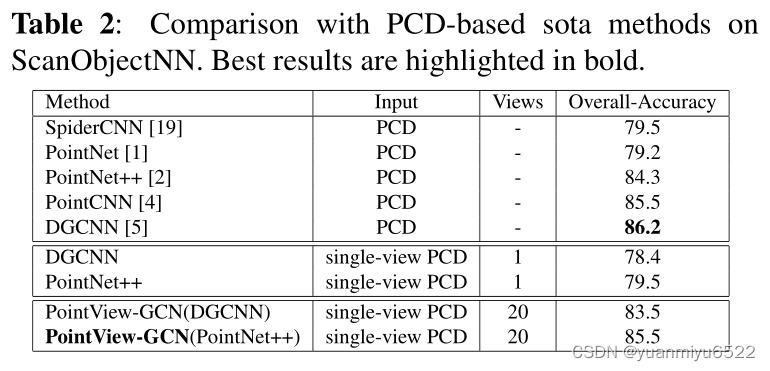
4.2. Ablation studies
Effects of levels of GCN and skip connection
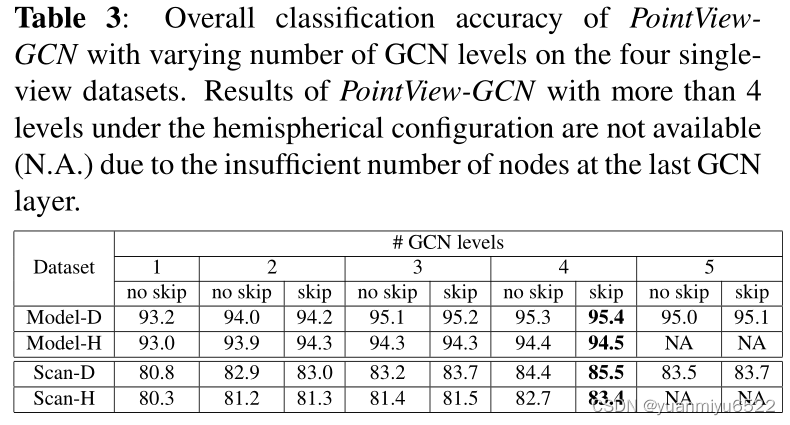
Effects of number of input views
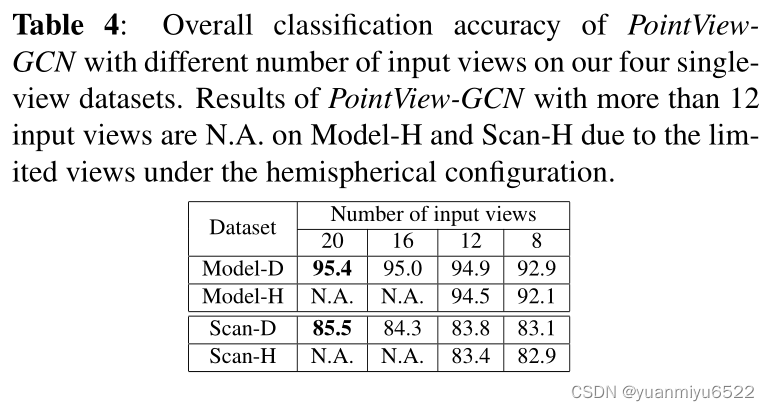
半球体视角设计精度不如二十面体,可能是因为底部没有采集到足够的信息。
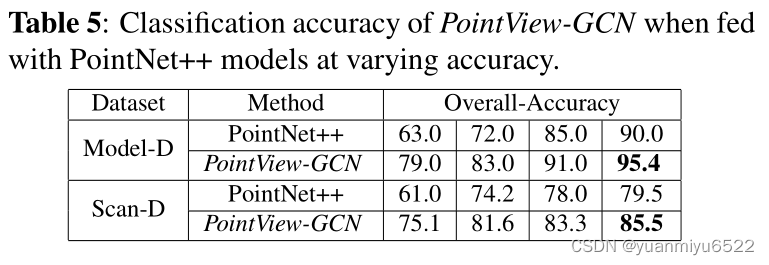
Effects of PointNet++ models of varying classification accuracy


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









