






创建伪分布式
1 创建一个全新的虚拟机,配置IP

2 上传以下4个安装包

一 JDK配置
解压

配置环境变量
vi /etc/profile #在末尾添加

保存后刷新环境变量
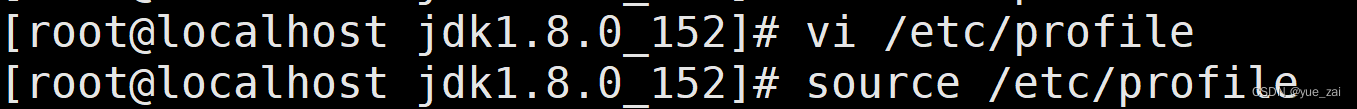
刷新完成后验证JDK是否安装完成

二 Hadoop配置
解压安装包

进入hadoop配置目录,并修改配置文件

在文末添加 #JAVA_HOME指的是JDK安装路径
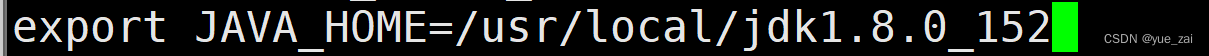
保存退出,重新生效这个文件
![]()
配置以下文件
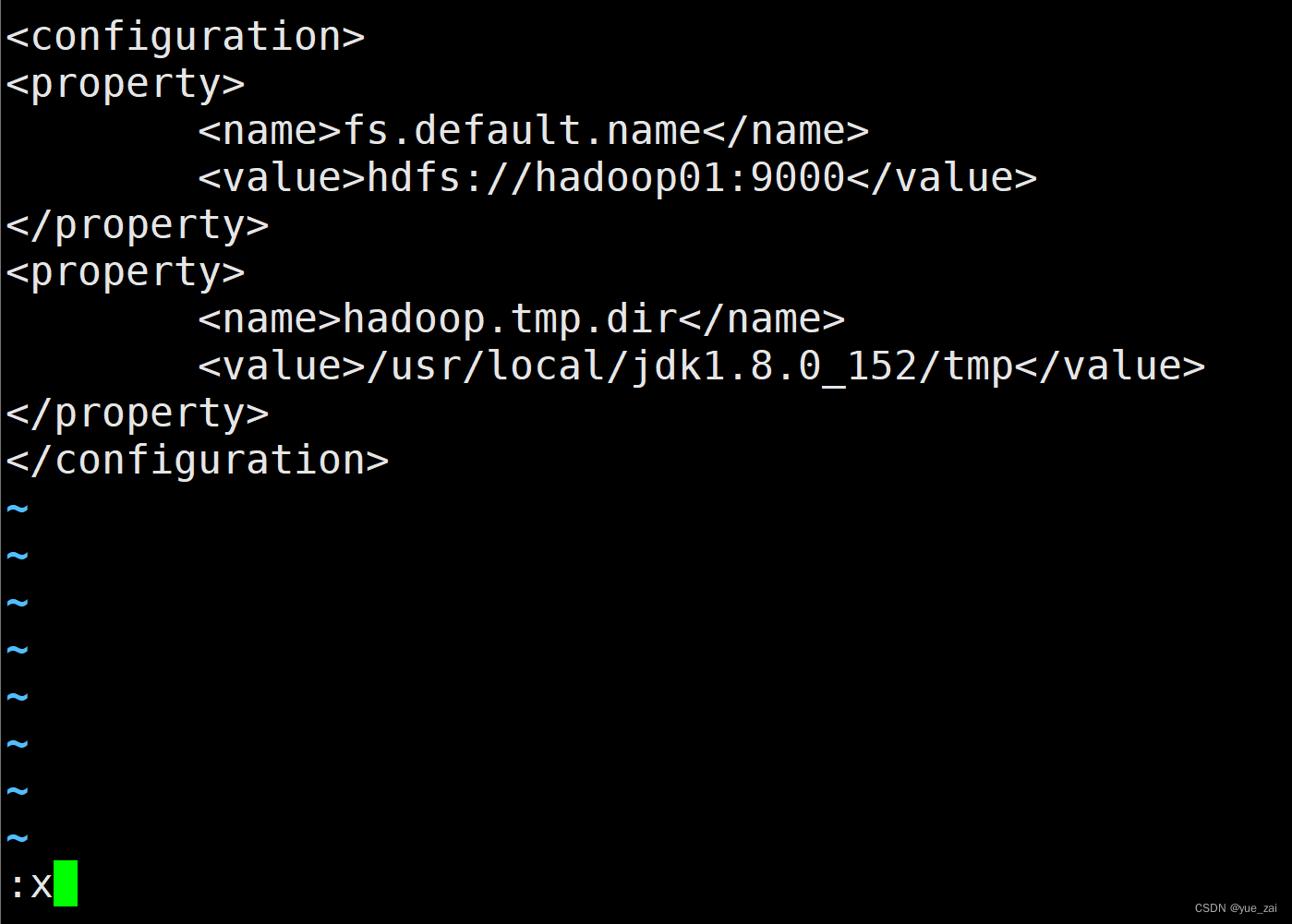
1 core-site.xml文件

2 hdfs-site.xml


3 mapred-site.xml
![]()

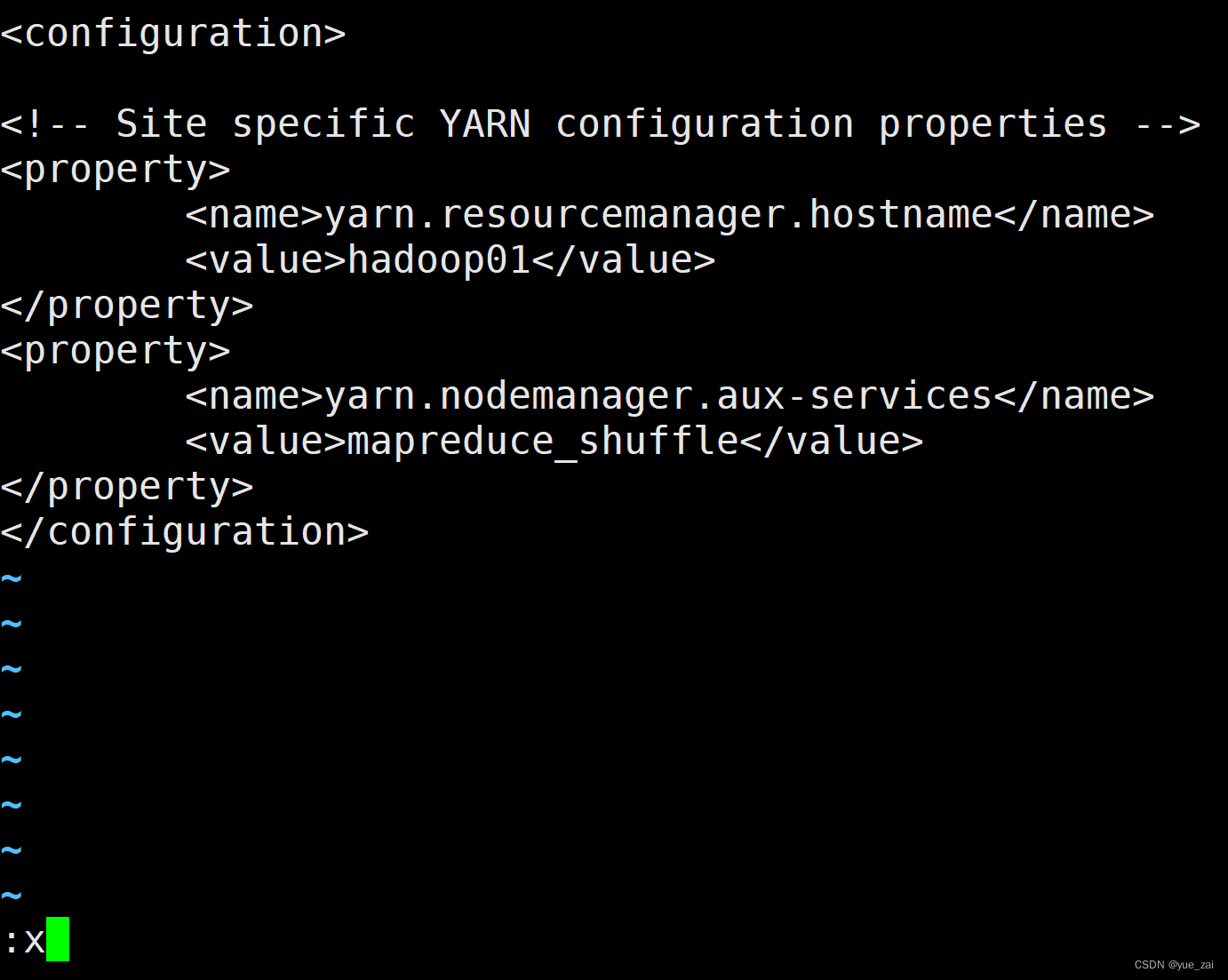
4 yarn-site.xml
![]()
配置Hadoop环境变量
vi /etc/profile #添加以下两行

刷新环境变量
source /etc/profile
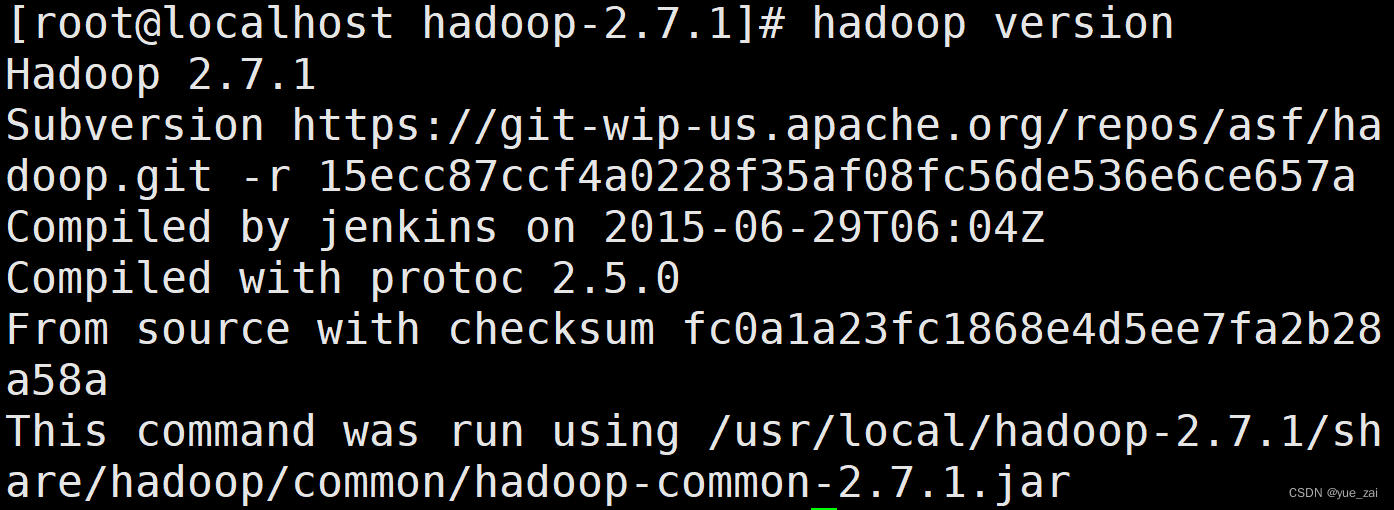
验证hadoop配置成功
hadoop version
hadoop停止启动配置

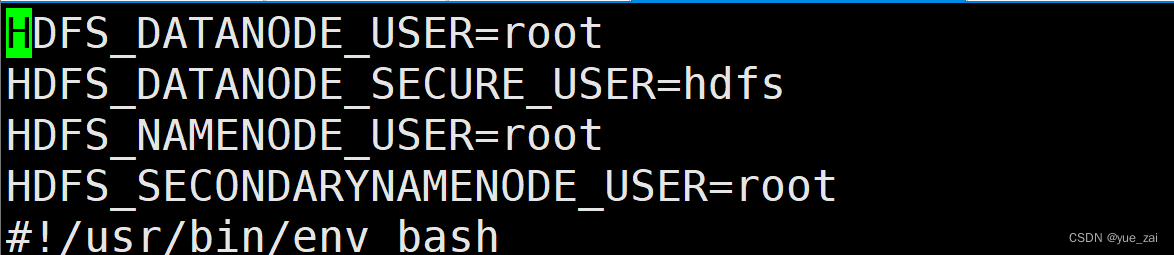
vi start-dfs.sh 在头部添加

vi stop-dfs.sh 在头部添加
格式化
hdfs namenode -format
jps 查看进程

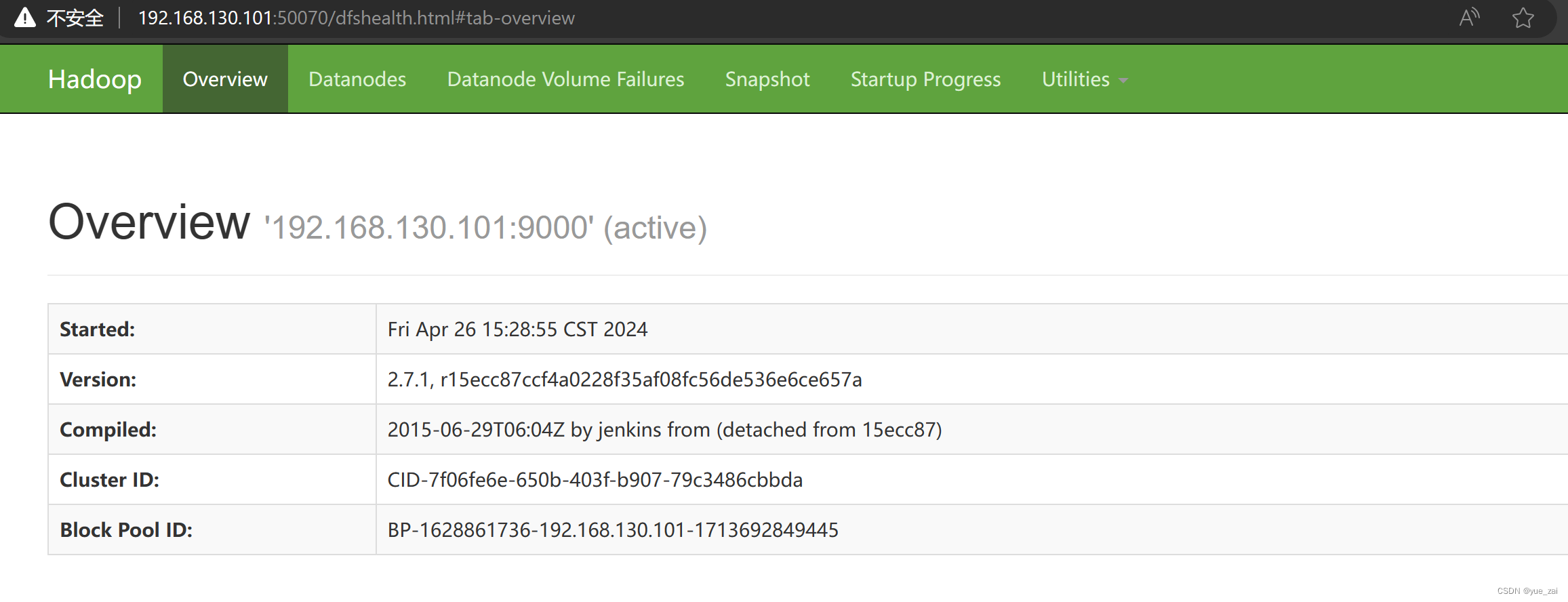
查看50070端口
三 spark和scala配置 (以下安装包的路径与之前不同/opt/software 解压到/usr/local/soft下)
上传安装包并解压
修改环境变量,并刷新



/usr/local/soft/spark/conf 路径下 spark-env.sh

vim slaves

启动

查看spark8080端口和访问spark-shell交互式界面

















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









