









 本文介绍时序列数据库(TSDB)的概念及其特点,包括数据结构、数据写入与读取方式及应用场景。同时提供了选择合适TSDB的方法。
本文介绍时序列数据库(TSDB)的概念及其特点,包括数据结构、数据写入与读取方式及应用场景。同时提供了选择合适TSDB的方法。
概述
时序列数据库(Time series database):用来存储时序列(time-series)数据并以时间(点或区间)建立索引的软件
一般时序列数据都具备
- 数据结构简单:某一度量指标在某一时间点只会有一个值,没有复杂的结构(嵌套、层次等)和关系(关联、主外键等)
- 数据量大:由于时序列数据由所监控的大量数据源来产生、收集和发送,比如主机、IoT设备、终端或App等
TSDB特点
- 专门优化用于处理时间序列数据,时间序列数据按特性分为两类
- 高频率低保留期(数据采集,实时展示)
- 低频率高保留期(数据展现、分析)
- 时间序列数据的几个前提
- 单条数据并不重要
- 数据几乎不被更新,或者删除(只有删除过期数据时),新增数据是按时间来说最近的数据
- 同样的数据出现多次,则认为是同一条数据
数据写入
- 写多于读:95%-99%的操作都是写操作
- 顺序写:由于是时间序列数据,因此数据多为追加式写入,而且几乎都是实时写入,很少会写入几天前的数据
- 很少更新:数据写入之后,不会更新
- 区块删除:基本没有随机删除,多数是从一个时间点开始到某一时间点结束的整段数据删除
数据读取(查询)
- 顺序读:基本都是按照时间顺序读取一段时间内的数据。
- 基数大:基本数据大,超过内存大小,要选取的只是其一小部分,且没有规律,缓存几乎不起任何作用
基本数据分析支持
- TSDB的数据是用来分析的,所以TSDB还会提供做数据分析所必须的各种运算、变换函数。如可以方便的对时序列数据进行求和、求平均值等操作
如何去选择时序列数据库
时序数据库有很多 请查看DB-Engines Ranking
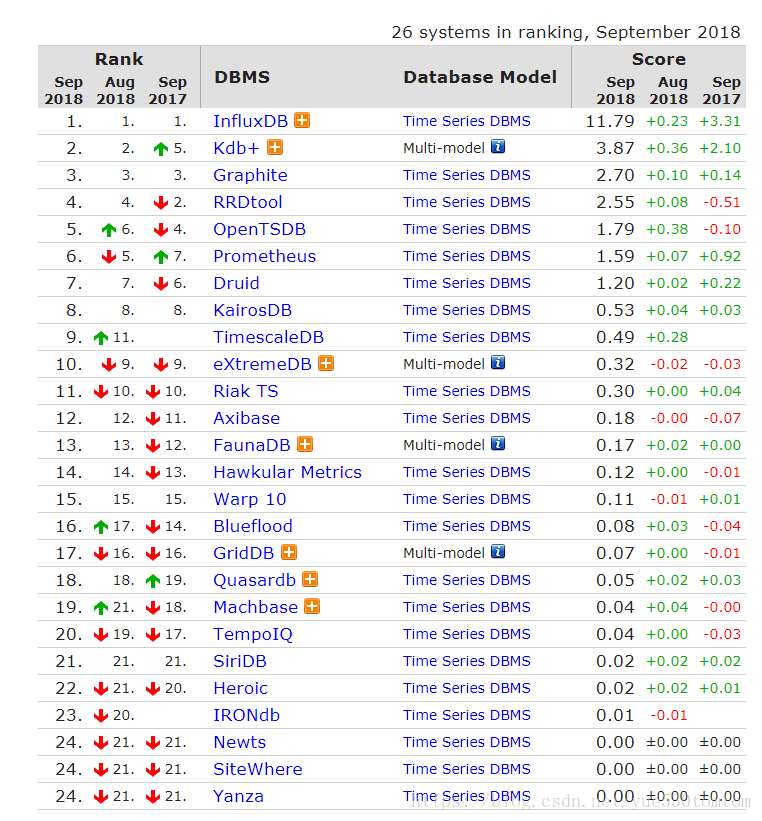
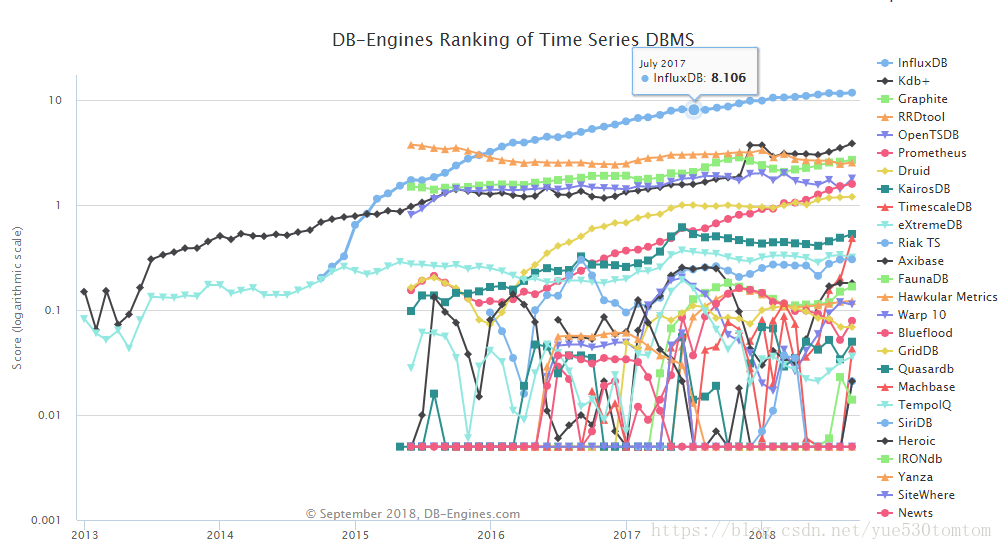
选择时可以从以下方面综合考虑
- 性能、存储方案、集群功能、API(HTTP API和Client Library)、SQL-like Query Language、部署体验、成熟度、可视化和报警功能、所采用技术栈、保留策略(Retention Policies,或自动删除、压缩)、背后主导公司、License、安全性等等
从排序中可以看到(包括前几年的影响力)influxdb一直备受关注,也是我在工作使用最多的时序数据库(单机,集群要收费)
~为influxdb相关的东西做个铺垫~

















 1346
1346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









