







LFU
LFU(Least Frequently Used)即最少访问算法。通过访问频率作为数据淘汰的依据。核心思想是:如果一个数据在过去的一段时间访问的次数较少,那么未来他被访问的概率也较低。与之相应的还有LRU(Least Recently Used),即最近最少使用算法,通过最后一次访问时间来作为数据淘汰的依据,核心思想是如果一个数据已经有较长的时间没有收到访问,那么未来他被访问的概率也较低。
LFU除了使用一个容器(一般为Hash)用来存储和检索数据外,还需要一个额外的结构记录数据的访问次数。
- 新增数据时,将数据载入容器,并将计数置为1,
- 访问数据时将数据计数+1
- 数据淘汰时从计数器中取出访问次数最小的键进行淘汰。(次数的统计可以实时排序,也可以执行淘汰策略时才排序)
优点:
- 可以保留使用频率较大的数据,以有效的保证缓存命中率
缺点:
- 需要维护每一个数据的访问次数,同时需要对访问次数进行排序。也就需要内存和CPU的额外开销
- 对新数据不友好,新缓存如果刚进入容器即遭遇淘汰计算,那么会被立刻清理掉
- 存在缓存污染的问题,如果一个缓存因为瞬时访问有一个较高的访问次数,后续数据访问频率较低,那么即使这个数据已经长时间没有访问,依然不会被淘汰,污染缓冲池。
LFUDA(LFU-Aging)
上面提到基础的LFU算法存在缓存污染的问题,LFUDA(LFU with dynamic aging)便是针对缓存污染的优化算法。
缓存污染主要原因是一个数据的瞬时高访问导致的难以淘汰的问题,如果引入过期的概念那么也就可以解决缓存污染的问题,但是如果记录每次访问的时间,那么这无疑会让整个算法变得极其复杂。
LFUDA的做法是:设定一个阈值,并统计当前所有缓存访问次数的平均数,如果平均访问次数超过这个阈值,就对所有引用次数进行老化(减少固定值或者减少一定的比率等),以此来逐步减小污染数据的访问次数,进行淘汰。
使用平均数和仅以当前数据次数对比访问阈值各有优劣:平均数对比能保证那些相对较低的数据不会被很快淘汰,缺点是对于污染数据的清理没有单一数据阀值那么那么全。单一数据阈值则能更好的老化污染数据的次数,但是可能会导致那些频率远低于他的数据迅速被老化清理。因此LFUDA采用了平均数对比,避免错误淘汰使得缓存无法发挥应有的作用。
优点:
- 一定程度上(并不是一定)解决了缓存污染,提高了缓存命中率
缺点:
- 实现更加复杂,而且平均访问次数的计算及老化策略需要额外的开销
Window-LFU
Window-LFU采用另一种方式一定程度解决缓存污染的问题。
Window-LFU,顾名思义,一种窗口LFU算法,该算法定义一个定长的链表,数据访问时将该请求放到队尾,并清理掉到队首的数据,就像一个窗口一样,只保留窗口能看到的这一段数据。
需要淘汰时对链表中的数据进行统计,就能得出数据在窗口期的访问次数,这样做的好处是不在需要额外的空间实时维护访问次数,坏处是淘汰时需要进行一次遍历统计。当然也可以实时维护记录访问次数,这种方式淘汰时无需进行遍历统计,但是需要额外的空间做维护。
优点:
- 一定程度上(并不是一定)解决了缓存污染,提高了缓存命中率。效果上比LFUDA更好一些。
- 不需要额外的空间维护访问次数(如果不采用实时统计的话)
缺点:
- 复杂度略高于LFU
W-TinyLFU算法
W-TinyLFU算法是目前Caffeine Cache使用的一种LFU算法,旨在以损失一定程度的统计精度为代价来节约内存。
了解W-TinyLFU算法之前,需要先了解一个布隆过滤器。

布隆过滤器对应一个大型的位数组,然后设置一定数目的无偏hash函数,无偏是指计算出的hash值相对均匀。 向布隆过滤器中添加key时,分别用设置的hash函数对key进行hash计算获得一个索引值然后取模获得对应的下标,然后下标对应的数组位设置成1。查找时同样分别用设置的hash函数获得对应的下标,只要有一位是0,那么就说明这个元素不存在,如果都为1,那么说明这个元素可能存在,不是一定的原因是相应的位是被其他元素设置的。位数组内的1的位越稀疏,存在的可能性就越大。
W-TinyLFU则是维护一个长度为4的long型的一维数组,每个long型以4bit为一份,分为16份。每个long型对应一个hash函数,数据到来时,通过每个hash函数运算获得key落在该long型的位置,并将该位置计数+1。在进行统计频率时获得四个位置的频率值,并以最小值作为频率。
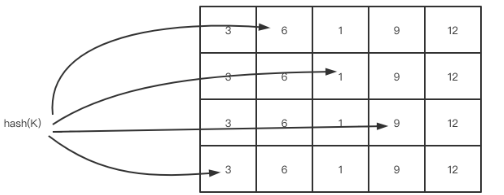
这样的方式有个问题,就是是一份只有4bit,所以计数最高为15。因此如果所有计数之和超过阈值时,进行除以2的退化操作(LFUDA的理念,同时也避免了缓存污染)。
LFU本身具有对新数据不友好的特性他,W-TinyLFU为了解决这个问题则采用了类似JVM分代的概念,新访问的数据会被放入WIndowDeque区,WindowDeque区满时进入将频次最高的放入ProbationDeque,后续继续访问时将ProbationDeque频次最高的放入ProtectedDeque区,ProtectedDeque区满时,开始进行淘汰,将频率最低的重新降级到ProbationDeque区。取ProbationDeque中的队首和队尾进行PK,队首元素是最先进入队列的,称为受害者,队尾元素称为攻击者,比这两者频率,大胜小汰。
Caffeine 认为读操作是频繁的,写操作是偶尔。为了提高读写性能,读写都是异步线程更新频率信息。其中因为读可以容忍延迟,采用一个队列实现,数据丢到队列就返回。而写丢的话通过阻塞队列实现。
参考资料:
LFU算法族
高性能缓存 Caffeine 原理及实战

















 1807
1807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











