







👀垂直切分与水平切分
💡什么是切分?
- 出于 降低数据库负载 和 缩表 的目的,通常要对单节点的 MySQL 数据库做切分。
- 对数据库切分的方案:
- 垂直切分:降低数据库负载
- 水平切分:缩表
💡垂直切分
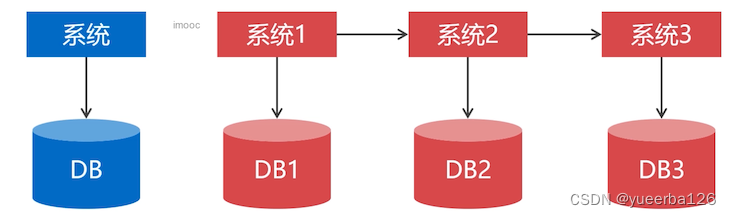
- 垂直切分是 按照业务 对数据表分类,然后把一个数据库拆分成多个独立的数据库。

- 从上到下,将一个数据库拆分成多个数据库。也就是拆分成多个小系统。
✍垂直切分的作用
-
垂直切分可以把数据库的 并发压力,分散 到不同的数据库节点。
-
垂直切分并不能减少单表数据量。
✍垂直切分的缺点
-
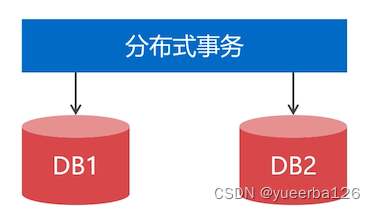
不能跨 MySQL 节点做表连接查询,只能通过接口方式解决。
-
跨 MySQL 节点的事务,需要用 分布式事物机制 来实现
💡水平切分
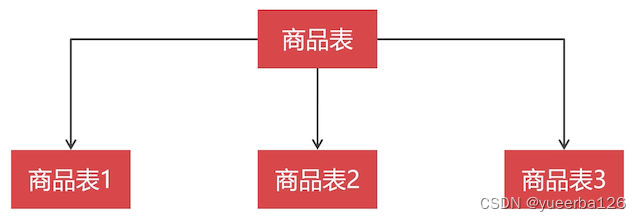
- 水平切分是 按照某个字段的某种规则,把数据切分到多张数据表
-
MySQL 有一种自带的分区技术,将一张表进行分区,按照一定的规则切分到 Linux 不同的目录下,我们给主机挂载多块硬盘,利用分区技术,就把一张表的数据存储在多块硬盘上了。
-
所以:水平切分的表,不一定必须在不同的数据库节点上。
✍水平切分的缺点
-
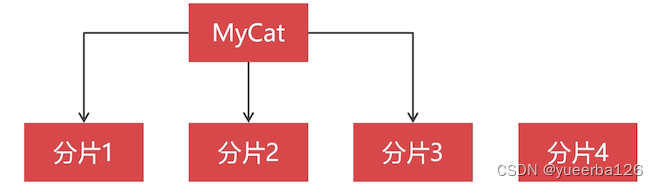
不同数据表的切分规则并不一致,要根据实际业务来确定
-
所以需要选择切分规则丰富的中间件。推荐 MyCat
-
集群扩容麻烦,需要迁移大量的数据
-
随着业务的增长,分片可能会有不够用的时候,但是增加一个分片,要迁移部分数据到新的分片,路由规则计算结果就变化了,所以需要把之前存在的数据都重新路由一下到新的分片中去。
-
这对在线业务影响是巨大的,所以不到万不得已,不要增加分片
✍冷热数据分离
-
添加新的分片,硬件成本和时间成本很大,所以要慎重。
-
可以 对分片数据做冷热数据分离,把冷数据移除分片来缩表。
💡使用垂直还是水平切分?
-
讨论:修改数据库架构,先做垂直切分还是水平切分
-
情况不同,答案不同。
-
从小系统开始,用户越来越多时,先做水平切分,因为这个时候只是将数据库层面做了改动。
-
笔者大大疑问:水平拆分问题那么多,你确定只是在数据库层面改动了?但是相对来说,这种情况下,成本是最小的。
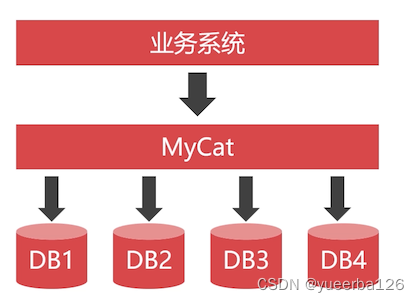
-
水平切分 + 冷热数据分离,再多的数据都能存得下。(笔者现在深有感触,存下了,用怎么办?还没有理解到核心思想)
-
当日活跃用户达到 50 万时,单体架构就支持不下来了。这个时候就需要将单体应用 拆分为多个独立的子系统
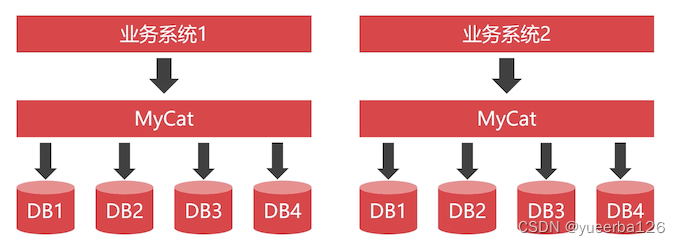
-
垂直拆分成多个独立的子系统后,子系统间的交互等方面有很多工作需要做。
-
所以一定要遵循:从单体项目做起,不断迭代,达到一定日活的时候,再来做垂直切分。
-
但是从一开始你的目标就很明确,至少要扛起日活几十万用户的需求,那么就可以从一开始就垂直切分设计成多个子系统。
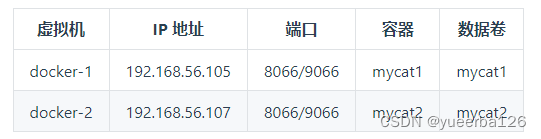
👀安装 MyCat
-
没有官方的 MyCat 镜像,第三方也没有比较出名的,所以我们自己在 Java 容器里面安装
-
没有数据库中间件的年代:通常把数据切分规则记录在数据表,然后通过查询数据表得知,查询的数据保存在什么 MySQL 节点。
-
比如什么类型的商品被切分存储在哪一个节点上。在查询的时候,需要先查询规则表,根据规则再去某一个节点上查找结果。
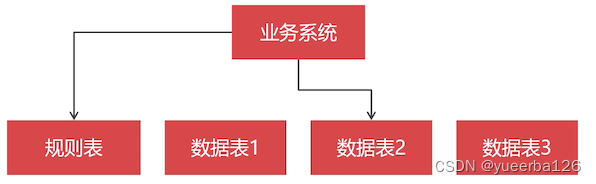
-
有了数据库中间件之后:中间件保存了水平切分的规则,直接可以切分和整合数据
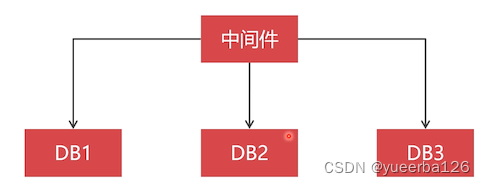
-
当一个查询不带路由规则时,这个查询只能被路由到所有节点查询,然后把结果在中间件中汇聚起来返回,因为中间件不知道去哪台节点上找数据。
💡为什么选 MyCat?
- MyCat 是给予 Java 语言的开源数据库中间件产品,相对于其他中间件产品,MyCat 的切分规则最多,功能最全。
- 数据库中间件产品并不会频繁更新升级,包括数据库的相关的产品也是一样,稳定胜于一切
💡下载 MyCat
💡安装 OpenJDK 镜像
- 前面我们学习时下载的是最小的 OpenJDK 14 的,MyCat 是基于 JDK 1.8 ,所以需要安装 OpenJDK 1.8
docker pull adoptopenjdk/openjdk8
docker tag adoptopenjdk/openjdk8 openjdk8
docker rmi adoptopenjdk/openjdk8
💡创建 Java 容器
- 创建 Java 容器,在数据卷放入 MyCat
# 这里不加 -it 容器不久就会被退出
docker run -d -it --name mycat1
-v mycat1:/root/server --privileged
--net=host # 这里使用的网络是宿主机的网络,不要写 swarm 网络,有可能会链接不上 mysql 节点
openjdk8
- 安装该容器
[root@study ~]# docker run -d -it --name mycat1 -v mycat1:/root/server --privileged --net=host openjdk8
5e16e59c7b29465eccdd570f92d84f61886bc03b14f1536d838064997715854a
- MyCat 使用的端口有:
- 8066 :数据处理,执行的 SQL 等操作
- 9066:获取 MyCat 状态信息
- 防火墙先放行
firewall-cmd --zone=public --add-port=8066/tcp --permanent
firewall-cmd --zone=public --add-port=9066/tcp --permanent
firewall-cmd --reload
systemctl restart docker
- 重启之后,需要注意的是,前面讲到过的 PCX 集群的启动,可以去参考前面的笔记,启动后之后再继续
- 进入数据卷,把 MyCat 放入数据卷中
[root@study _data]# docker volume inspect mycat1
[
{
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/mycat1/_data",
"Name": "mycat1",
"Options": {},
"Scope": "local"
}
]
[root@study _data]# cd /var/lib/docker/volumes/mycat1/_data
# 这里上传看你用的是什么工具了,笔者这里用 rz 命令上传
[root@study _data]# tar -xvf Mycat.tar.gz
[root@study _data]# ls
mycat Mycat.tar.gz
# 进入容器,查看是否能看到 mycat 解压目录了
[root@study _data]# docker exec -it mycat1 bash
root@study:/# cd /root/server/
root@study:~/server# ls
mycat Mycat.tar.gz
👀配置 MyCat
💡高可用 MyCat

- 一个 MyCat 就够用了,另外一个用来做高可用,当一个挂掉之后,另一个可以接上工作。
💡MyCat 部署方案
💡MyCat 主要配置文件
- server.xml
- 配置虚拟账户、虚拟逻辑库、主键生成方式
- schema.xml
- 数据库连接、数据表使用什么路由规则
- rule.xml
- 可自己定制数据切分规则
💡MyCat 到底是什么?
- MyCat 是 MySQL 数据库中间件产品,运行的时候会把自己虚拟成 MySQL 数据库,包括虚拟的逻辑库和数据表。
- 虚拟逻辑库
- 虚拟数据表
- 虚拟账户
💡配置虚拟账户
- server.xml 中配置虚拟账户
<mycat:server>
<user name="admin">
<property name="password">123456</property>
<property name="schemas">neti</property>
</user>
</mycat:server>
- schemas:该虚拟账户能访问的虚拟数据库
💡什么是读写分离
-
数据库中间件把读写任务分别发送给不同节点执行,可以降低单一节点负载;
-
对于 PXC 集群来说,不需要设置读写分离,值做均衡负载即可。(因为 PXC 集群每一个节点都是相同地位)
-
对于 Replication 集群主从节点功能明确,需要做读写分离。写发送到 master,读发送到 Slave
💡配置 PXC 负载均衡
- 修改 server.xml 文件,加入 PXC 负载均衡内容
<dataHost name="pxc1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="p1w1" url="192.168.56.105:9001" user="root"
password="123456">
</writeHost>
<writeHost host="p1w2" url="192.168.56.107:9001" user="root"
password="123456" />
<writeHost host="p1w3" url="192.168.56.108:9001" user="root"
password="123456" />
</dataHost>

- 下面是本此 PXC 集群配置的文件内容
<!-- pxc1 集群--->
<dataHost name="pxc1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="p1w1" url="192.168.56.105:9001" user="root"
password="123456">
</writeHost>
<writeHost host="p1w2" url="192.168.56.107:9001" user="root"
password="123456" />
<writeHost host="p1w3" url="192.168.56.108:9001" user="root"
password="123456" />
</dataHost>
<!-- pxc2 集群--->
<dataHost name="pxc2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="p2w1" url="192.168.56.105:9002" user="root"
password="123456">
</writeHost>
<writeHost host="p2w2" url="192.168.56.107:9002" user="root"
password="123456" />
<writeHost host="p2w3" url="192.168.56.108:9002" user="root"
password="123456" />
</dataHost>
💡配置 Replication 集群读写分离
确认我们的 Replication 方案:Replication 镜像不能配置双向主从同步,所以只能使用一写三读

-
上图是两个方案:
-
一主多从:
- 缺点就是,当主节点挂掉之后,就无法写入数据了
-
多主多从:
- 让两个主节点互为主从同步,A 主节点,下挂 B 从节点,但是 B 主节点设置为主节点,也就是它们互相作为从。
-
使用读写分离时,当写节点宕机后,MyCat 就不会使用它对应的读节点了,因为数据不同步了。
-
对于多住多从的配置,需要我们自己去封装容器,这个也是比较复杂的。所以本节就做一主多从。后续章节再来讲解
-
balance :3 ,启用读写分离功能
<dataHost name="rep1" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="p1w1" url="192.168.56.105:9003" user="root" password="123456">
<readHost host=”r1r1“ url="192.168.56.107:9003" user="root" password="123456"/>
...
</writeHost>
</dataHost>
- 本次 Replication 集群配置
<!-- rep1 集群--->
<dataHost name="rep1" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="p1w1" url="192.168.56.105:9003" user="root" password="123456">
<readHost host="r1r1" url="192.168.56.107:9003" user="root" password="123456"/>
<readHost host="r1r2" url="192.168.56.108:9003" user="root" password="123456"/>
</writeHost>
</dataHost>
<!-- rep2 集群--->
<dataHost name="rep2" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="r2w1" url="192.168.56.105:9004" user="root" password="123456">
<readHost host="r2r1" url="192.168.56.107:9004" user="root" password="123456"/>
<readHost host="r2r2" url="192.168.56.108:9004" user="root" password="123456"/>
</writeHost>
</dataHost>
💡逻辑库配置
-
我们对虚拟表的读写都会路由到真实的物理表上面去。所以配置 dataHost 使用真实数据库上的哪些库
-
标签可以设置使用的真实逻辑库
- name:dataNode 的名称
- dataHost:指向的是我们刚刚配置的集群名称
- database:使用哪一个逻辑库,这个是对应真实数据库中的库名
<dataNode name="dn1" dataHost="pxc1" database="neti"></dataNode>
- 本次配置内容
<!-- 新零售数据库的集群与逻辑库映射 -->
<dataNode name="dn1" dataHost="pxc1" database="neti"></dataNode>
<dataNode name="dn2" dataHost="pxc2" database="neti"></dataNode>
<dataNode name="dn3" dataHost="rep1" database="neti"></dataNode>
<dataNode name="dn4" dataHost="rep2" database="neti"></dataNode>
<!-- 集群与练习库的映射;先拿练习库来练手 -->
<dataNode name="tdn1" dataHost="pxc1" database="t1"></dataNode>
<dataNode name="tdn2" dataHost="pxc2" database="t1"></dataNode>
<dataNode name="tdn3" dataHost="rep1" database="t2"></dataNode>
<dataNode name="tdn4" dataHost="rep2" database="t2"></dataNode>
💡配置虚拟库和虚拟表
- 因为 MyCat 并不存储数据,所以必须要配置可以使用的虚拟逻辑库和关系表。
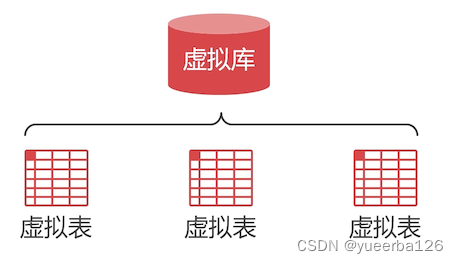
-
schema 标签可以设置虚拟逻辑库
-
table 标签可以设置虚拟关系表
<schema name="t2" checkSQLschema="false" sqlMaxLimit="100">
<table name="teacher" type="global" dataNode="tdn3,tdn4"></table>
<table name="student" rule="mod-long" dataNode="tdn3,tdn4"></table>
</schema>
-
schema 属性:
-
checkSQLschema:是否去掉逻辑库名
- 如 select t2.student ,如果为 true,则会去掉 t2 变成 select student 去真实数据库上执行
-
sqlMaxLimit:每条查询语句最多返回多少条数据
-
table 属性:
-
name:虚拟表名字,这个表对应真实库中的表名
-
type:
-
global:不做水平切分的表;所有节点上都有全部的表数据
-
这里老师的数据比较少,就不用切分了
-
-
dataNode:对应的真实逻辑库
-
rule: 分配规则
-
mod-long :按照主键值求模切分
-
这里用了两个 Replication 集群,如果有 1000 个学生,那么每个集群上会保存 500 条数据
-
-
-
本次配置的内容
<!-- t2 库配置 -->
<schema name="t2" checkSQLschema="false" sqlMaxLimit="100">
<table name="teacher" type="global" dataNode="tdn3,tdn4"></table>
<table name="student" rule="mod-long" dataNode="tdn3,tdn4"></table>
</schema>
<!-- t1 库配置,表也暂时不配置 -->
<schema name="t1" checkSQLschema="false" sqlMaxLimit="100">
</schema>
<!-- 新零售库配置,表暂时不配置 -->
<schema name="neti" checkSQLschema="false" sqlMaxLimit="100">
</schema>
- 对于 schema.xml 中的虚拟账户可使用的逻辑库就需要加上 t1 和 t2 了
<user name="admin">
<property name="password">123456</property>
<property name="schemas">neti,t1,t2</property>
</user>
💡修改 mod-long 算法
-
MyCat 默认的 mod-long 是按照三个分配切分数据,我们这里需要修改下这个默认值;
-
我们这里 t2 库对应的只有两个节点,所以需要修改为 2
-
在 rule.xml 中修改
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">2</property>
</function>
💡本章最终配置一览
✍server.xml
- 其他的配置是很多默认的配置,没有动他们;改动的就是删除了其他的 user 标签,只留下了一个 user 配置
<user name="admin">
<property name="password">123456</property>
<property name="schemas">neti,t1,t2</property>
</user>
✍schema.xml
- 配置文件中标签的顺序也需要注意下,否则会在启动的时候报错
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- t2 库配置 -->
<schema name="t2" checkSQLschema="false" sqlMaxLimit="100">
<table name="teacher" type="global" dataNode="tdn3,tdn4"></table>
<table name="student" rule="mod-long" dataNode="tdn3,tdn4"></table>
</schema>
<!-- t1 库配置,表也暂时不配置 -->
<schema name="t1" checkSQLschema="false" sqlMaxLimit="100">
</schema>
<!-- 新零售库配置,表暂时不配置 -->
<schema name="neti" checkSQLschema="false" sqlMaxLimit="100">
</schema>
<!-- 新零售数据库的集群与逻辑库映射 -->
<dataNode name="dn1" dataHost="pxc1" database="neti"></dataNode>
<dataNode name="dn2" dataHost="pxc2" database="neti"></dataNode>
<dataNode name="dn3" dataHost="rep1" database="neti"></dataNode>
<dataNode name="dn4" dataHost="rep2" database="neti"></dataNode>
<!-- 集群与练习库的映射;先拿练习库来练手 -->
<dataNode name="tdn1" dataHost="pxc1" database="t1"></dataNode>
<dataNode name="tdn2" dataHost="pxc2" database="t1"></dataNode>
<dataNode name="tdn3" dataHost="rep1" database="t2"></dataNode>
<dataNode name="tdn4" dataHost="rep2" database="t2"></dataNode>
<!-- pxc1 集群-->
<dataHost name="pxc1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="p1w1" url="192.168.56.105:9001" user="root" password="123456" />
<writeHost host="p1w2" url="192.168.56.107:9001" user="root" password="123456" />
<writeHost host="p1w3" url="192.168.56.108:9001" user="root" password="123456" />
</dataHost>
<!-- pxc2 集群-->
<dataHost name="pxc2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="p2w1" url="192.168.56.105:9002" user="root" password="123456" />
<writeHost host="p2w2" url="192.168.56.107:9002" user="root" password="123456" />
<writeHost host="p2w3" url="192.168.56.108:9002" user="root" password="123456" />
</dataHost>
<!-- rep1 集群-->
<dataHost name="rep1" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="p1w1" url="192.168.56.105:9003" user="root" password="123456">
<readHost host="r1r1" url="192.168.56.107:9003" user="root" password="123456"/>
<readHost host="r1r2" url="192.168.56.108:9003" user="root" password="123456"/>
</writeHost>
</dataHost>
<!-- rep2 集群-->
<dataHost name="rep2" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="r2w1" url="192.168.56.105:9004" user="root" password="123456">
<readHost host="r2r1" url="192.168.56.107:9004" user="root" password="123456"/>
<readHost host="r2r2" url="192.168.56.108:9004" user="root" password="123456"/>
</writeHost>
</dataHost>
</mycat:schema>
- 这里总结下里面的配置关系:
- dataHost:配置一个物理集群信息;包括该物理集群中哪些节点是写、哪些节点是读节点
- dataNode:配置的是 物理集群中 对应的 物理库;
- 由于一个物理库中的名称是唯一的,但是可以有多张表,后面再映射该库中有哪些表的时候,就会多次用到,该标签抽象出来,被重复使用。
- schema:配置虚拟逻辑库信息
- table:配置是物理库中的表
- 包括表中的数据要以什么规则切分?这些表存储在哪个物理库上中?
✍rule.xml
- 该表中默认配置了很多规则,由于我们目前只用到了一个,其他的都可以删除掉
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">2</property>
</function>
</mycat:rule>
👀启动 MyCat
- 启动时,是否成功启动,可以查看 MyCat 日志文件。
💡Mycat 日志文件
- 主要有:
- console.log
- mycat.log
- 存放路径在:logs 目录,该目录默认不存在,需要先创建
# 进入 mycat 容器
[root@study conf]# docker exec -it mycat1 bash
# 在新版本的 mycat 中,已经默认存在了 logs 目录了
root@study:~# cd /root/server/mycat
# 为 mycat/bin 目录中所有 sh 命令设置最高权限
root@study:~/server/mycat# chmod -R 777 ./bin/*.sh
# 如果报如下错误,应该是发行包有问题,使用命令转下换行符就可以了
root@study:~/server/mycat/bin# ./startup_nowrap.sh
bash: ./startup_nowrap.sh: /bin/sh^M: bad interpreter: No such file or directory
# 在宿主机上使用 dos2unix 命令转换
[root@study bin]# dos2unix ./startup_nowrap.sh
# 启动 mycat
root@study:~/server/mycat/bin# ./startup_nowrap.sh
...
>> "/root/server/mycat/logs/console.log" 2>&1 &
# 也可以看到日志文件的路径的确是 logs 目录
# 查看是否有 mycat 的进程,这里发现没有
root@study:~/server/mycat/bin# ps -a
PID TTY TIME CMD
138 ? 00:00:00 ps
## 在 console.log 中发现如下的日志
Exception in thread "main" java.lang.ExceptionInInitializerError
at io.mycat.MycatStartup.main(MycatStartup.java:53)
Caused by: io.mycat.config.util.ConfigException: schema t1 didn't config tables,so you must set dataNode property!
- 在 schema 中,至少要配置一张表才行。这里我们补全前面的,配置来满足这个要求,修改 schema.xml
<!-- t2 库配置 -->
<schema name="t2" checkSQLschema="false" sqlMaxLimit="100">
<table name="teacher" type="global" dataNode="tdn3,tdn4"></table>
<table name="student" rule="mod-long" dataNode="tdn3,tdn4"></table>
</schema>
<!-- t1 库配置,表也暂时不配置 -->
<schema name="t1" checkSQLschema="false" sqlMaxLimit="100">
<table name="teacher" type="global" dataNode="tdn1,tdn2"></table>
</schema>
<!-- 新零售库配置,表暂时不配置 -->
<schema name="neti" checkSQLschema="false" sqlMaxLimit="100">
<table name="teacher" type="global" dataNode="dn1,dn2"></table>
</schema>
- 需要注意的是:dataNode 中配置的 database 库也需要在对应的物理集群上存在,不然也不会启动成功。
- 再次启动后,还是一样的需要确认:
- mycat 进程运行一分钟后,不消失
- console.log 日志没有报错
- 并出现该日志信息:MyCAT Server startup successfully. see logs in logs/mycat.log
- mycat.log 日志中也没有 error 相关的错误信息
- 如果 dataNode 中的 database 不在物理集群中存在,在在 console.log 中不会出现 successfully 启动成功的信息。
- 而是会在 mycat.log 日志中出现以下的错误信息
2020-06-16 04:54:35.108 WARN [$_NIOREACTOR-0-RW] (io.mycat.backend.mysql.nio.handler.GetConnectionHandler.connectionError(GetConnectionHandler.java:74)) - connect error MySQLConnection [id=59, lastTime=1592283208708, user=root, schema=t1, old shema=t1, borrowed=false, fromSlaveDB=false, threadId=26, charset=latin1, txIsolation=3, autocommit=true, attachment=null, respHandler=null, host=192.168.56.107, port=9002, statusSync=null, writeQueue=0, modifiedSQLExecuted=false]ConnectionException [code=1049, msg=Unknown database 't1']
-
告知说,在对应的 mysql 节点上,找不到 t1 这个库。
-
那么需要将他们创建出来,就可以了
💡使用 navicat 连接 Mycat
- 启动成功之后,使用 Navicat 链接 MyCat
ip:192.168.56.105
端口:8066
用户:admin
密码:123456
用户名和密码是我们在 server.xml 中配置的
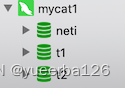
- 可以看到出现了 3 个库了。 但是里面还没有数据表,我们通过 SQL 语句来创建,记住,只能通过 SQL 语句
-- 在 t2 库中创建以下两张表
create table teacher(
id int unsigned primary key,
name varchar(200) not null
);
create table student(
id int unsigned primary key,
name varchar(200) not null
);
-
根据我们的配置,这两张表会在 Replication 两个集群中的 t2 库中存在,可以去检查下是否真的存在;
-
Mycat 会把以上两个 SQL 语句,路由到两个分片节点上去执行,于是就出现在了两个集群中
💡测试表分片
- t2 库中的两个表
<schema name="t2" checkSQLschema="false" sqlMaxLimit="100">
<table name="teacher" type="global" dataNode="tdn3,tdn4"></table>
<table name="student" rule="mod-long" dataNode="tdn3,tdn4"></table>
</schema>
- teacher:是 global 类型,在 两个分片中的数据是一样的
- 测试方式:在 mycat 中往这张表中添加数据,然后去原来的节点上查看 是否有一样的数据
INSERT INTO `t2`.`teacher`(`id`, `name`) VALUES (1, '小强老师');
INSERT INTO `t2`.`teacher`(`id`, `name`) VALUES (2, '张老师');
- 在 tdn3、tdn3 上两条数据都存在;
- 对于路由到哪些分片上了,还可以通过执行计划来查看
EXPLAIN INSERT INTO `t2`.`teacher`(`id`, `name`) VALUES (1, '小强老师');
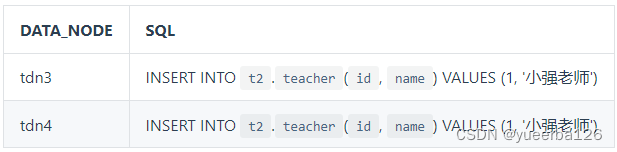
- 可以看到,的确是被路由到两个分片中去了
- student:按主键 ID 取模,路由到两个分片中
- 测试方式:在 mycat 中往这张表中插入数据,然后去原来的节点上查看数据 是否被分片存储了
INSERT INTO `t2`.`student`(`id`, `name`) VALUES (1, '张三');
INSERT INTO `t2`.`student`(`id`, `name`) VALUES (2, '王五');
INSERT INTO `t2`.`student`(`id`, `name`) VALUES (3, '李四');
- 这里插入的数据,id 为 2 的数据被路由到了 tdn4 分片中,其他两条被路由到了 tdn3 分片中
EXPLAIN INSERT INTO `t2`.`student`(`id`, `name`) VALUES (1, '张三');
-- tdn3 tdn3 INSERT INTO `t2`.`student` (`id`, `name`) VALUES ('2', '王五')
👀Mycat 垂直/水平切分/全局表
- 垂直切分和水平切分,前面练习的时候已经实现了
💡垂直切分
- 就是把数据表 切分成独立的逻辑库
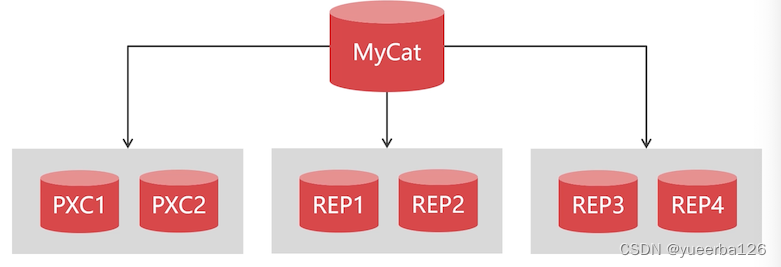
- 将不同的集群划分为一个逻辑库,然后交给 mycat 来管理。
💡水平切分
-
MyCat 具有很多 水平切分算法,用户可以随意定制切分规则。
-
比如前面的 student 表的取模将数据路由到某一个分片上去。
-
下面列出一些水平切分的算法。先混个脸熟
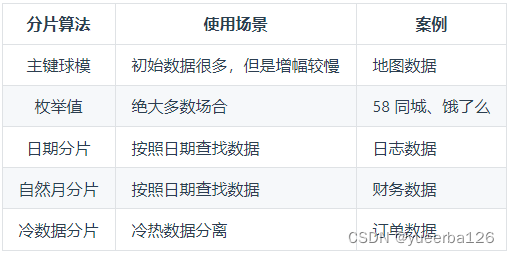
-
枚举值:根据一些值决定路由到哪个分片上
- 比如 58 上浏览网站,需要先让你选择所在城市,然后出现相关的网站内容;招聘、租房等都是按照城市来分片的;
-
日期分片:
- 可以按照天来分片,做数据统计和分析就比较方便;
-
自然月分片:每个月的数据存到一个分片
💡Mycat 性能参数
- 这些都在 Mycat 手册上有相关说明,这里介绍一些,其他的去手册上看
- 每天 2 亿数据的实时查询案例(手册 239 页)
- 物联网 26 亿数据的案例(手册 241 页)
- 大型分布式零售系统案例(首次 241 页)
💡什么是全局表
- 在 Mycat 中,一种是全局表,一种是分片表。
- 数据字典表或则数据量不是很大的业务表,都可以定义成 全局表,在每个分片中的数据都是一样的。
<schema name="t1" checkSQLschema="false" sqlMaxLimit="100">
<table name="teacher" type="global" dataNode="tdn1,tdn2"></table>
</schema>
- 给虚拟表的 type 设置为 global,就是全局表了。
💡全局表的 SQL 路由
-
查询语句:
- 由于所有分片的数据都是一样的,它会随机路由给一个分片执行
-
INSERT、DELETE、UPDATE 语句:
- 会路由给每个分片执行
👀MyCat 路由规则
💡水平切分规则:主键求模
-
功能:可以把数据均匀的切分到分片中。
-
适合场景:适合初始数据量很大,但是数据增幅不大的场合;
-
比如百度地图数据。
✍主键求模切分的缺点
-
数据不分类直接存储,以后维护的成本比较高,例如增加新分片。
-
就算使用数据归档功能,新增数据大于归档速度的时候,就必须添加新分片了。新增分片主要的工作是:数据迁移,之前我们修改过该分片算法的节点数量。新增分片就相当于需要这个数量,该数量改变之后,所有的数据都必须重新路由,否则之前的数据就可能查询不到。因为新路由不一定还会路由到之前的节点上去。
✍底层实现
- 规则的配置在 rule.xml 中
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">2</property>
</function>
-
function 中的 class 指向了该分片算法的实现类。在 tableRule 中定义是使用表中的哪一列、用什么分片算法,作为分片。
-
那么对数据的查询,想要精准的在对应的路由节点上查询数据,就需要出现这个主键 id 的值,比如如下的语句:
-- 出现了主键 id 的值,就可以通过分片算法算出来路由到哪一个分片上执行
INSERT INTO `t2`.`student`(`id`, `name`) VALUES (1, '张三');
-- 这里没有,你通过 explain 查看的话,就会发现,会路由到所有分配上
select id,name from studentl
-- 出现了主键 id,会被精准路由到分片上
select id,name from studentl where id = 1
-- 这也没有,也会路由到所有分片上执行
delete from student where name='A'
💡水平切分规则:枚举值
-
枚举值切分是根据固定字段的枚举值来切分数据。枚举值要提前规定好,而且必须是整数类型。
-
适合场景:比如 58 同城的业务,基于城市提供的服务,将不同城市的数据分到一个分片上,也不用跨分片查询数据
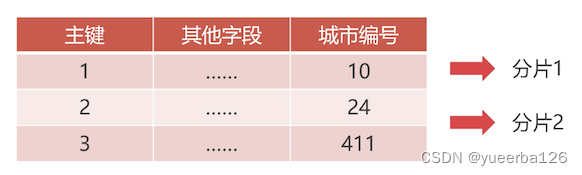
-
比如按城市编号,这里可以设置电话号码的区号,也正好是数值类型的。
✍枚举值文件
-
枚举值文件的需要从 0 开始,0 代表第一个分片,然后依次类推;
-
创建一个 mycat/conf/city.txt 文件,内容为
10=0 22=0 24=1 411=1 -
那么就表示,当城市编号为 10 的时候切分到第一个分片。
✍定义算法 function
-
使用枚举值文件,需要我们自己创建函数来声明使用我们自己的枚举值文件。
-
在 rule.xml 文件中来声明
<function name="partition-by-city" class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">city.txt</property>
</function>
✍定义数据表规则 tableRule
<tableRule name="partition-by-city">
<rule>
<columns>city_id</columns>
<algorithm>partition-by-city</algorithm>
</rule>
</tableRule>
- tableRule.name:该 name 可以用在虚拟表上的 rule 属性中
- rule.columns:定义表中的哪一个字段,使用下面的算法
- rule.algorithm:定义使用哪一个 function,这里是用 function 名称关联的
✍引用切分规则
-
需要声明哪一张表需要使用这个切分规则。
-
在 schema.xml 中的 t2 这个 schema 中增加如下配置
<table name="company" dataNode="tdn3,tdn4" rule="partition-by-city" />
✍使配置生效:热加载
-
要让刚才的配置生效,除了重启 Mycat 之外,还可以使用它的配置文件热加载功能。
-
需要连接上:9066 这个管理端口,就像之前使用 Navicat 连接 mycat 那样连接,只是端口不一样。
-
执行以下语句,重新加载配置文件
reload @@config_all;
-- 执行之后,一定要看返回结果;如果失败,那么就是配置可能写错了,需要去查询问题
-- 但是通过这种方式加载配置文件,貌似看不到错误信息。只能重启,在日志中查看了
✍规则测试
- 先创建表
create table company(
id int unsigned primary key,
name varchar(200) not null,
city_id smallint not null
)
- 插入数据
INSERT INTO `t2`.`company`(`id`, `name`, `city_id`) VALUES (1, 'IBM', 10);
INSERT INTO `t2`.`company`(`id`, `name`, `city_id`) VALUES (2, 'DELL', 22);
INSERT INTO `t2`.`company`(`id`, `name`, `city_id`) VALUES (3, 'HP', 24);
INSERT INTO `t2`.`company`(`id`, `name`, `city_id`) VALUES (4, 'Oracle', 24);
-
然后去具体的数据节点查看这里是否有按照我们规则文件里面配置的进行切分。
-
验证之后,还可以使用 explain 去验证增删改查是否路由正确。
👀避免跨分配表连接:父子表
- 全局表可以与任何分片表做连接。
💡跨分片的表连接
-
跨分片的表连接需要在网络中传输大量的数据,所以 MyCat 不支持跨分片表连接。
-
要实现跨分片表,需要把分片的数据收集到一个分片中执行,传输数据大,也不好实现。
-
mycat 通过父子表解决一定场景下的分片表查询
💡父子表机制
-
两张都是用了水平气氛的数据表,要实现表连接查询,需要定义负责表关系。父表数据切分到什么分片,子表的数据会切分到同样的分片。
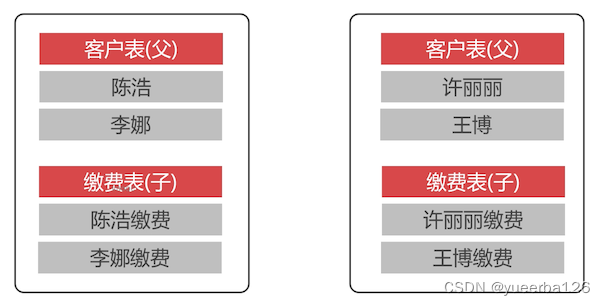
-
比如:客户表和缴费表,在业务上是先有客户,再有缴费。所以需要把客户和缴费,同一个人的路由到相同的分片中,就可以做表连接查询了。
💡配置父子表
- 父表可以有切分规则,但是子表不能配置切分规则。
<table name="customer" primaryKey="ID" dataNode="tdn1,tdn2" rule="sharding-by-city">
<childTable name="payment" primaryKey="ID" joinKey="customer_id" parentKey="id"/>
...
</table>
-
table 属性
-
primaryKey:表主键列名称;是否被缓存的标志
-
使用了 primaryKey,会被 mycat 缓存数据,缓存值就是这个 key
-
rule:使用的数据切分规则
-
childTable 属性:
-
primaryKey:和上面的是一样的
-
joinKey:规定的是子表中的字段
-
parentKey:规定的是父表中的字段
-
joinKey 和 parentKey 定义了父子表用什么字段进行连接查询;类似于外键约束。在数据插入的时候,插入子表数据时,mycat 会去检查父表中是否有对应的 customer_id ,如果没有则会插入出错
-
-
这里在 t1 中增加这个父子表的定义
<schema name="t1" checkSQLschema="false" sqlMaxLimit="100">
<table name="teacher" type="global" dataNode="tdn1,tdn2"></table>
<table name="customer" dataNode="tdn1,tdn2" rule="partition-by-city">
<childTable name="payment" joinKey="customer_id" parentKey="id"/>
</table>
</schema>
💡父子表测试
- 配置文件完成之后,通过 9066 管理端口热加载配置文件
reload @@config_all;
- 在 t1 中创建数据表
-- 客户表
create table customer(
id int unsigned primary key,
name varchar(200) not null,
city_id int unsigned not null
)default charset=utf8;
-- 缴费表
create table payment(
id int unsigned primary key,
customer_id int unsigned not null,
pay decimal(10,2) unsigned not null,
create_time timestamp not null
)default charset=utf8;
- 插入测试数据
-- 往两个分片中各插入了一条客户数据
INSERT INTO `t1`.`customer`(`id`, `name`, `city_id`) VALUES (1, 'Scott', 10);
INSERT INTO `t1`.`customer`(`id`, `name`, `city_id`) VALUES (2, 'Jack', 24);
-- 往 payment 中插入了 3 条数据
-- 客户 1 有两条缴费记录
-- 客户 2 有一条缴费记录
INSERT INTO `t1`.`payment`(`id`, `customer_id`, `pay`, `create_time`) VALUES (1, 1, 50.00, '2020-06-21 07:59:55');
INSERT INTO `t1`.`payment`(`id`, `customer_id`, `pay`, `create_time`) VALUES (2, 1, 99.00, '2020-06-21 07:59:39');
INSERT INTO `t1`.`payment`(`id`, `customer_id`, `pay`, `create_time`) VALUES (3, 2, 100.00, '2020-06-21 08:00:06');
- 那么现在去验证下,在第一个分片中是否存在一条客户为 Scott 的数据,和两条缴费数据。
👀全局主键
- 在数据库集群的场景下,使用数据库主键自增长,会产生重复主键记录。
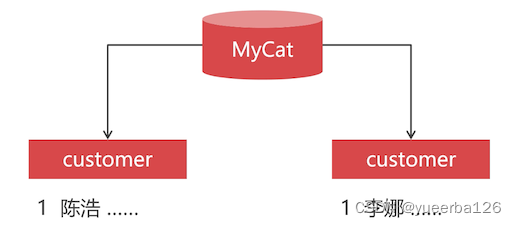
-
在数据库集群环境中,应该使用中间件来生成主键值。
-
Mycat 支持多种 全局主键 生成方式,其中最好的是 Zookeeper 方式。
💡本地文件方式
-
Mycat 按照计数器的放生成自增长的主键值,计数器的参数被保存在文本文件中。
-
最大的缺点就是:无法与其他 Mycat 通信。比如你部署了主备,其中一个挂掉的时候,另外一个启动起来,无法获取到之前的主键参数。
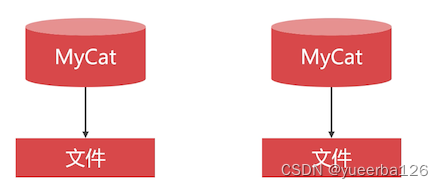
- 这种方式只适合测试中使用;
💡数据库方式
-
和文件方式类似,只是把计数器的参数保存到数据库中。

-
缺点:
- 如果是 pxc 集群:可能会产生一定的性能影响,因为是同步复制
- 如果是 Replication 集群:如果没有同步成功,第一个 mycat 挂掉了,第二个立即启用,会造成主键重复。
💡本地时间戳方式
-
MyCat 根据本地时间戳和机器 ID ,生成一个 18 位的主键值。
-
缺点:因为生成的主键值都是偶数,所以无法用在主键求模切分规则上
💡Zookeeper 时间戳方式
-
利用 Zookeeper 生成时间戳主键值(64 位整数),主键字段必须使用 bigint 类型。
-
可以使用 Zookeeper 集群来保证高可用性。
-
但是如果使用时间戳,本地为什么做不到有奇数和偶数?
💡安装 Zookeeper
- 下载安装 Zookeeper 官方镜像
docker pull zookeeper
- 启动 Zookeeper
docker run -d --name z1
-p 2181:2181
-p 3888:3888
-p 2888:2888
--net=swarm_mysql
zookeeper
- 实践练习
[root@study ~]# docker run -d --name z1 -p 2181:2181 -p 3888:3888 -p 2888:2888 --net=swarm_mysql zookeeper
bab947328f72d32f95728bf99ab02e2f47dd91f93360512316901283df52676a
✍配置 Zookeeper 时间戳主键
- 编辑 server.xml 文件
<property name="sequnceHandlerType">3</property>
- 修改 myid.properties 文件
loadZk=true
zkURL=192.168.56.105:2181
clusterId=mycat-cluster-1
myid=mycat_fz_01
clusterSize=1
clusterNodes=mycat_fz_01
#server booster ; booster install on db same server,will reset all minCon to 2
type=server
# boosterDataHosts=dataHost1
- clusterId:集群名称,可以自己规定
- myid:mycat 主机名,也可以自己定义
- clusterNodes:mycat 集群有几个节点组成,这里对应的是 myid 的值,多个用逗号分隔
- 这里配置 mycat 集群信息。我们这里只有一个 mycat,设置为一个。
✍测试全局主键
- 可以通过管理端口,热加载配置文件
reload @@config_all;
-
由于访问的是本机的 zk,所以不需要放开防火墙。
-
获取全局主键的 sql 语句为
SELECT next value for MYCATSEQ_GLOBAL;
-- 比如返回的主键 ID 是 7326346979595812993
💡把全局主键应用到插入语句中
-
由于主键要求类型为 bigint,这里把 t2 中的 company 表的主键 ID 修改为 bigint 类型;
-
使用主键的插入语句如下
INSERT INTO company ( id, name, city_id )
VALUES
(next VALUE FOR MYCATSEQ_GLOBAL, "test", 411 );

















 812
812











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











