







centos7安装hadoop集群,并实现HA高可用
准备开始
环境准备
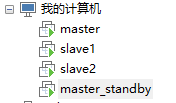
(1)vmware workstation(或VirtualBox)安装四台CentOS7虚拟机,一台master、一台standby master、两台slave
| 机器名 | IP | 软件 | 进程 |
|---|---|---|---|
| master | 192.168.111.100 | jdk、zookeeper、hadoop | namenode(active) |
| slave1 | 192.168.111.101 | jdk、zookeeper、hadoop | datanode、journalnode |
| slave2 | 192.168.111.102 | jdk、zookeeper、hadoop | datanode、journalnode |
| standby | 192.168.111.103 | jdk、hadoop | namenode(standby) |
(2)Oracle JDK1.8.0_191
(3)Zookeeper3.4.12
(4)Hadoop2.8.5
相关知识
(1)linux基础知识和操作命令,如vi、mkdir、cp、mv、tar、wget、scp等等
(2)jdk下载安装和环境变量配置
(3)zookeeper基础原理和功能
(4)Hadoop基础知识,如:HDFS、YARN、NameNode、DataNode、SecondaryNameNode、Standby机制等等
1、JDK1.8安装
1.1、查看及卸载系统自带的jdk版本
(1)执行命令:
java -version

可以看到系统自带的是OpenJDK1.8.0_181,需要先卸载
(2)执行命令:
rpm -qa|grep java
查看已安装的jdk
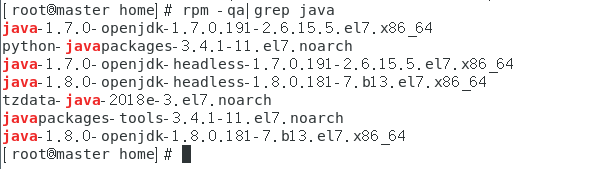
java-1.7.0-openjdk和java-1.8.0-openjdk开头的四个软件,需要手动删除,执行以下命令:
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.191-2.6.15.5.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.191-2.6.15.5.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.181-7.b13.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.181-7.b13.el7.x86_64
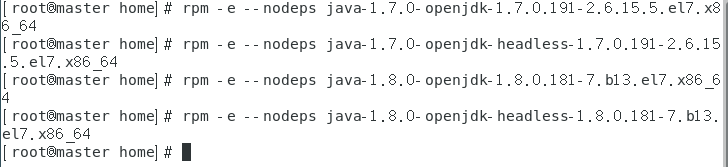
执行命令java -version 和 rpm -qa|grep java 查看是否已经卸载完毕

1.2、安装Oracle jdk1.8.0_191
(1)下载jdk
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
下载 jdk-8u191-linux-x64.tar.gz
(2)上传至虚拟机/home目录
(3)执行命令解压
cd /home
mkdir java
cp ./jdk-8u191-linux-x64.tar.gz ./java
cd java
tar -zxvf jdk-8u191-linux-x64.tar.gz
mv jdk1.8.0_191/ jdk1.8
(4)配置环境变量
vim /etc/profile
编辑/etc/profice,文件内容结尾加上:
export JAVA_HOME=/home/java/jdk1.8
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin

保存并退出vim
刷新配置,执行命令
source /etc/profile
查看当前jdk版本号,执行命令
java -version

JDK已经安装成功了!
其余三台虚拟机执行步骤同上
2、Zookeeper安装
2.1、下载Zookeeper稳定版并解压
cd /home
wget http://mirror.bit.edu.cn/apache/zookeeper/stable/zookeeper-3.4.12.tar.gz
tar -zxvf zookeeper-3.4.12.tar.gz
配置环境变量
vim /etc/profile
export ZK_HOME=/home/zookeeper-3.4.12
export PATH=.:$ZK_HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source /etc/profile
2.2、配置Zookeeper集群
(1)编辑配置文件,首先从zoo_sample.cfg复制一份,命名为zoo.cfg
cd /home/zookeeper-3.4.12/conf/
cp zoo_sample.cfg zoo.cfg
(2)编辑zoo.cfg
创建数据和日志目录:/home/zookeeper-3.4.12/data和/home/zookeeper-3.4.12/logs
mkdir /home/zookeeper-3.4.12/data
mkdir /home/zookeeper-3.4.12/logs
修改zoo.cfg
vim zoo.cfg
原始文件只有以下几个配置
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/tmp/zookeeper
clientPort=2181
修改后的文件内容如下:
tickTime=2000
initLimit=10
syncLimit=5
#日志文件路径
dataLogDir=/home/zookeeper-3.4.12/logs
#数据文件路径
dataDir=/home/zookeeper-3.4.12/data
clientPort=2181
#集群配置
server.1= 192.168.111.100:2888:3888
server.2= 192.168.111.101:2888:3888
server.3= 192.168.111.102:2888:3888
注意,我们一共有四台虚拟机,但是只选了三台做zookeeper做集群,具体原因请自行搜索【Zookeeper集群为什么要是单数】
101和102机器的配置文件zoo.cfg与以上配置相同
(3)创建server.id标识
100、101和102三台机器,分别在各自的/home/zookeeper-3.4.12/data目录下创建文件myid,文件内容为当前机器在集群里的唯一id,如100机器:
vim /home/zookeeper-3.4.12/data/myid
内容为:1,对应于zoo.cfg里的server.1
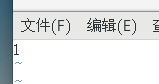
101机器为2,对应于server.2
102机器为3,对应于server.3
保存并退出
2.3、启动zookeeper
三台虚拟机均需启动,执行以下命令:
cd /home/zookeeper-3.4.12/bin
./zkServer.sh start
检查启动状态
./zkServer.sh status


可以看到,并没有启动成功,这时候去日志文件查看什么原因
tail -500f /home/zookeeper-3.4.12/bin/zookeeper.out

一般这种情况,都是端口号不通导致的,三台机器的2181、2888、3888均需开通,我们索性把防火墙直接关闭
systemctl stop firewalld.service
再次测试
master-100机器:
./zkServer.sh status

slave1-101机器:
./zkServer.sh status
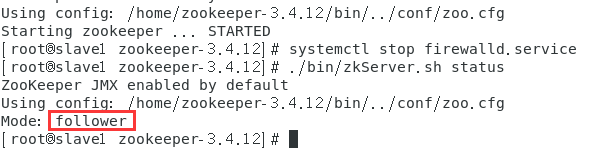
slave2-102机器:
./zkServer.sh status

至此,zookeeper集群环境就搭建完成了,具体的leader和follower机制,请自行学习
2.4、配置成开机自启动
最后一步:将zookeeper配置成开机自启动,减轻运维工作的压力,三台服务器均执行以下命令:
(1)进入/etc/rc.d/init.d目录下,创建zookeeper服务脚本
cd /etc/rc.d/init.d
touch zookeeper
(2)给zookeeper添加可执行权限
chmod +x zookeeper
(3)编辑zookeeper
vim zookeeper
插入如下内容:
#!/bin/bash
#chkconfig:2345 20 90
#description:zookeeper
#processname:zookeeper
export JAVA_HOME=/home/java/jdk1.8
case $1 in
start) su root /home/zookeeper-3.4.12/bin/zkServer.sh start;;
stop) su root /home/zookeeper-3.4.12/bin/zkServer.sh stop;;
status) su root /home/zookeeper-3.4.12/bin/zkServer.sh status;;
restart) su root /home/zookeeper-3.4.12/bin/zkServer.sh restart;;
*) echo "require start|stop|status|restart" ;;
esac

保存并退出,此时就可以通过service命令启动和关闭zookeeper
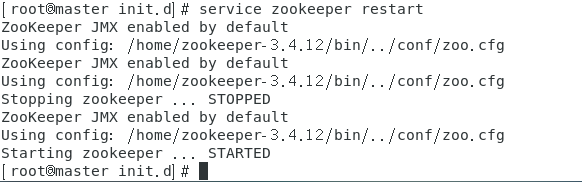
在一台机器上编辑好次文件之后,将此文件scp到其他机器

(4)设置启动项
chkconfig --add zookeeper
查看启动项是否设置成功
chkconfig --list

重启三台机器,验证zookeeper是否开机启动成功

3、虚拟机设置无密码ssh登录
此步骤主要用于Hadoop的namenode和datanode之间、各datanode之间进行通信和文件传输。
3.1、设置别名
一共四台机器,IP分别对应的别名是:
192.168.111.100 master
192.168.111.101 slave1
192.168.111.102 slave2
192.168.111.103 standby
每台机器执行命令:hostname XXXX,XXXX为你要设置的别名,如
hostname master
其他三台机器分别设置自己的hostname
hostname slave1
hostname slave2
hostname standby
3.2、四台机器各自设置hosts映射
vim /etc/hosts
均添加如下内容
192.168.111.100 master
192.168.111.101 slave1
192.168.111.102 slave2
192.168.111.103 standby
测试是否设置成功

3.3、四台机器分别生成id_rsa文件
(1)创建ssh-key,以master为例:
ssh-keygen -t rsa -P ‘’
直接一路回车即可

之后,~/.ssh/下会生成两个文件:id_rsa和id_rsa.pub
cd ~/.ssh/
使用同样的方法分别在其余机器生成其ssh-key
(2)在master上创建一个authorized_keys文件,合并写入四台机器的id_rsa.pub文件内容
touch authorized_keys
cat id_rsa.pub >> authorized_keys

此时只是将本机的id_rsa.pub写入了authorized_keys,需要将其他三台机器的id_rsa.pub也写入authorized_keys
具体方法:可以将其余三台机器的id_rsa.pub输出出来,再复制到master的authorized_keys文件中
如在slave1上操作
cat /root/.ssh/id_rsa.pub
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCi7nyjDakjSsuViKRZLUACQhxE9ajXiO2u9Jx5fHpEerSVGpp8ZVm1Rb+tTgFzdvxYV68feyladZMcwaXHN46ifMDoTsy5e8Aa9f5A9ifgODlQ1AON+64AE6O+MgJ5iNvejeEPgrKF5mvRr3zXGNR05XHkLqFrE0vLDwe3awyGkbccUSBm7kMa0P2ZiWz3Li9a3aO4bySpRnJF8VXexg6H5OvM+YIqamJ4ZzIOUffT1LLWZHmDBSr4ow7J21ugQgS/UunISNHnKm5jOJtatmlQJbfM/PBjWJKz4HbU9PpNd+Qeokg2Zapo5BE5JAYe/9kl04OBG6X4VArjutMntwiJ root@slave1
追加到authorized_keys文件即可,注意每个文件单独占一行,最终效果如下

(3)将合并好的authorized_keys文件复制到其他机器目录/root/.ssh/下
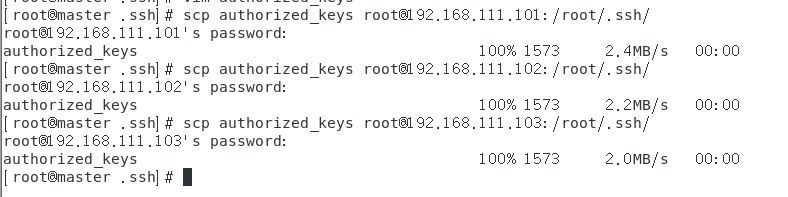
至此,各机器的免密登录均已配置完成,下面测试一下:

测试通过,注意exit退出ssh登录的其他机器
4、Hadoop集群安装
4.1、下载并安装
- 下载并解压
下载地址:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz
选择推荐的地址下载:
cd /home
wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz
tar -zxvf hadoop-2.8.5.tar.gz
- 配置环境变量
vim /etc/profile
增加如下配置:
export HADOOP_HOME=/home/hadoop-2.8.5
export PATH=.:$ZK_HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source /etc/profile
4.2、修改配置文件
- 创建数据目录和日志目录
cd /home/hadoop-2.8.5
mkdir hdfs
mkdir hdfs/tmp
mkdir hdfs/name
mkdir hdfs/data
mkdir journaldata
- 修改如下配置文件
cd /home/hadoop-2.8.5/etc/hadoop

3. 配置core-site.xml
在<configuration></configuration>中增加如下配置:
<!--
指定分布式文件存储系统HDFS的NameService为cluster,是NameNode的URI
-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster</value>
</property>
<!--
用于序列文件缓冲区的大小,这个缓冲区的大小可能是硬件页面大小的倍数,它决定了在读写操作期间缓冲了多少数据
-->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop-2.8.5/hdfs/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave1:2181</value>
</property>
其中hdfs://cluster在hdfs-site.xml中配置,tmp目录和zookeeper集群根据实际情况配置
- 配置hdfs-site.xml
在<configuration></configuration>中增加如下配置:
<property>
<name>dfs.nameservices</name>
<value>cluster</value>
</property>
<property>
<name>dfs.ha.namenodes.cluster</name>
<value>node1,node2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.node1</name>
<value>master:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.node1</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.node2</name>
<value>standby:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.node2</name>
<value>standby:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://slave1:8485;slave2:8485/cluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop-2.8.5/journaldata</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
- 配置mapred-site.xml
在<configuration></configuration>中增加如下配置:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
- 配置yarn-site.xml
在<configuration></configuration>中增加如下配置:
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>standby</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
- 配置 hadoop-env.sh

- 配置 yarn-env.sh
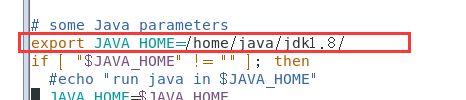
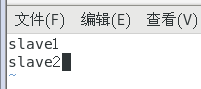
- 配置slaves
改成如下内容:
4.3、将配置好的安装目录拷贝到其他三台服务器
scp -r /home/hadoop-2.8.5 slave1:/home
scp -r /home/hadoop-2.8.5 slave2:/home
scp -r /home/hadoop-2.8.5 standby:/home
4.4、启动
- 格式化namenode【只需执行一次,以后不要再执行】
在master上执行:
./bin/hdfs namenode -format
格式化之后需要把/home/hadoop-2.8.5/hdfs/tmp目录拷给standby相同目录下
- 格式化ZKFC【只需执行一次,以后不要再执行】
在master上执行:
./bin/hdfs zkfc -formatZK
- 启动hdfs
在master上执行:
./sbin/start-dfs.sh
- 启动yarn
在master上执行:
./sbin/start-yarn.sh
- standby服务器启动resourcemanager
在standby上执行:
./sbin/yarn-daemon.sh start resourcemanager
4.5、验证是否启动成功
master、slave1、slave2和standby分别执行
jps




浏览器打开:http://192.168.111.100:50070,查看集群状态

















 4430
4430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









