







最近在做Spark扩展性的测试,使用了CJ-Lin的 http://www.csie.ntu.edu.tw/~cjlin/papers/spark-liblinear/spark-liblinear.pdf 这篇论文,我想重新实现上面的Spark-LIBLINEAR扩展性实验,但是在自己做的时候却发现随着机器数目的增加,我的方法完全没有扩展性,下面是我的spark-env.sh实验配置文件:
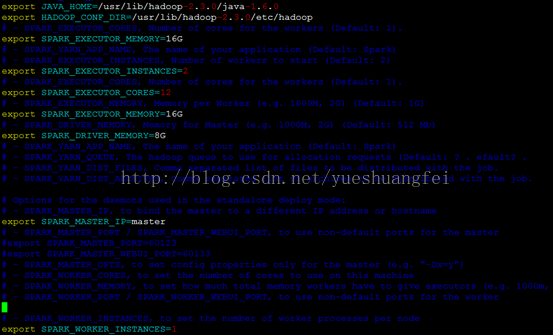
我忽略了一点,这些配置是对应于YARN的分布模式,我自己的机器是standalone模式??
然后我再使用spark-shell spark-shell --master spark://master:7077 --jars "/home/gaopeng/spark-liblinear-1.95/spark-liblinear-1.95.jar" --driver-cores 4 --total-executor-cores 8 --driver-memory 8G --executor-memory 16G (这里的driver-cores其实是yarn中的,我可能用错了)
发现实验的结果还是完全没有扩展性。。。
然后查到了一篇基本配置的博客:http://database.51cto.com/art/201404/435697.htm ,才对配置模式有了大致清楚的了解。在此mark一下。
这边扯一下,关于spark-shell的理解,它其实就是一个application
起初我没有在读数据时显示分块,这导致实际执行时只有两个executor在运行:
val data = Utils.loadLibSVMData(sc, "/user/gaopeng/covtype")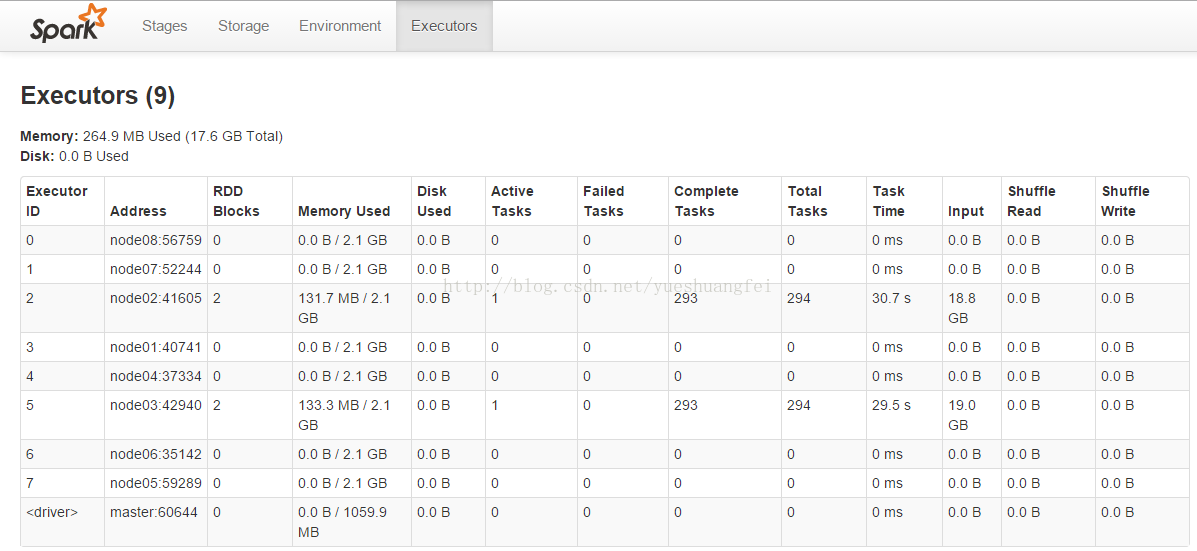
后来,我显示地加了分partition的句子:
val data = Utils.loadLibSVMData(sc, "/user/gaopeng/covtype", 8)
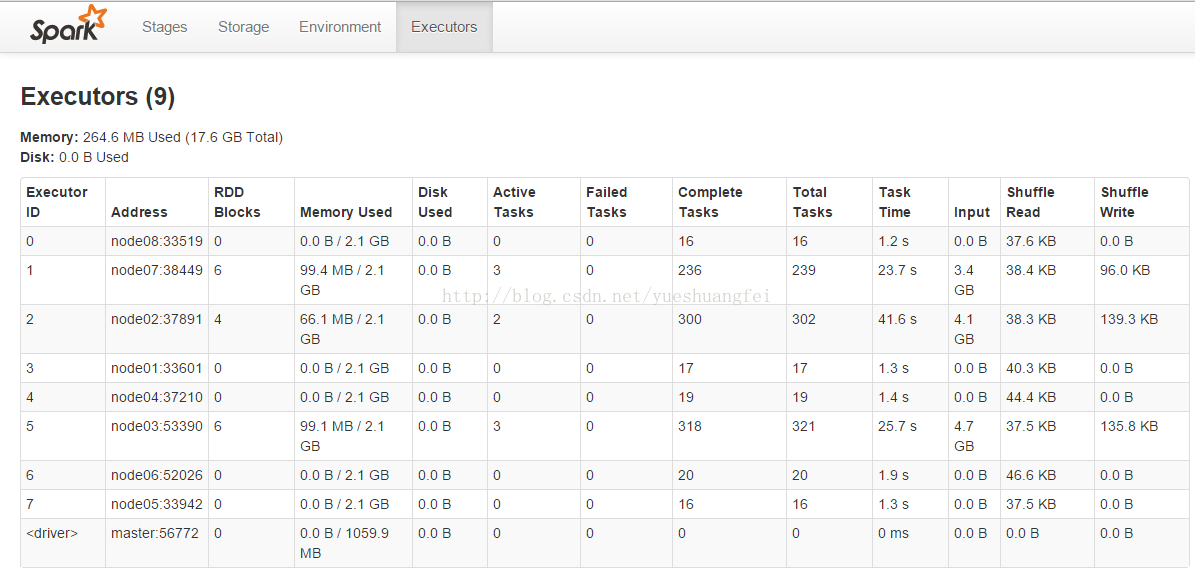
总之,需要对spark文档全面了解才能进行原因的分析。
下面的工作是:
1. 看完点击打开链接CSDN的Spark社区的翻译
2. 看完Spark官网的文档
3. 对实验进行验证,争取实现task的分布均匀。(主要针对小数据集,如covtype、webspam,大数据集可以实现均匀,如epsilon数据集)














 982
982











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









