






import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import matplotlib.image as mpimg
import numpy as np
def writedict(c_dict, file_name,topN=100):
c_list=list(c_dict.items())
c_list.sort(key= lambda item:item[1], reverse=True)
return c_list[:100]
male_dict = {}
female_dict = {}
with open('names.txt', 'rt', encoding= 'utf-8') as fo:
for line in fo:
line = line.replace('\n','')
splits = line.split(' ')
if splits[1] == '男':
for c in splits[0][1:]:
male_dict[c] = male_dict.get(c, 0)+1
elif splits[1] == '女':
for c in splits[0][1:]:
female_dict[c] = female_dict.get(c,0) + 1
def sort_dict(c_dict,topN=100):
c_list=list(c_dict.items())
c_list.sort(key=lambda item:item[1],reverse=True)
return c_list[:topN]
img = plt.imread('鸡你太美.png')
img = mpimg.imread('鸡你太美.png')
img = img.astype(np.uint8)
w_cloud = WordCloud(font_path= 'STSONG.TTF',mask=plt.imread('ji5.jpg'))
#w_cloud = WordCloud(font_path= 'STSONG.TTF',width=800,height=800)
w_cloud.generate_from_frequencies(dict(sort_dict(male_dict)))
plt.imshow(w_cloud)
plt.axis("off")
plt.show()
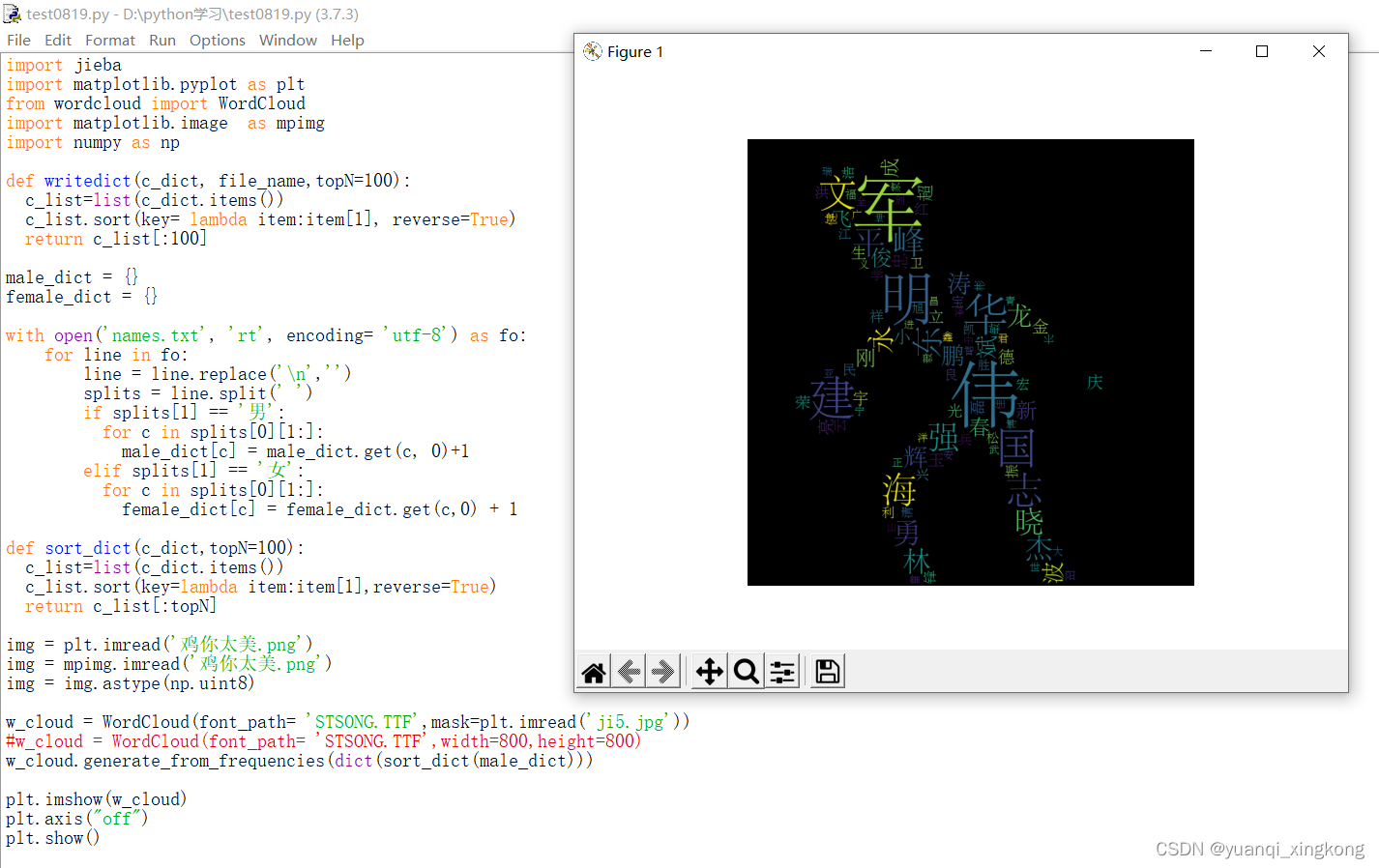
注意,必须为jpg,不能是png,微信截图一般为png。

















 750
750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









