







目录
基本语法
输入
input函数可以实现输入操作.
input()
#input默认输入参数为字符串.
a=input().split()
#用于一行输入多个,split()参数为空,默认一行输入多个时用空格隔开。
b,c=map(int,input().split())
print(a,b)sys.stdin.readline()输入将所有输入视为字符串,并在最后包含换行符’\n’。
行与缩进
可将同一个代码层级的物理行用 ; 合并为一逻辑行,可以用 “ \ ”将一逻辑行换为多物理行,在 [], {}, 或 () 中的多行语句,不需要使用" \ "就可换行。变量赋值语句可以直接换为多物理行。
逻辑行首行顶格,以缩进为相同逻辑层的特征,进入新逻辑层表示“ :”。
i=5
a=6
if i==5:
while a<9:
a=a+1
print(a)
print(a)
# 7 8 9 9输出
使用print输出,其输出默认换行。
print("1")
print("1",end="")
#不换行.运算符
| **= | 幂赋值运算符 |
| //= | 取整除运算符 |
| or | 或 |
| not | 非 |
| and | 与 |
| in | 在序列中找到值返回true,反之返回false. |
| not in | 在序列中找不到值返回true,反之返回false. |
| is | 判断两个标识符是否引用同一对象,是则返回true。 |
| not is | 判断两个标识符是否引用同一对象,是则返回false。 |
变量及数据类型
变量不需要声明,但在使用前必须赋值,变量赋值以后该变量才会被创建。
数据类型中,
- 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
- 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)
Number
复数(complex),可以用 a + bj或complex(a,b)表示,a,b均为float类型。
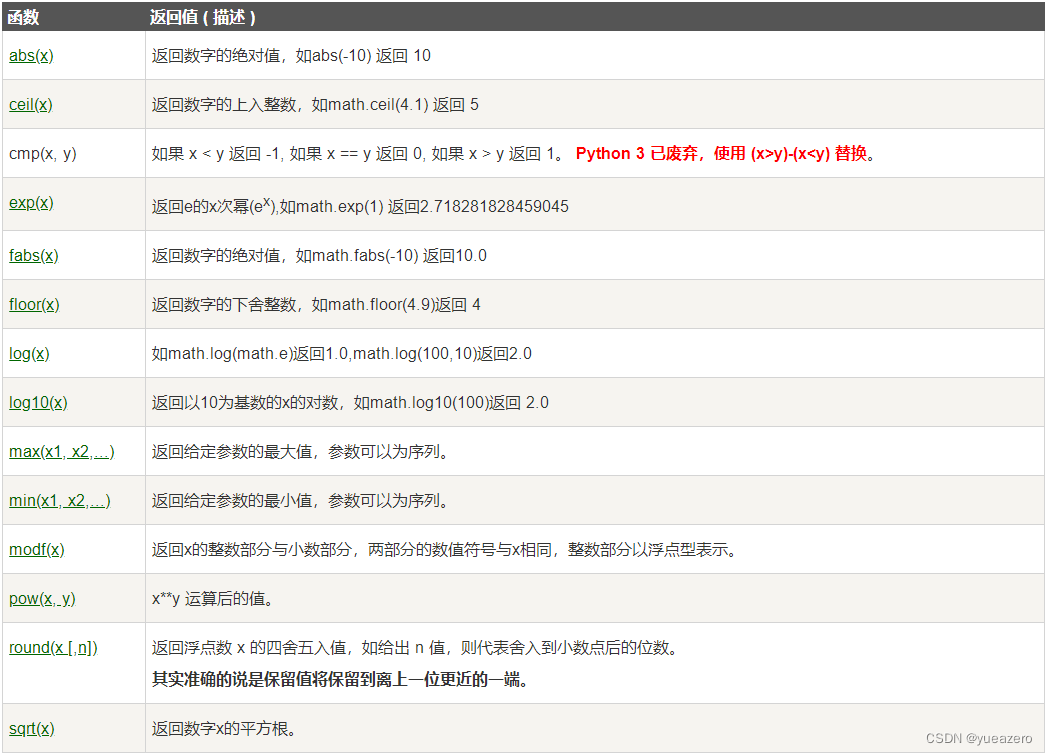
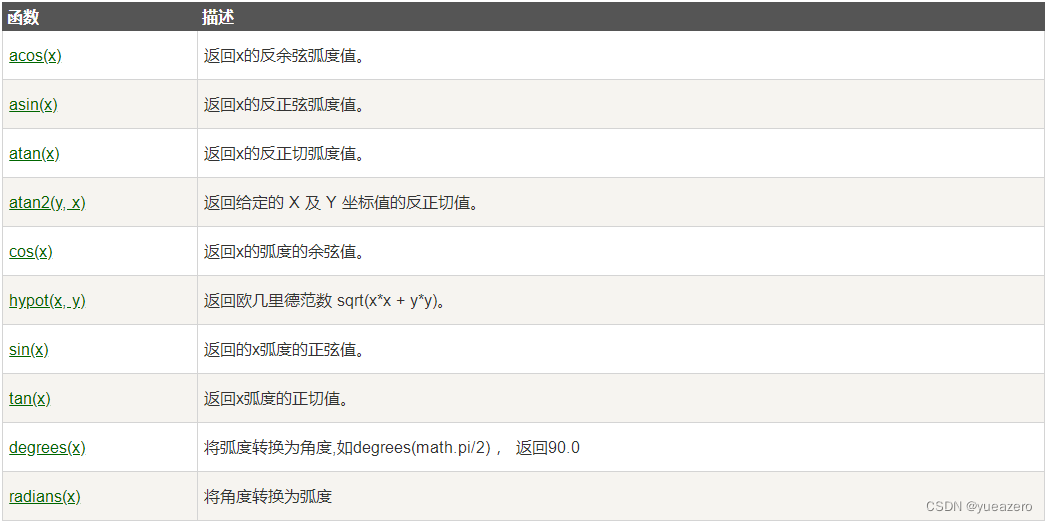
数学函数

字符串(String)
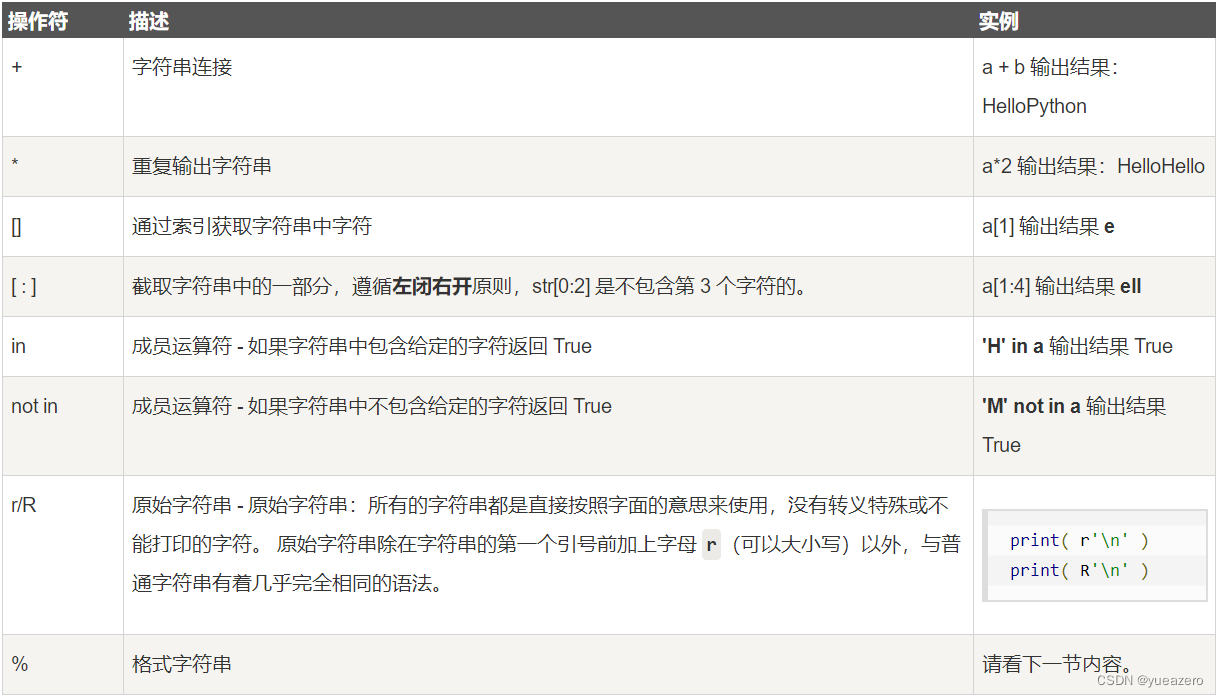
使用引号 ' 或 " 来创建字符串,可以使用方括号 [ ] 来截取字符串,
#变量[头下标:尾下标]
s="abcdefg"
print(s[0:5])
#abcde
print(s[0:-4])
#abc
print(s[-4:-2])
#de运算符
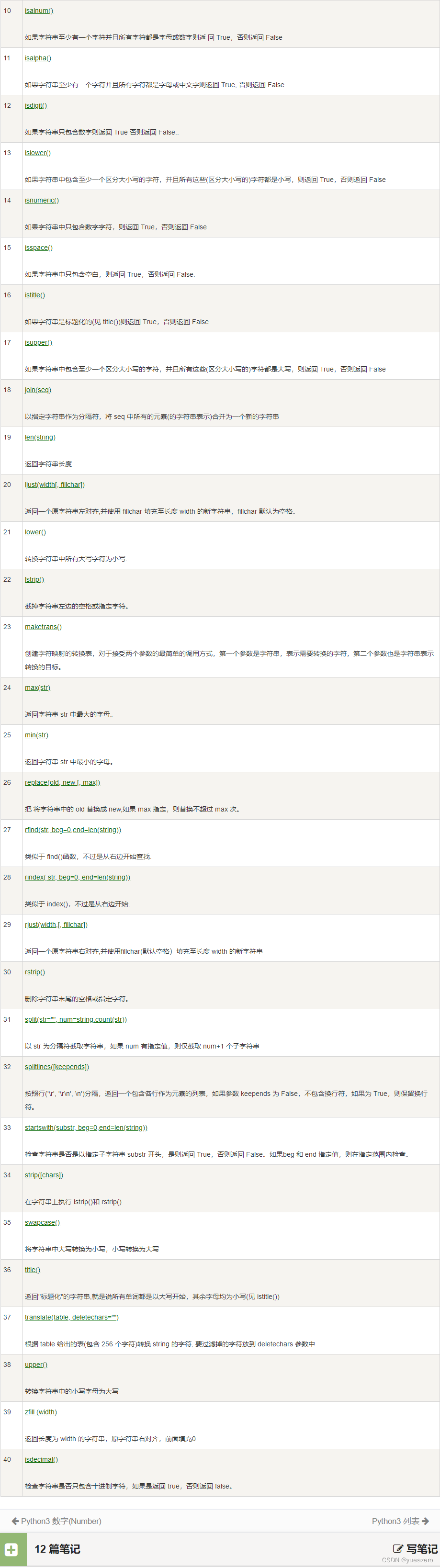
函数

列表(list)
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可,其可嵌套,在列表中创建其他列表。
list=[1,2,3,4,5,6]
print(list[0])
print(list[-2])
print(list[0:-2])
print(list[0:4])
#1 5
#[1,2,3,4]
#[1,2,3,4]
可以直接对列表的数据项进行修改或更新,使用[ ]可以对列表的元素进行修改、替换、删除等操作。也可以使用 append() 方法来添加列表项,用del删除列表中对象。
list=[0,1,2,3,4]
list[len(list)-1]=1 #[0,1,2,3,1]
list[1:-1]=[5,6] #[0,5,6,1]
list[2]=1 #[0,5,1,1]
list[1:-1]=[] #[0,1]
print(list)列表推导式
获取新列表。
list=[1,2,3]
a=[(x**3,x**2) for x in list]
print(a)
# [(1, 1), (8, 4), (27, 9)]对每个元素逐个调用
freshfruit = [' banana', ' loganberry ', 'passion fruit ']
print([weapon.strip() for weapon in freshfruit])
# ['banana', 'loganberry', 'passion fruit']
#等同于下面
for weapon in freshfruit:
print(weapon.strip())
#banana
#loganberry
#passion fruit列表比较
import operator
a = [1, 2]
b = [2, 3]
c = [2, 3]
print("operator.eq(a,b): ", operator.eq(a,b))
print("operator.eq(c,b): ", operator.eq(c,b))
#operator.eq(a,b): False
#operator.eq(c,b): True函数
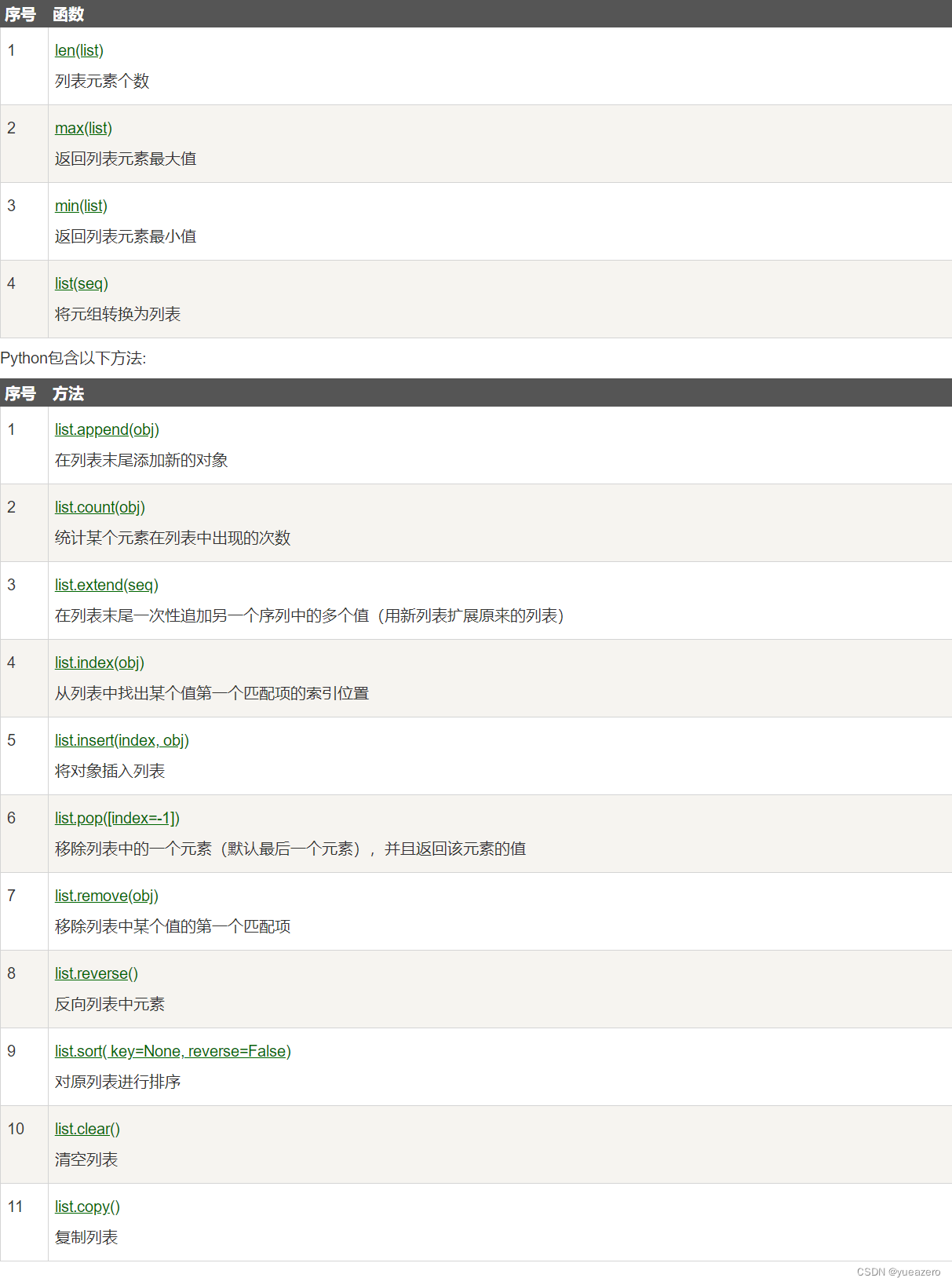
元组(tuple)
创建空元组
tup=()元组中只包含一个元素时,需要在元素后面添加 , ,否则括号会被当作运算符使用。其操作与字符串类似,可进行截取等。元组中的元素值不允许修改的,但可以对元组进行连接组合,也可以使用del删除整个元组。
迭代
for x in (1, 2, 3):
print (x, end=" ")
#1 2 3函数
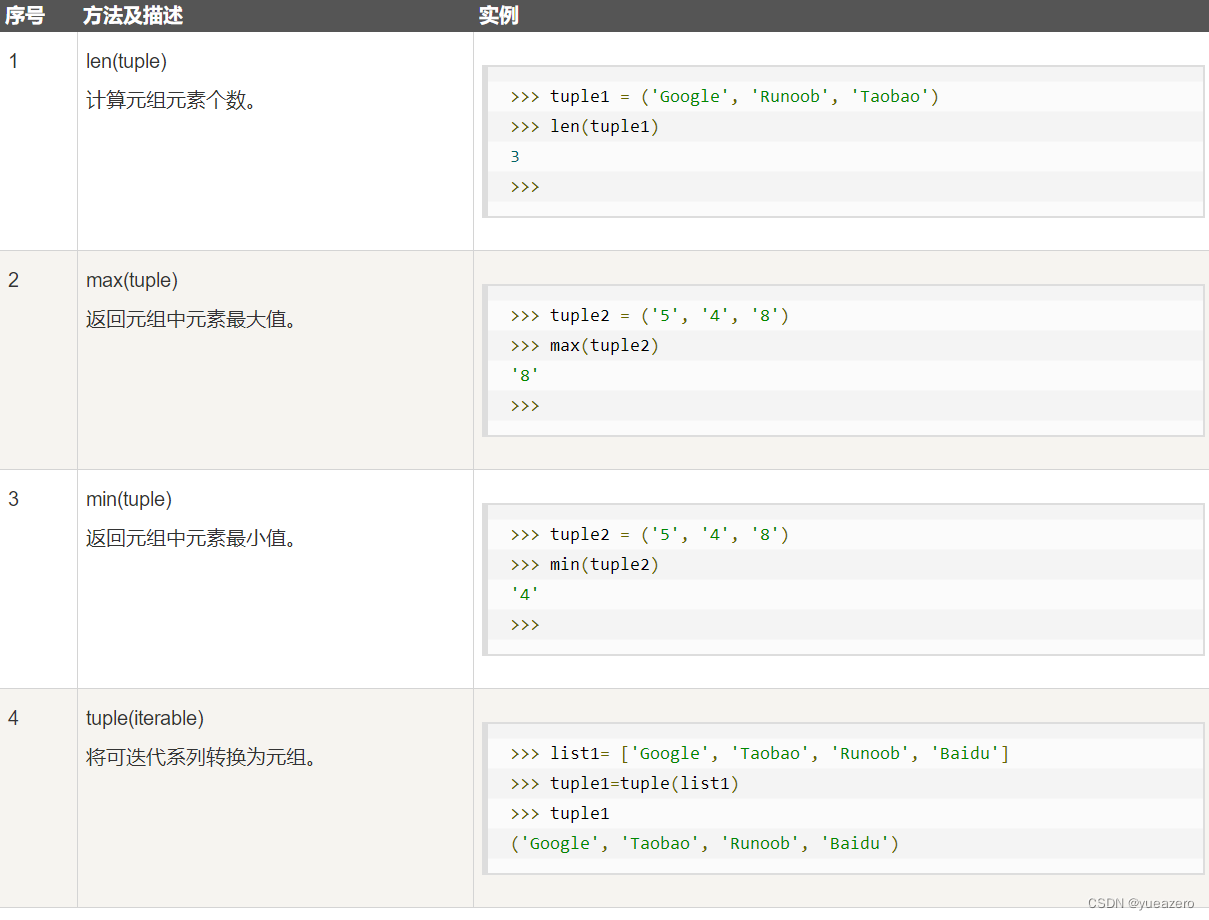
字典(dict)
字典是另一种可变容器模型,且可存储任意类型对象。字典的格式如下所示:
d = {key1 : value1, key2 : value2, key3 : value3 }字典的值可以取任何数据类型,但键必须是不可变的,如字符串,数字。
访问字典,使用键访问。
a={'b':1,'c':2,'d':3}
print(a['b'])
#1字典中不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住。
函数
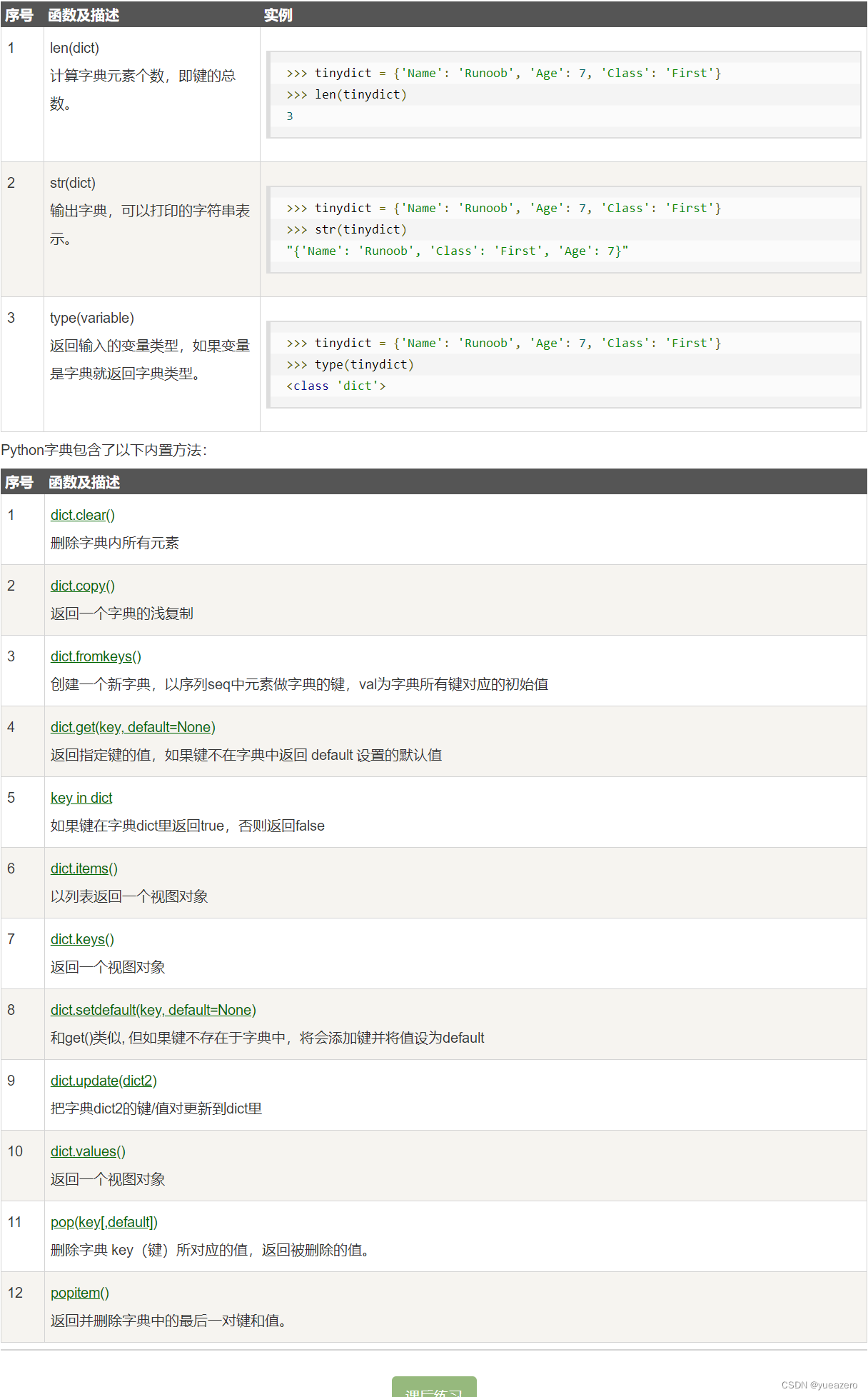
集合(set)
集合是一个无序的不重复元素序列。可以使用大括号 { } 或者 set() 函数创建集合。创建一个空集合必须用 set()。
基本操作
s.add( x )#添加元素。
s.update( x )#添加元素,元素可是列表,元组,字典等,x可用,分隔有多个。
s.remove( x )#移除元素。
s.discard( x )#移除元素。
s.pop() #随机删除s中一个元素.
len(s)#计算集合s中元素个数。
s.clear()#清空集合s。
x in s#判断元素x是否在集合s中,存在返回True,反之返回False。
循环语句
while 循环
while 判断条件(condition):
执行语句(statements)……while 循环使用 else 语句
如果 while 后面的条件语句为 false 时,则执行 else 的语句块。
while <expr>:
<statement(s)>
else:
<additional_statement(s)>
#expr 条件语句为 true 则执行 statement(s) 语句块,如果为 false,则执行additional_statement(s)。for 循环
for <variable> in <sequence>:
<statements>
else:
<statements>可使用break跳出for循环。
range()函数
遍历数字序列,可以使用内置range()函数。
for i in range(5):
print(i)
#0 1 2 3 4
for i in range(5,9) :
print(i)
#指定区间值。
#5 6 7 8
for i in range(0, 10, 3) :
print(i)
#指定区间及增量。
#0 3 6 9
list(range(5))
#使用range()函数来创建一个列表。
#[0, 1, 2, 3, 4]pass 语句
空语句,pass 不做任何事情,一般用做占位语句。
迭代器与生成器
迭代器
访问集合元素的一种方式,是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束,只能往前不会后退。
迭代器有两个基本的方法:iter() 和 next()。
list=[1,2,3,4]
it = iter(list)
print(next(it))#1
for x in it:
print (x, end=" ")
#2 3 4生成器
生成器是一个返回迭代器的函数,只能用于迭代操作.
import sys
def fibonacci(n): # 生成器函数 - 斐波那契
a, b, counter = 0, 1, 0
while True:
if (counter > n):
return
yield a
a, b = b, a + b
counter += 1
f = fibonacci(10) # f 是一个迭代器,由生成器返回生成
while True:
try:
print(next(f))
except StopIteration:
sys.exit()函数
函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 ()。
任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
函数内容以冒号 : 起始,并且缩进。
return [表达式] 结束函数,选择性地返回一个值给调用方,不带表达式的 return 相当于返回 None。
def 函数名(参数列表):
函数体函数中使用参数时,加了星号 * 的参数会以元组(tuple)的形式导入,存放所有未命名的变量参数。加了两个星号 ** 的参数会以字典的形式导入。
匿名函数
lambda [arg1 [,arg2,.....argn]]:expressionsum = lambda arg1, arg2: arg1 + arg2
print(sum(10,20))
#30数据结构
列表
list=[1,2,3,4]
x=6
L=[0,0,0]
i=5
list.append(x) #把一个元素添加到列表的结尾,相当于 a[len(a):] = [x]。
#[1, 2, 3, 4, 6]
list.extend(L) #通过添加指定列表的所有元素来扩充列表,相当于 a[len(a):] = L。
#[1, 2, 3, 4, 6, 0, 0, 0]
list.insert(i, x) #在指定位置插入一个元素。第一个参数是准备插入到其前面的那个元素的索引,例如
#[1, 2, 3, 4, 6, 6, 0, 0, 0]
a.insert(0, x) #会插入到整个列表之前,而 a.insert(len(a), x) 相当于 a.append(x) 。
#[1, 2, 3, 4, 6, 0, 0, 0]
list.remove(x) #删除列表中值为 x 的第一个元素。如果没有这样的元素,就会返回一个错误。
#[1, 2, 3, 4, 6, 0, 0, 0]
list.pop([i]) #从列表的指定位置移除元素,并将其返回。如果没有指定索引,a.pop()返回最后一个元素。元素随即从列表中被移除。
list.clear() #移除列表中的所有项,等于del a[:]。
list.index(x) #返回列表中第一个值为 x 的元素的索引。如果没有匹配的元素就会返回一个错误。
#4
list.count(x) #返回 x 在列表中出现的次数。
#1
list.sort() #对列表中的元素进行排序。
#[0, 0, 0, 1, 2, 3, 4, 6]
list.reverse() #倒排列表中的元素。
#[6, 4, 3, 2, 1, 0, 0, 0]
list.copy() #返回列表的浅复制,等于a[:]。
#[6, 4, 3, 2, 1, 0, 0, 0]将列表当做堆栈使用
用 append() 方法可以把一个元素添加到堆栈顶。用不指定索引的 pop() 方法可以把一个元素从堆栈顶释放出来.
stack=[1,2,3]
stack.append(4)
#1 2 3 4
b=stack.pop()
#4
将列表当作队列使用
from collections import deque
queue = deque(["Eric", "John", "Michael"])
queue.append("Terry")
print(queue)
queue.append("Graham") #增加一个元素。
print(queue)
queue.popleft()
print(queue)
queue.popleft() #表示删除队列中的左边的第一个元素。
queue
#deque(['Eric', 'John', 'Michael', 'Terry'])
#deque(['Eric', 'John', 'Michael', 'Terry', 'Graham'])
#deque(['John', 'Michael', 'Terry', 'Graham'])
嵌套列表
a= [
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
]
print(a)
#[[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]
b=[[row[i] for row in a] for i in range(4)]#将3X4的矩阵列表转换为4X3列表。
print(b)
#[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
模块
模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py。模块可以被别的程序引入,以使用该模块中的函数等功能。模块是可以导入其他模块的。在一个模块(或者脚本,或者其他地方)的最前面使用 import 来导入一个模块,当然这只是一个惯例,而不是强制的。被导入的模块的名称将被放入当前操作的模块的符号表中。
导入模块
想使用 Python 源文件,只需在另一个源文件里执行 import 语句,语法如下:
import module1[, module2[,... moduleN]当解释器遇到 import 语句,如果模块在当前的搜索路径就会被导入。一个模块只会被导入一次,不管你执行了多少次 import。这样可以防止导入模块被一遍又一遍地执行。
搜索路径被存储在 sys 模块中的 path 变量。当前目录指的是程序启动的目录。可以在脚本中修改sys.path来引入一些不在搜索路径中的模块。
temp.py
def pr(a):
print("Hello ",a)
return引入temp模板
import temp
temp.pr("lili")
#Hello lilifrom … import 语句
从模块中导入一个指定的部分到当前命名空间中。这个声明不会把整个fibo模块导入到当前的命名空间中,它只会将fibo里的fib函数引入进来。
from modname import name1[, name2[, ... nameN]]from … import * 语句
把一个模块的所有内容全都导入到当前的命名空间。
from modname import *__name__属性
如果我们想在模块被引入时,模块中的某一程序块不执行,可以用__name__属性来使该程序块仅在该模块自身运行时执行。
if __name__ == '__main__':
print('程序自身在运行')
else:
print('我来自另一模块')
"""
$ python using_name.py
程序自身在运行
$ python
import using_name
我来自另一模块
"""包
包是一种管理 Python 模块命名空间的形式,采用"点模块名称"。比如一个模块的名称是 A.B, 那么他表示一个包 A中的子模块 B 。
在导入一个包的时候,Python 会根据 sys.path 中的目录来寻找这个包中包含的子目录。
目录只有包含一个叫做 __init__.py 的文件才会被认作是一个包,主要是为了避免一些滥俗的名字(比如叫做 string)不小心的影响搜索路径中的有效模块。
最简单的情况,放一个空的 :file:__init__.py就可以了。当然这个文件中也可以包含一些初始化代码或者为(将在后面介绍的) __all__变量赋值。
导入语句遵循如下规则:如果包定义文件 __init__.py 存在一个叫做 __all__ 的列表变量,那么在使用 from package import * 的时候就把这个列表中的所有名字作为包内容导入。
File(文件) 方法
open() 方法
用于打开一个文件,并返回文件对象。如果该文件无法被打开,会抛出 OSError。(此时文件必须为close状态。)
open(file, mode='r')
'''
file: 必需,文件路径(相对或者绝对路径)。
mode: 可选,文件打开模式.
'''














 684
684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









