







李宏毅机器学习
周志华机器学习第8章
使用sklearn进行集成学习
stacking心得
xgboost实战
bagging:
- 当原模型已经很复杂的时候,bias已经很小但variance很大时候。比较容易overfit的模型:Decision Tree(在train上100%)
- random forest:bagging of decision tree
boosting
- 将bias较大的弱学习器组合。f1较弱,->f2 来辅助(和f1差异较大),->f3 … 学习器是顺序学习的
- 获取不同的学习器:a 训练数据重采样,训练数据重赋权重(改变cost function)
- adaboost
先训练f1,然后找到新的训练数据在f1上效果不好(50%。 reweighting 训练数据),用其训练f2。- gbdt


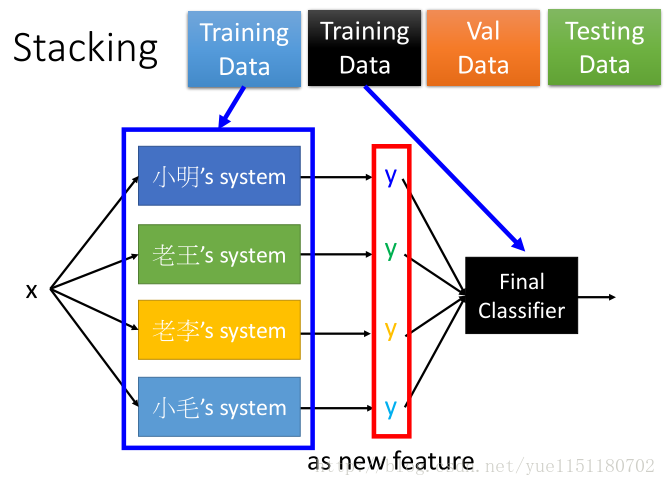
stacking
- voting
final classification 是lr就可以,不需要太复杂。
将 training data 分为两部分,一部分训练元模型,一部分训练final















 1107
1107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









