







经常在学习python递归的时候,大家总是可以看到lru_cache装饰器,说这个装饰器可以减少重复函数的计算。
那么我们今天就来看看,这个函数的一些优缺点。帮助大家从全新的维度来理解一下。
常规的函数
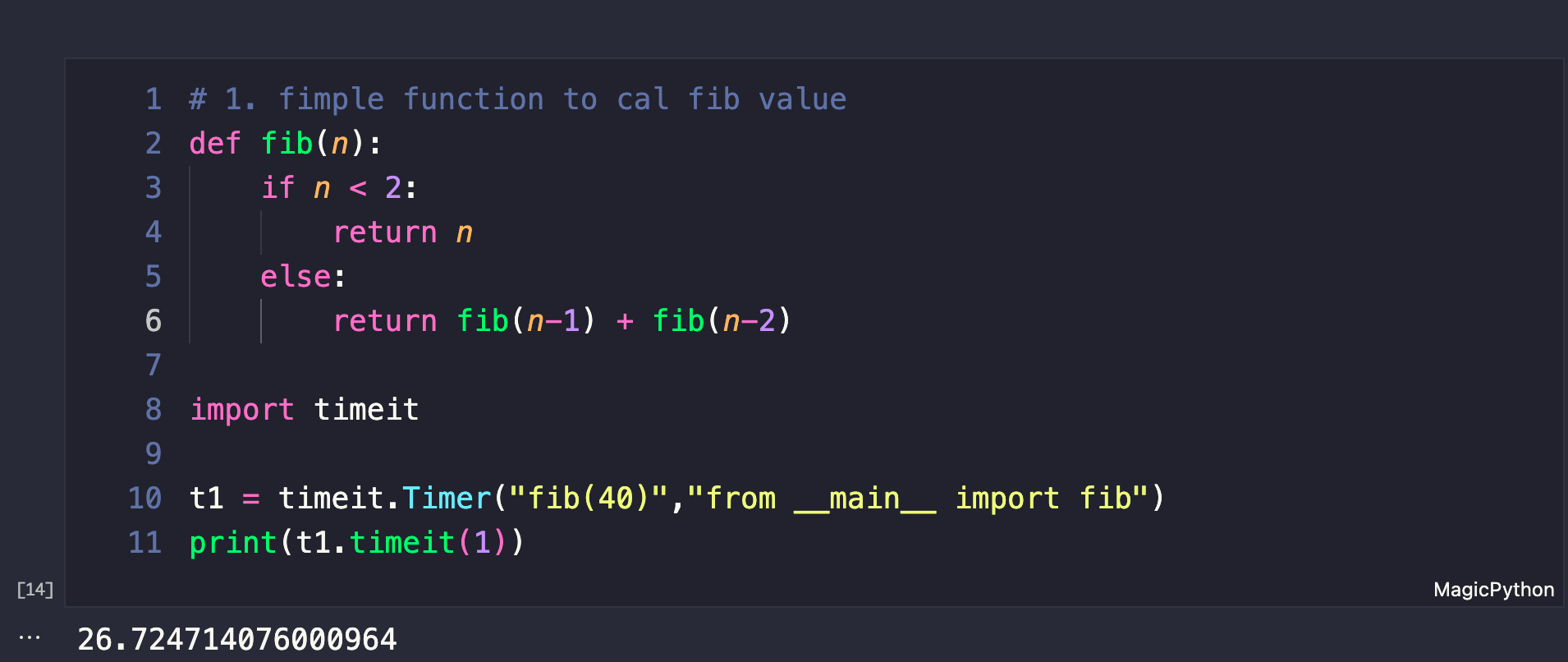
一般来说,我们都是直接使用递归函数的。就像是下面这样的代码:计算斐波那契数列的代码。很常见。
def fib(n):
if n < 2:
return n
else:
return fib(n-1) + fib(n-2)
import timeit
t1 = timeit.Timer("fib(40)","from __main__ import fib")
print(t1.timeit(1))
上面的代码写好之后,运行需要26秒。(在我的计算机上,不同计算机不一样)
使用lru_cache
那么按照很多的python教程来说,他们就会让你使用lru_cache装饰器,这样你就可以缩短时间。
确实,因为lru_cache装饰器可以让保存重复计算的值,然后在需要的时候,拿出来,就不需要再去计算了。那么我们把代码改成这样的,然后看一下效果:
# 3. use lru_cache to reduce the recursion
from functools import lru_cache
import timeit
@lru_cache(maxsize=100)
def fib3(n):
if n <2:
return n
else:
return fib3(n-1) + fib3(n-2)
t1 = timeit.Timer("fib3(40)", "from __main__ import fib3")
print(t1.timeit(1))

看一下时间,确实是很少啦,从26秒降低到小数点后5位了。
通常来说,大部分python教程到这里就停止了。但是我们这里分析一下这么做的缺点。
- 这么做看起来很美好,但是当遇到要计算的东西很多的时候,会占用很大的内存。浪费内存。这可是不可取的。
- 上面这么优化,从时间角度来说,确实缩短了。但是我们其实还可以继续优化,从算法结构上优化。但是很多python课程都不教。
- 上面返回的是一个整型的结果,如果返回一个容器(类似于list、np.numpy)就会出现错误。
就上面三个点,来展开聊了。
1. 占用内存
- 占用内存就不说了:这里主要是想强调一点。
lru_cache记录缓存数据的时候,是使用的字典形式。然后如果max_size很大的时候,确实很占用很多内存。
2. 如何优化
优化的方法没啥好的办法,不同的函数要特别注意。比如我们这里的斐波那契数列。其实优化成这样的代码,就算是不加lru_cache装饰器,计算的也很快。代码如下:
# 2. improve the algo to cal fib vlaue
def fib2(n):
a, b, c = 0, 1, n
for i in range(n-1):
c = a+b
a, b = b, c
return c
t1 = timeit.Timer("fib2(40)", "from __main__ import fib2")
print(t1.timeit(1))
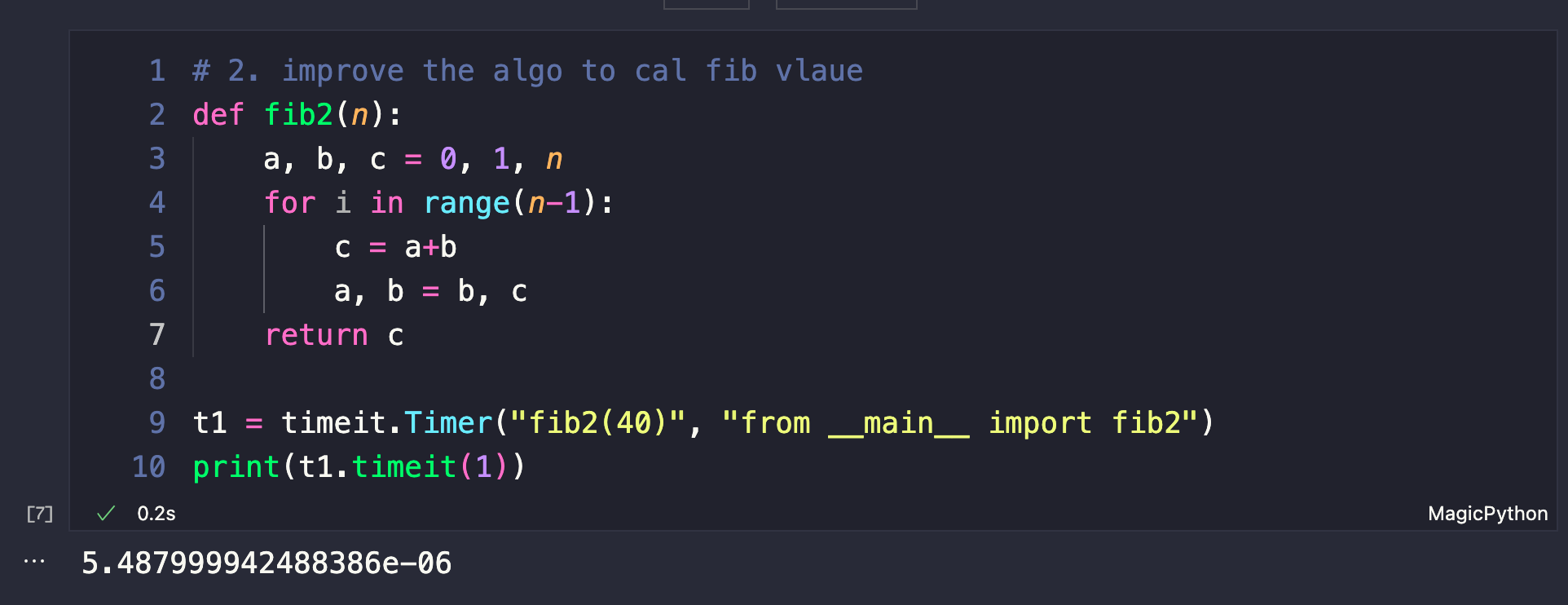
看看运行的时间,是小数点后6位了。比加lru_cache的函数还要快!!!
3. lru_cache不能装饰特殊的函数
lru_cache装饰器是不能直接 使用于那种返回容器类型的函数,这里举个例子。
import numpy as np
@lru_cache
def cached_function(param):
print(f"running cached_function on: {param}")
return np.array([param])
for number in [100, 100, 100, 200]:
res = cached_function(number)
res *= 5
print(f"number: {number}, result: {res}")
在上面的代码中,对函数cached_function使用了装饰器。然后使用for循环计算了4次100``一次200。每次计算后,然后对结果乘以5。
那么按照道理来说,print(f"number: {number}, result: {res}")打印出来的结果中:res是number的5倍。但是结果不是这样的。

查看上面的运行结果,你就知道了,虽然100只是计算了1次,但是结果是按照5倍不断的增长的。这错了哇。
这种问题如何解决?
其实就是解决浅拷贝问题。我们按照要求,对lru_cache装饰器做一下改进。改进后的函数,就可以去装饰返回容器类型的函数了。
from functools import lru_cache
from copy import deepcopy
def copying_lru_cache(maxsize=10, typed=False):
def decorator(f):
cached_func = lru_cache(maxsize=maxsize, typed=typed)(f)
def wrapper(*args, **kwargs):
return deepcopy(cached_func(*args, **kwargs))
return wrapper
return decorator
@copying_lru_cache()
def cached_function(param):
print(f"running cached_function on: {param}")
return np.array([param])
for number in [100, 100, 100, 200]:
res = cached_function(number)
res *= 5
print(f"number: {number}, result: {res}")
上面代码运行如下:
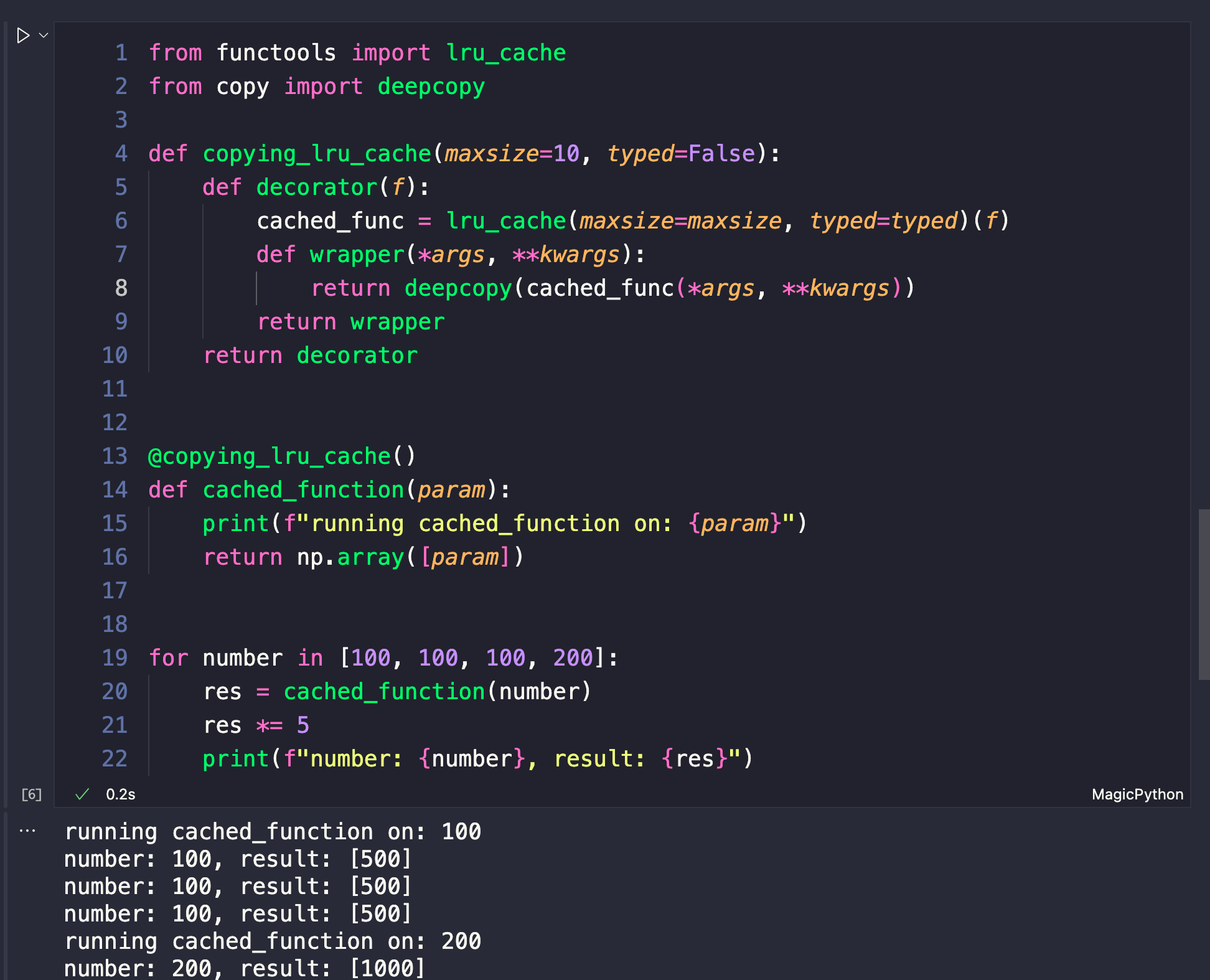
查看结果,虽然返回的是容器类型的,但是没啥问题了。
最后
在最后,使用lru_cache的时候,注意下面几点:
- 函数还能不能再优化了? 找一找最优的写法。
- 函数如果返回的是容器类型的数据,不能直接使用
lru_cache。

















 593
593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











