







 本文详细介绍了Python库pytesseract的安装过程,包括Tesseract-OCR引擎的配置,依赖库Pillow的安装,以及如何通过pytesseract进行中英文文字识别。虽然pytesseract在验证码识别方面的效果一般,但在特定场景下能有效识别屏幕截图中的文字。
本文详细介绍了Python库pytesseract的安装过程,包括Tesseract-OCR引擎的配置,依赖库Pillow的安装,以及如何通过pytesseract进行中英文文字识别。虽然pytesseract在验证码识别方面的效果一般,但在特定场景下能有效识别屏幕截图中的文字。
目录
一、pytesseract简介
tesseract原意为:宇宙魔方;超立方体;超正方体;四维超正方体;四次元立方体
1.1 pytesseract库
pytesseract为Python开源的OCR(光学字符识别)库,能够识别图片上的数字、英文和中文等。
1.2 pytesseract用途
它要求字迹规整、清晰可见,适合识别电脑和手机截屏等。对各种验证码的识别效果一般。
二、pytesseract安装
pytesseract库属于人工智能(AI)领域的库,AI领域的库安装一般都有点麻烦,不是一条pip就能完成的,需要配置底层应用和依赖库。
2.1 安装和配置底层应用Tesseract-OCR
Tesseract-OCR 是一款由HP实验室开发由Google维护的开源OCR(Optical Character Recognition , 光学字符识别)引擎。与Microsoft Office Document Imaging(MODI)相比,我们可以不断的训练的库,使图像转换文本的能力不断增强;如果团队深度需要,还可以以它为模板,开发出符合自身需求的OCR引擎。
2.1.1 GitHub 官网地址:查看源码
https://github.com/tesseract-ocr/tesseract
在这可以查看和下载源码,自己编译,如果不想查看源码,只想直接使用,请下载下面的官网安装包
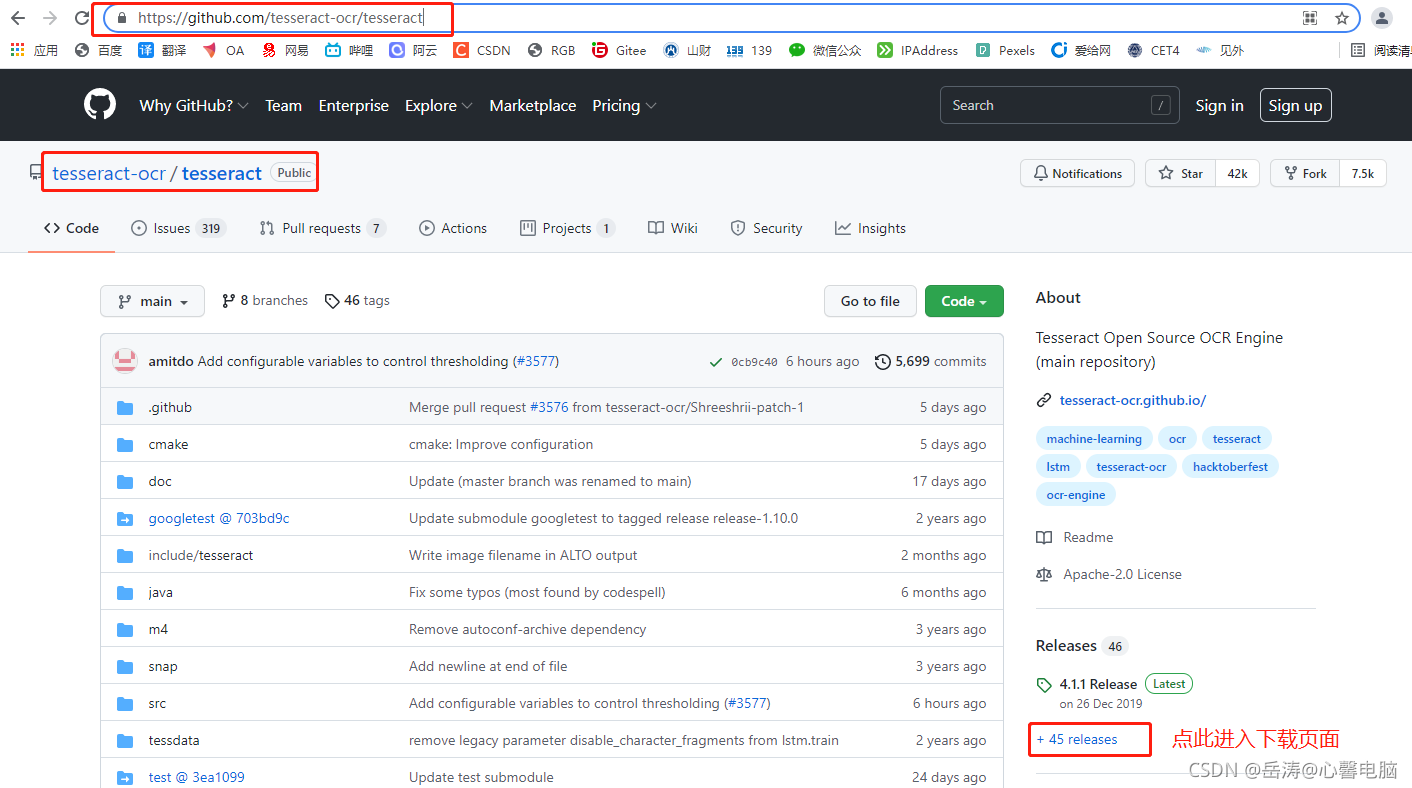
下载简体和繁体识别包:https://github.com/tesseract-ocr/tessdata
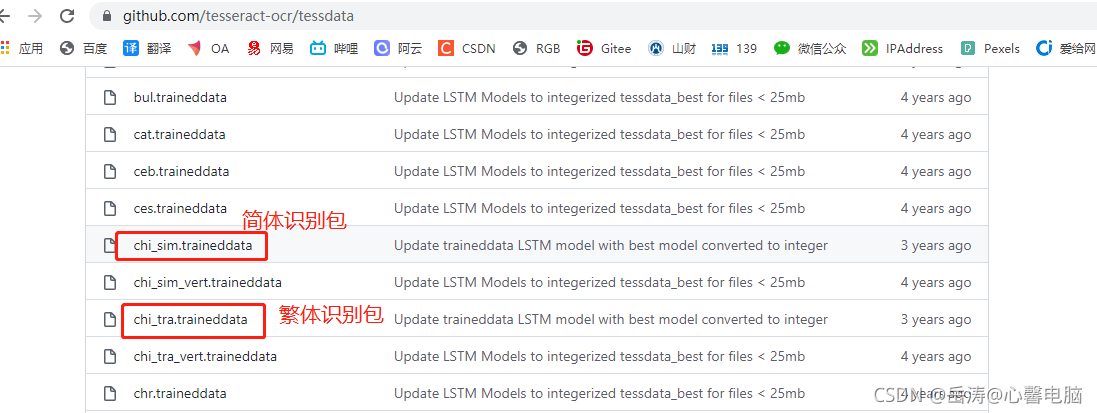
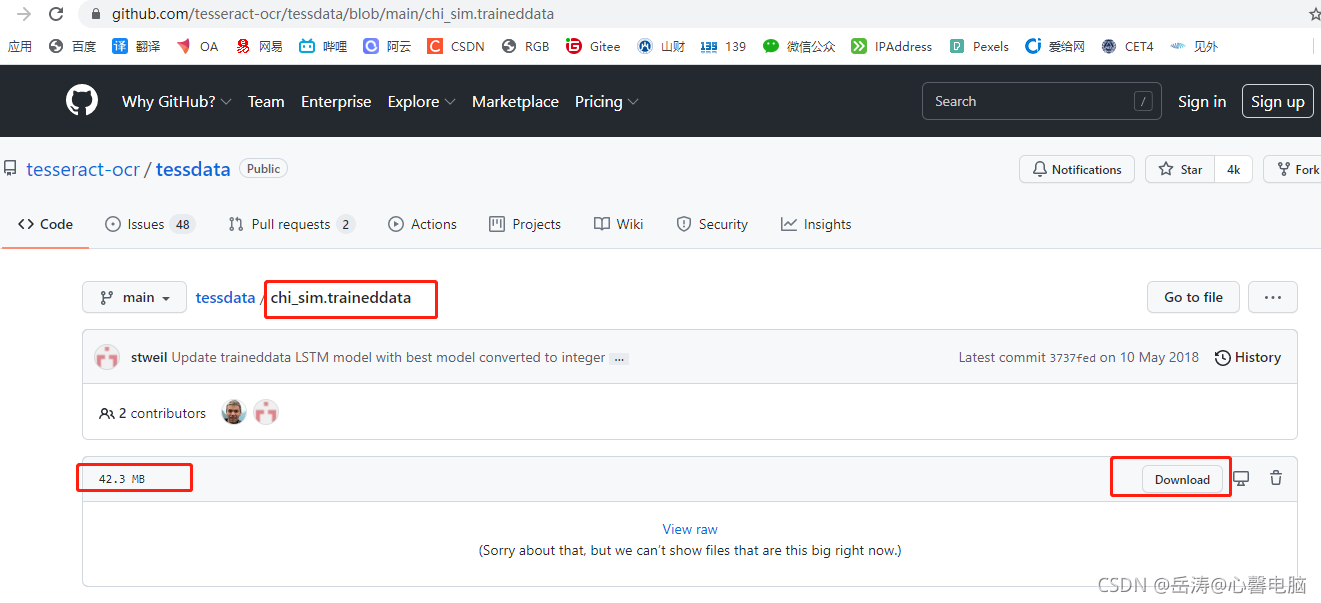
如果不能下载,请自行百度下载吧,这个真的没办法。
2.1.2 官网安装包:下载
https://digi.bib.uni-mannheim.de/tesseract/
拉到最下面,下载适合自己电脑的最新的安装包。
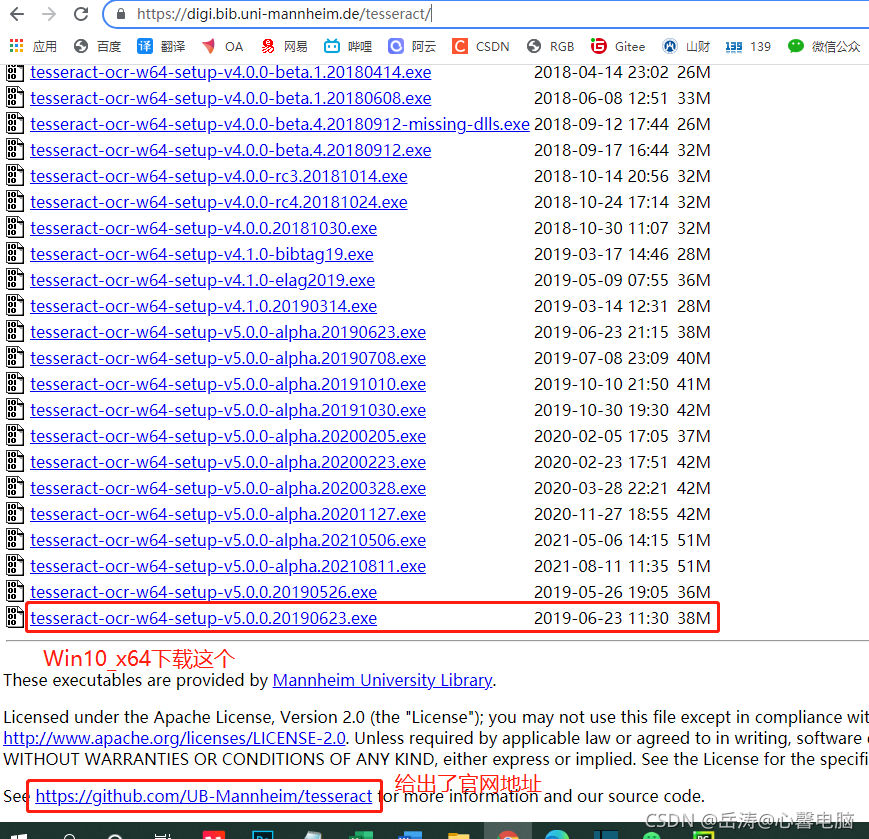
2.1.3 安装Tesseract-OCR
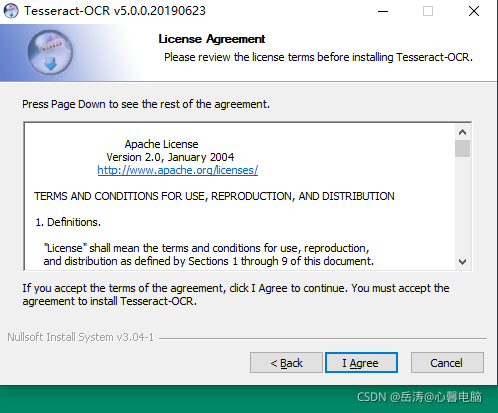
选择组件时,注意把汉字的简繁体都选上,否则识别汉字可能有问题。
Additional script data (download)中选4项
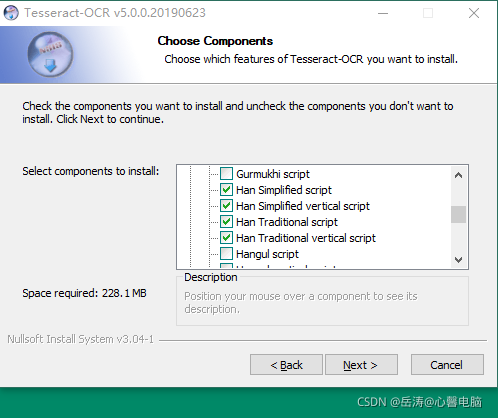
Additional language data (download) 中选四项
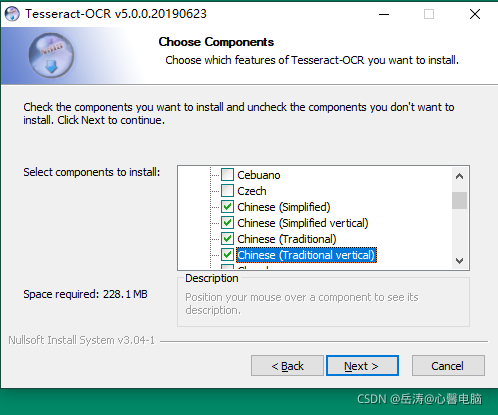
选好组件的效果
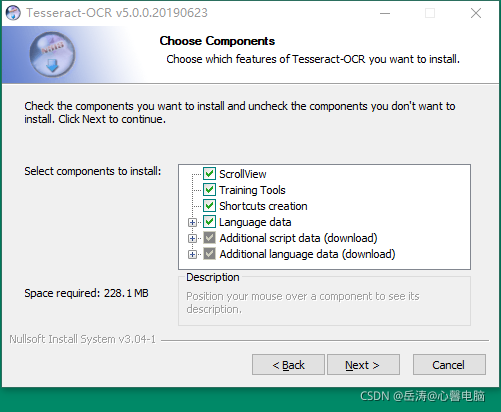
默认安装路径为:C:\Program Files\Tesseract-OCR,如果你修改了,建议复制一下,下面配置环境变量需要用到
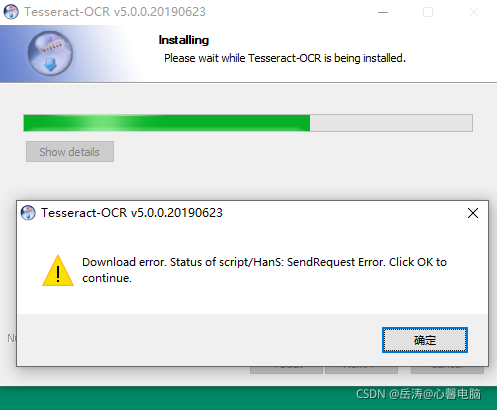
果然下载组件出问题,这个没办法,国内安全机制的问题,OK继续吧,得点8次,直到安装完成。
2.1.4 配置环境变量
- 配置系统变量:path
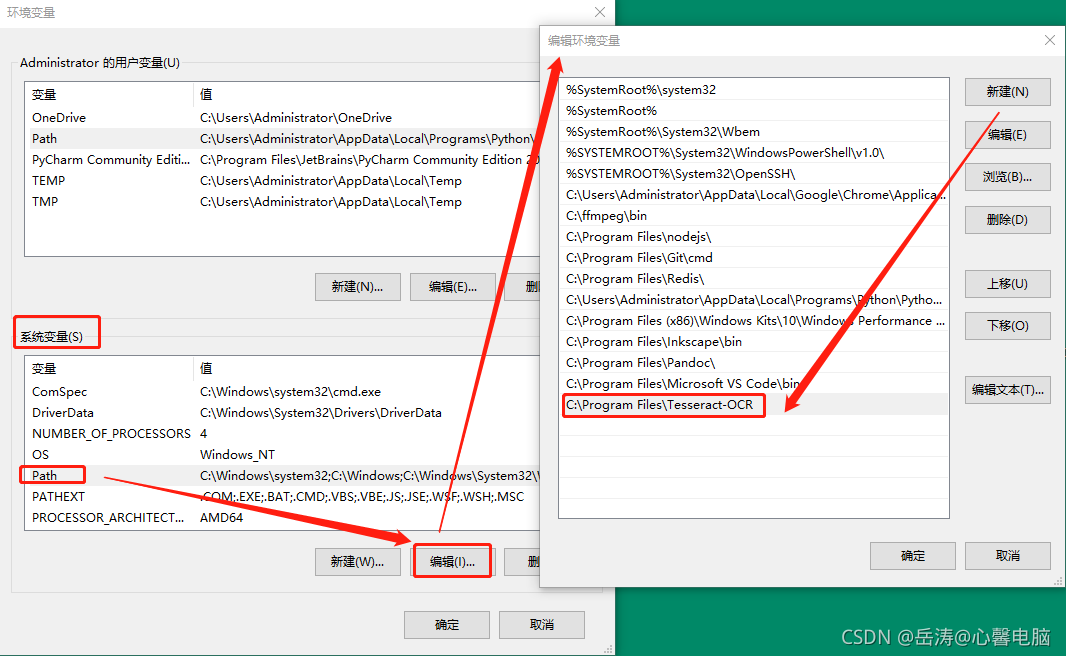
- 添加 TESSDATA_PREFIX 系统变量,值为:C:\Program Files\Tesseract-OCR\tessdata
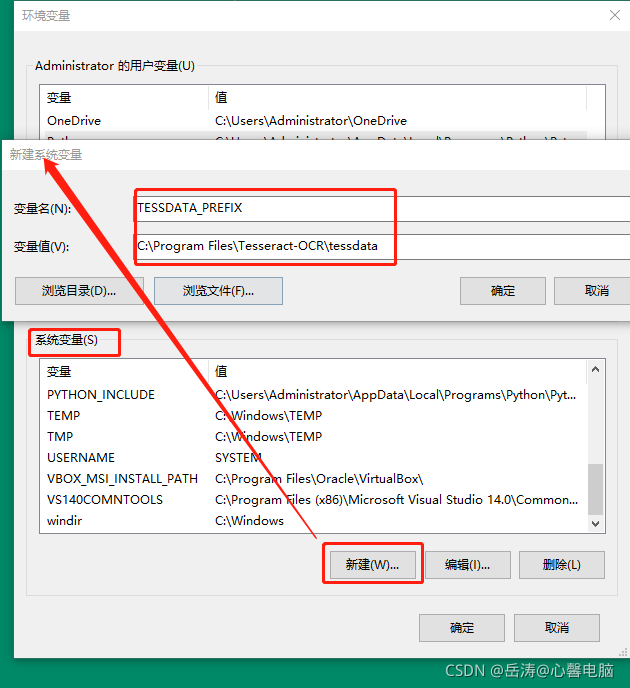
3.配置系统变量:path,新增 %TESSDATA_PREFIX%
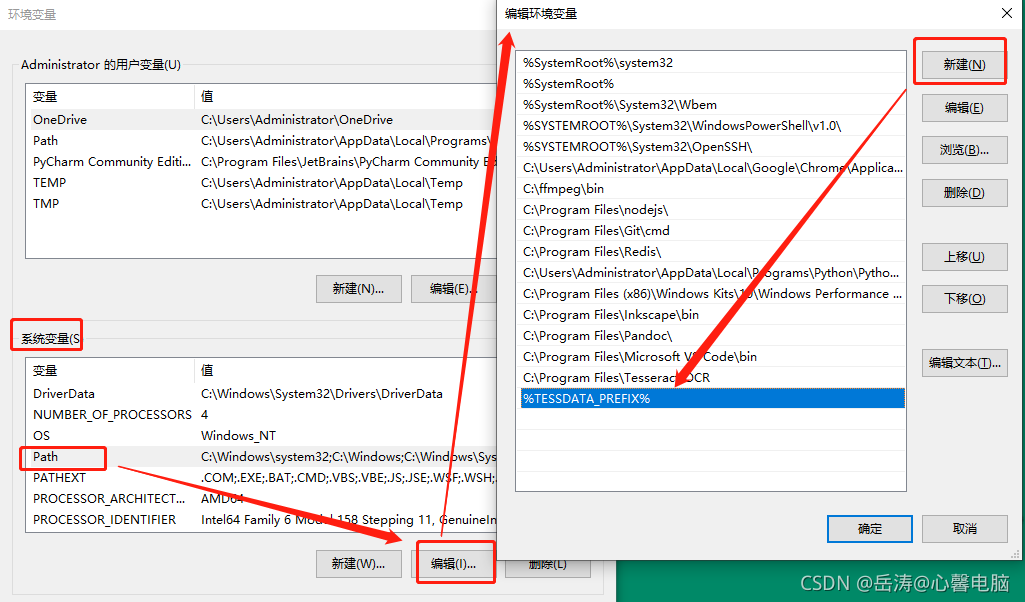
- 重启电脑
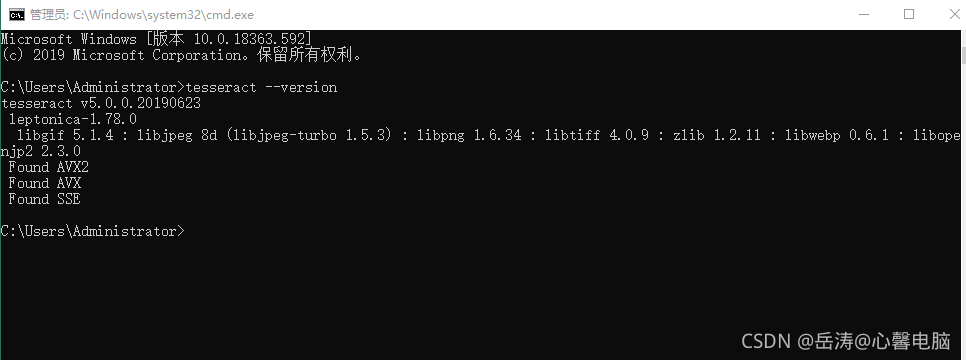
2.1.5 查看Tesseract-OCR是否安装成功
cmd运行输入:tesseract – version,能够正确显示版本号,说明成功。
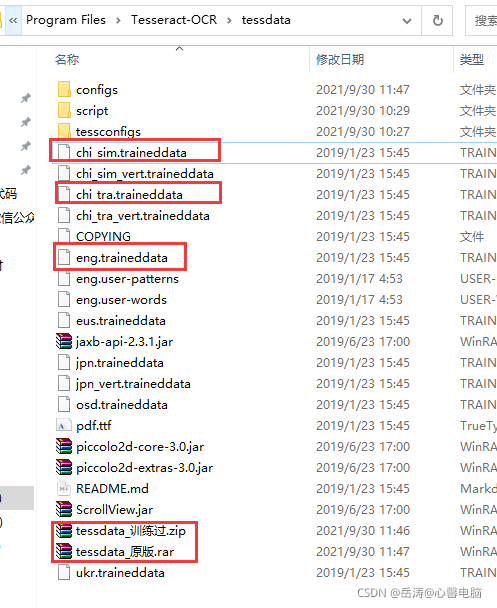
2.1.6 将下载的语言包解压到 C:\Program Files\Tesseract-OCR\tessdata
默认只有英文识别包,所以只能识别英文
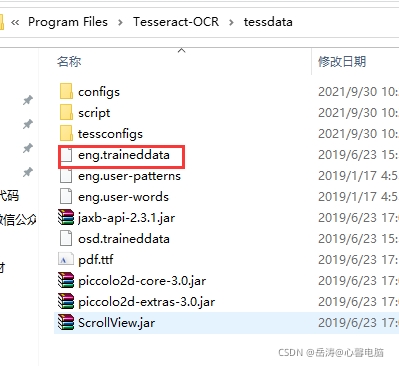
解压后可以识别各国文字,其中包括中文简体和繁体
2.2 安装依赖库Pillow
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pillow
我原来装过了

2.3 安装pytesseract库
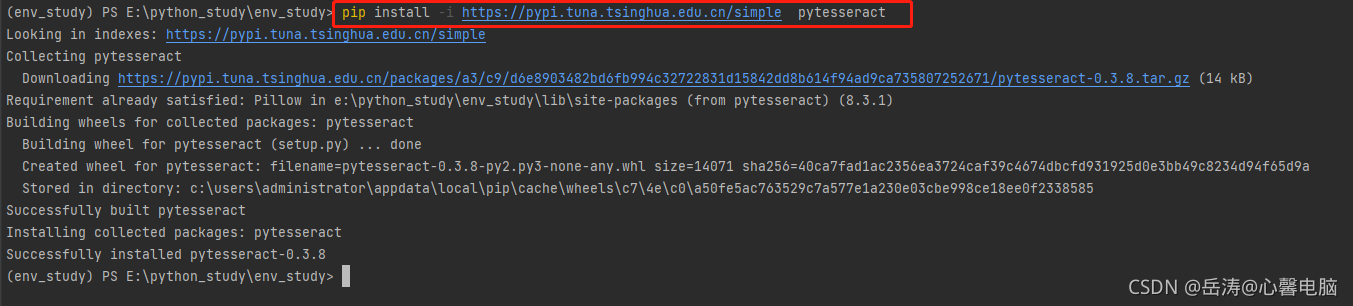
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pytesseract
pytesseract库非常小,只有14K,它只要是调用前面的Tesseract-OCR
三、实例测试
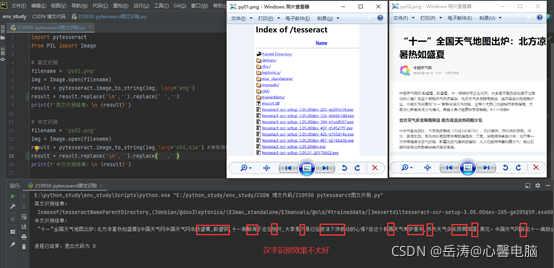
编写中英文测试代码
import pytesseract
from PIL import Image
# 英文识别
filename = 'py01.png'
img = Image.open(filename)
result = pytesseract.image_to_string(img, lang='eng')
result = result.replace('\n','').replace(' ','')
print(f'英文识别结果:\n {result}')
# 中文识别
filename = 'py02.png'
img = Image.open(filename)
result = pytesseract.image_to_string(img,lang='chi_sim') #使用简体中文解析图片
result = result.replace('\n','').replace(' ','')
print(f'中文识别结果:\n {result}')
运行成功,但是汉字识别效果并不理想,和百度的在线OCR还是有很大差距的。原打算进一步发掘一下,看来得缓缓了。


















 1874
1874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











