







上一章里讨论了 job 的物理执行图,也讨论了流入 RDD 中的 records 是怎么被 compute() 后流到后续 RDD 的,同时也分析了 task 是怎么产生 result,以及 result 怎么被收集后计算出最终结果的。然而,我们还没有讨论数据是怎么通过 ShuffleDependency 流向下一个 stage 的?
对比 Hadoop MapReduce 和 Spark 的 Shuffle 过程
如果熟悉 Hadoop MapReduce 中的 shuffle 过程,可能会按照 MapReduce 的思路去想象 Spark 的 shuffle 过程。然而,它们之间有一些区别和联系。
从 high-level 的角度来看,两者并没有大的差别。 都是将 mapper(Spark 里是 ShuffleMapTask)的输出进行 partition,不同的 partition 送到不同的 reducer(Spark 里 reducer 可能是下一个 stage 里的 ShuffleMapTask,也可能是 ResultTask)。Reducer 以内存作缓冲区,边 shuffle 边 aggregate 数据,等到数据 aggregate 好以后进行 reduce() (Spark 里可能是后续的一系列操作)。
从 low-level 的角度来看,两者差别不小。 Hadoop MapReduce 是 sort-based,进入 combine() 和 reduce() 的 records 必须先 sort。这样的好处在于 combine/reduce() 可以处理大规模的数据,因为其输入数据可以通过外排得到(mapper 对每段数据先做排序,reducer 的 shuffle 对排好序的每段数据做归并)。目前的 Spark 默认选择的是 hash-based,通常使用 HashMap 来对 shuffle 来的数据进行 aggregate,不会对数据进行提前排序。如果用户需要经过排序的数据,那么需要自己调用类似 sortByKey() 的操作;如果你是Spark 1.1的用户,可以将spark.shuffle.manager设置为sort,则会对数据进行排序。在Spark 1.2中,sort将作为默认的Shuffle实现。
从实现角度来看,两者也有不少差别。 Hadoop MapReduce 将处理流程划分出明显的几个阶段:map(), spill, merge, shuffle, sort, reduce() 等。每个阶段各司其职,可以按照过程式的编程思想来逐一实现每个阶段的功能。在 Spark 中,没有这样功能明确的阶段,只有不同的 stage 和一系列的 transformation(),所以 spill, merge, aggregate 等操作需要蕴含在 transformation() 中。
如果我们将 map 端划分数据、持久化数据的过程称为 shuffle write,而将 reducer 读入数据、aggregate 数据的过程称为 shuffle read。那么在 Spark 中,问题就变为怎么在 job 的逻辑或者物理执行图中加入 shuffle write 和 shuffle read 的处理逻辑?以及两个处理逻辑应该怎么高效实现?
Shuffle write
由于不要求数据有序,shuffle write 的任务很简单:将数据 partition 好,并持久化。之所以要持久化,一方面是要减少内存存储空间压力,另一方面也是为了 fault-tolerance。
shuffle write 的任务很简单,那么实现也很简单:将 shuffle write 的处理逻辑加入到 ShuffleMapStage(ShuffleMapTask 所在的 stage) 的最后,该 stage 的 final RDD 每输出一个 record 就将其 partition 并持久化。图示如下:
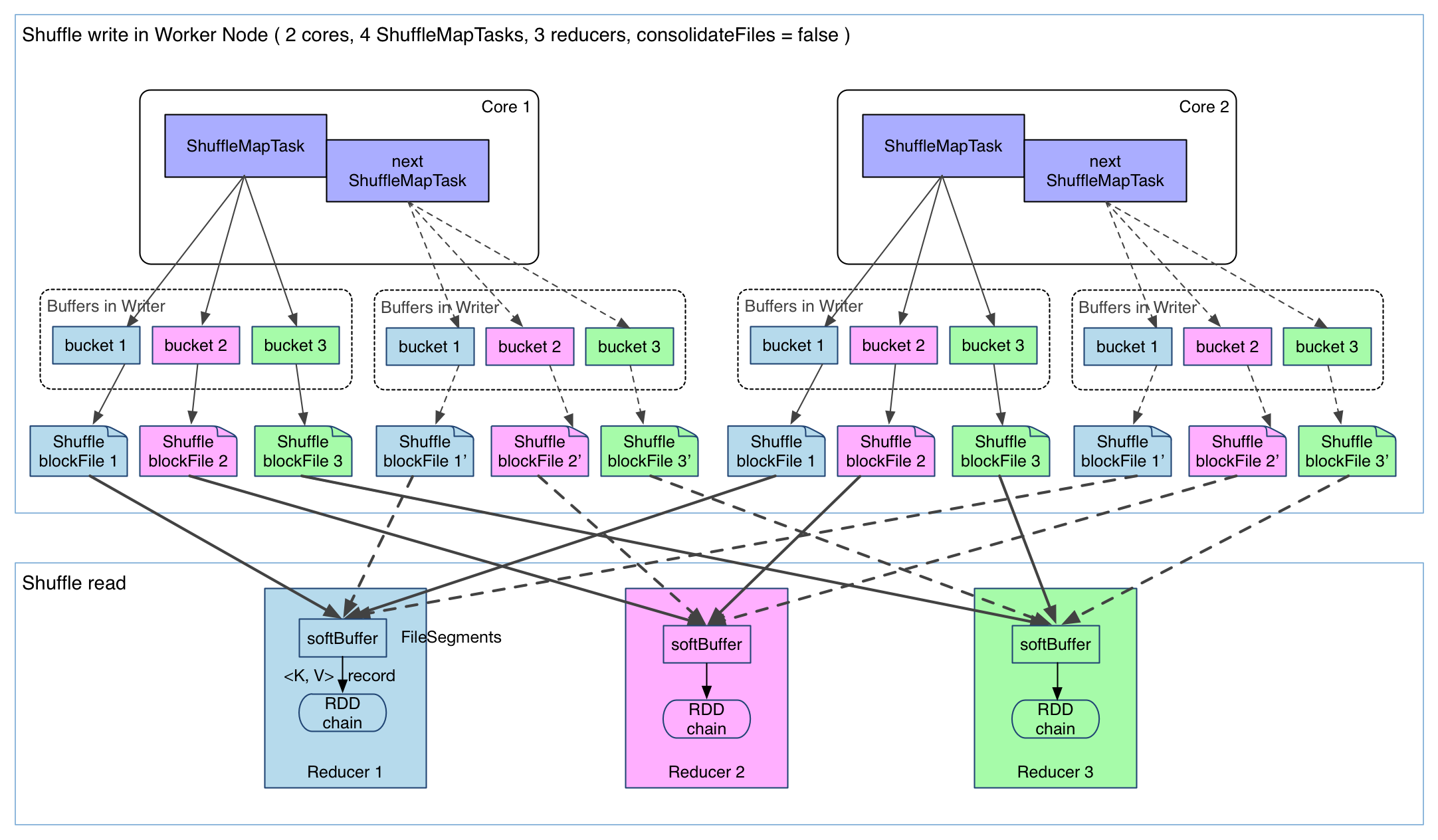
上图有 4 个 ShuffleMapTask 要在同一个 worker node 上运行,CPU core 数为 2,可以同时运行两个 task。每个 task 的执行结果(该 stage 的 finalRDD 中某个 partition 包含的 records)被逐一写到本地磁盘上。每个 task 包含 R 个缓冲区,R = reducer 个数(也就是下一个 stage 中 task 的个数),缓冲区被称为 bucket,其大小为spark.shuffle.file.buffer.kb ,默认是 32KB(Spark 1.1 版本以前是 100KB)。
其实 bucket 是一个广义的概念,代表 ShuffleMapTask 输出结果经过 partition 后要存放的地方,这里为了细化数据存放位置和数据名称,仅仅用 bucket 表示缓冲区。
ShuffleMapTask 的执行过程很简单:先利用 pipeline 计算得到 finalRDD 中对应 partition 的 records。每得到一个 record 就将其送到对应的 bucket 里,具体是哪个 bucket 由partitioner.partition(record.getKey()))决定。每个 bucket 里面的数据会不断被写到本地磁盘上,形成一个 ShuffleBlockFile,或者简称 FileSegment。之后的 reducer 会去 fetch 属于自己的 FileSegment,进入 shuffle read 阶段。
这样的实现很简单,但有几个问题:
产生的 FileSegment 过多。每个 ShuffleMapTask 产生 R(reducer 个数)个 FileSegment,M 个 ShuffleMapTask 就会产生 M * R 个文件。一般 Spark job 的 M 和 R 都很大,因此磁盘上会存在大量的数据文件。
缓冲区占用内存空间大。每个 ShuffleMapTask 需要开 R 个 bucket,M 个 ShuffleMapTask 就会产生 M * R 个 bucket。虽然一个 ShuffleMapTask 结束后,对应的缓冲区可以被回收,但一个 worker node 上同时存在的 bucket 个数可以达到 cores * R 个(一般 worker 同时可以运行 cores 个 ShuffleMapTask),占用的内存空间也就达到了cores * R *  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4088
4088

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









