






一、爬虫简介
想到爬虫大部分人都会想到python,但是不止python可以进行爬虫,只是python语言简单,对于网络爬虫的方式很方便;网络爬虫又称网络蜘蛛、网络蚂蚁、网络机器人等,可以自动化浏览网络中的信息,当然浏览信息的时候需要按照我们制定的规则进行,这些规则我们称之为网络爬虫算法。使用Python可以很方便地编写出爬虫程序,进行互联网信息的自动化检索。
二、代码编写
在本次的代码中,我们只会用到一些简单的语句实现在网站上数据的爬取,再使用pyttsx3包进行语言播报功能,这对于刚学习爬虫的同学来说比较简单也好上手,可以读懂每个代码所带来的意思。
本次我们将继续使用requests包进行爬虫,使用lxml进行网页的解析,再由pyttsx3进行语音播报的实现,如果不知道如何去安装包,就在终端里实现以下代码:
pip install 下载的包我们在下载完包之后,在py文件的开头使用improt使用。
import requests
from lxml import etree
import pyttsx3接下来,我们去我们需要爬取的天气网站得到他们的网址,还有不同城市中的不同编码,这里我拿重庆做例子,小编在这里使用的是天气网:天气网
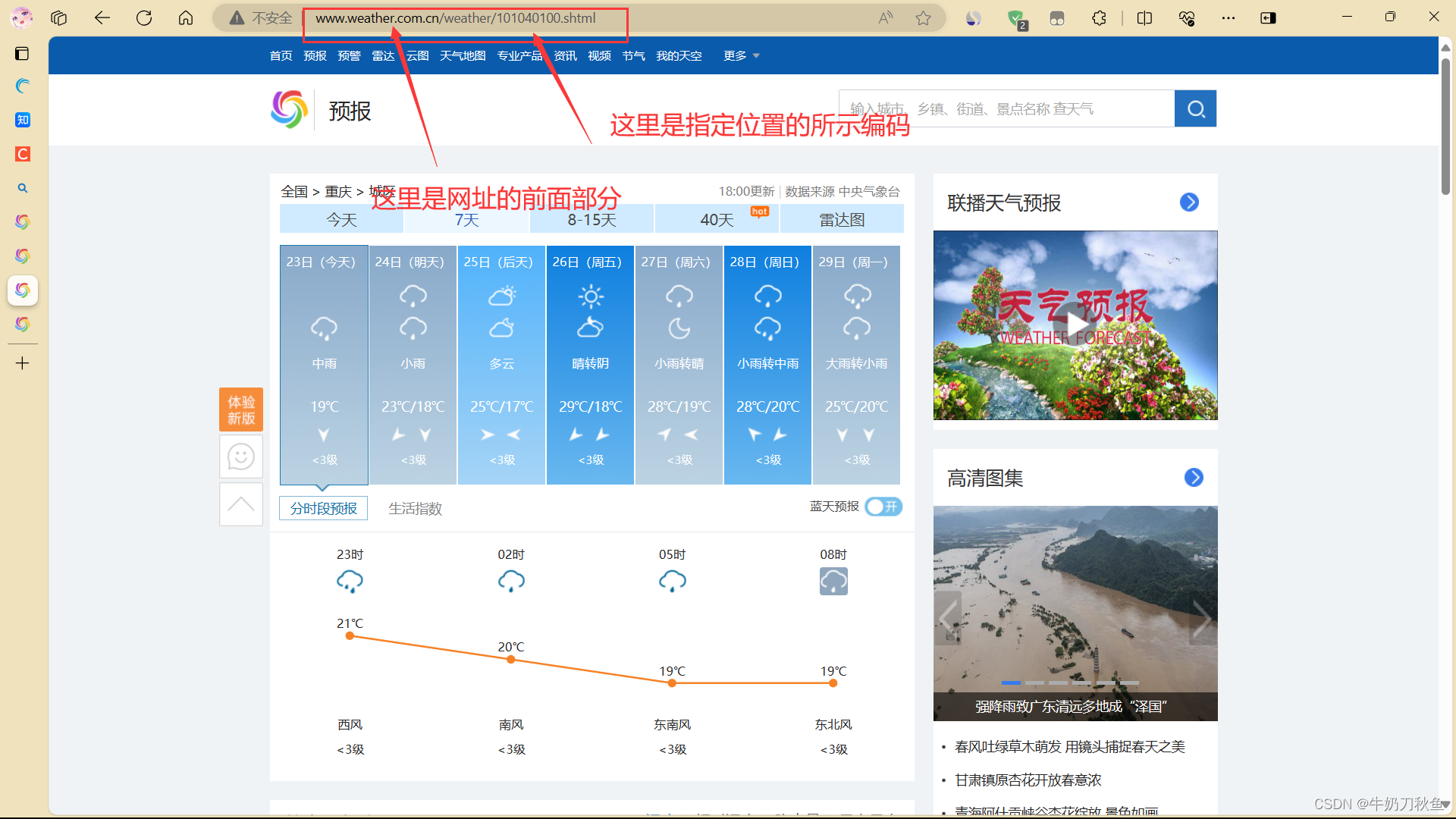
去我们的idea或者其他的解释器,赋予他们值,开头和结尾都要附上,让中间的编码存入自己创建的一个字典,在后期要使用的时候再拿出来。
wangzhi = 'http://www.weather.com.cn/weather/'
bbb = { '北京':'101010100','重庆':'101040100'}
jiewei = '.shtml'
dizhi = input('请输入您要查询的城市代码:')
ccc = bbb.get(dizhi)接下来使用我们的lxml进行对网页的编码,使用xpath对网页进行解析,网页编码大部分都是‘UTF-8’。
response =requests.get(url)
response.encoding ='utf-8'
html_content = response.text
xpath_str = etree.HTML(html_content)我们回到之前的天气网,按下F12,检查当前网页的源代码,找到我们需要爬取的文字信息所在位置,这里对于网页不清楚的同学最好去查看一下基础知识。
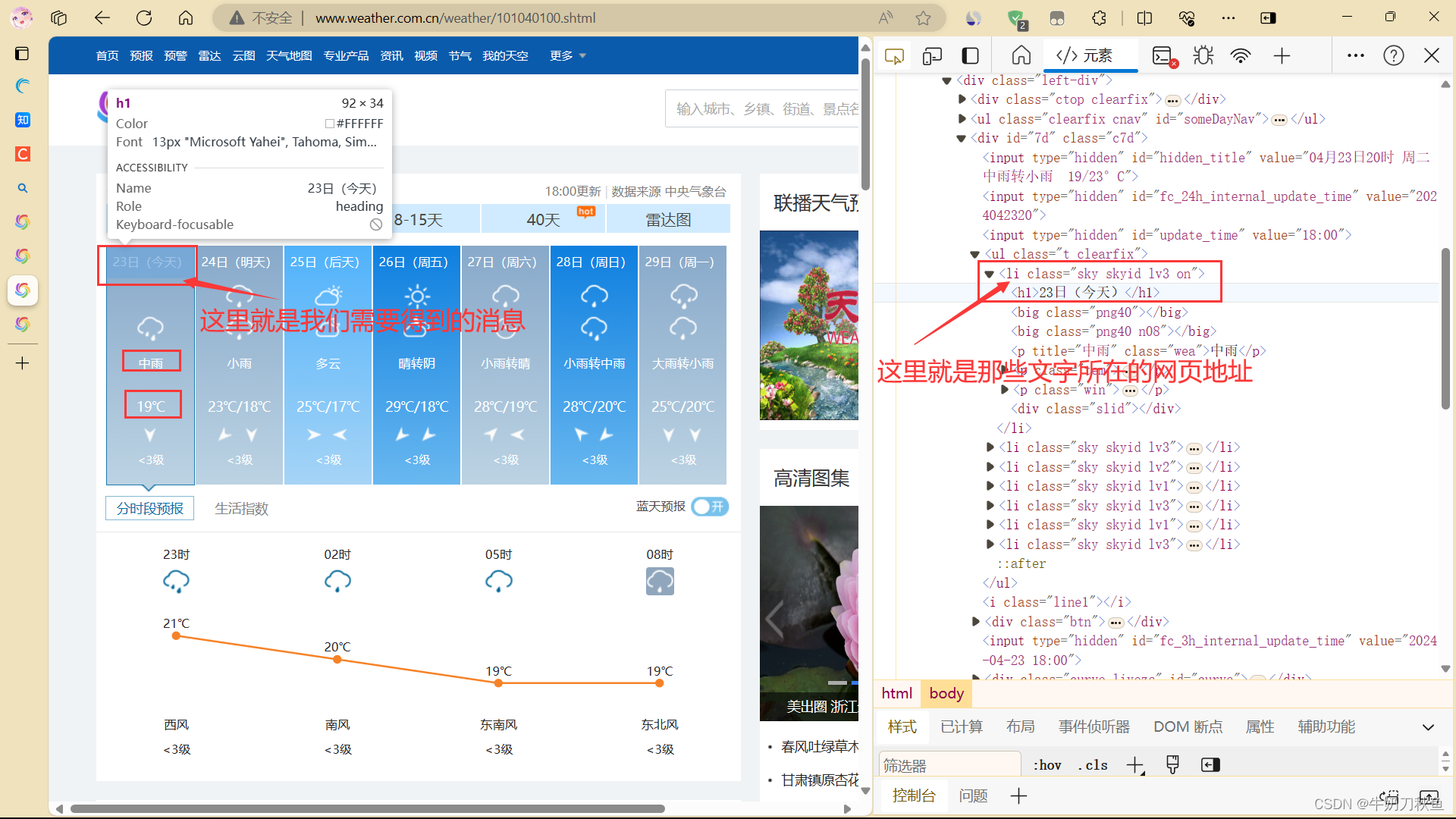
从这里我们知道我们所需要得到的消息在很多div的下面,也有很多li头,那我们该怎么办呢,我们使用contains代码查找包含类名"crumbs fl"的div标签和"skyid"的li标签,因为我们需要的不同消息在不同的地方,每个都是不一样的,在前面我们使用xpath对于我们需要的消息进行解析。
didian = xpath_str.xpath('//div[contains(@class,"crumbs fl")]/a[2]/text()')
riQi = xpath_str.xpath('//li[contains(@class,"skyid")]/h1/text()')
tianQi = xpath_str.xpath('//li[contains(@class,"skyid")]/p/@title')
wenDu = xpath_str.xpath('//li[contains(@class,"skyid")]/p/span/text()')在最后我们引用我们的语音包pyttsx3,再用for循环将我们需要的东西展示出来,因为我们引用了pyttsx3所以在展示的同时会有语音同时播报。这就是我们这次的天气简单预报系统。
abc = pyttsx3.init()
for time,data,du in zip(riQi, tianQi, wenDu):
print('日期:{},天气:{},最高温度:{}°\n'.format(time,data,du))
abc.say('{},{},{},最高温度:{}°\n'.format(didian,time,data,du))
abc.runAndWait()
三、成果展示
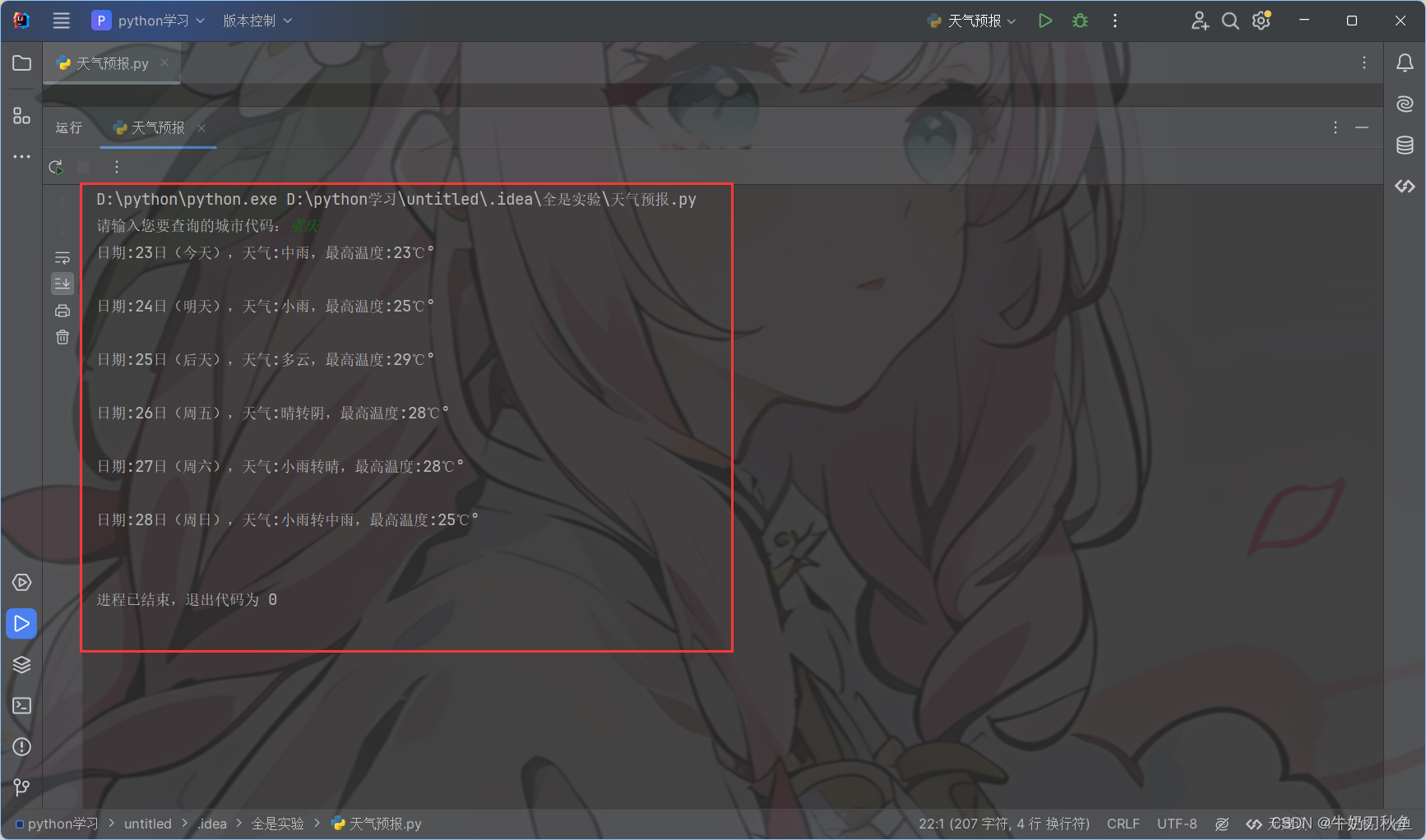
四、可能在中遇到的一些bug
我们在运行最终代码的时候,可能没有任何东西就会结束进程,也有可能还没运行的时候就结束了进程,这些原因都是我们在解析网页的时候失败了,没有找到正确的头。















 6167
6167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









