







一、概念
1.1、数仓
数据仓库之父比尔·恩门(Bill Inmon)在1991年出版的“Building the Data Warehouse”(《建立数据仓库》)一书中所提出的定义被广泛接受,数据仓库是一个面向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策。
OLTP和OLAP
- OLTP:on-line transaction proccessing,联机事务处理,主要是业务数据,需考虑高并发,考虑事务。主要应用于关系型数据库;
- OLAP:on-line analytical proccessing,联机分析处理,主要面向复杂分析,会产生大量查询,很少增删改。主要应用于数据仓库。
1.2、离线数仓
离线数仓,其实简单点来说,就是原来的传统数仓,数据以T+1的形式计算好放在那里,给前台的各种分析应用提供算好的数据。到了大数据时代,这种模式被称为“大数据的批处理”。

1.3、实时数仓
实时数仓一般是将上游业务库的数据通过binlog等形式,实时抽取到Kafka,进行实时ETL。
离线和实时数仓对比

技术要求
- 高并发性:未来的实时数据一定不是仅仅给几个运营或管理层人员使用,会面向更多的群体,那么用户增加的情况下一定会带来并发量的提升,因此实时数仓一定要具备提供高并发数据服务的能力。
- 查询速度:目前很多实时指标的应用场景都希望能够毫秒级返回,对响应速度要求很高。
- 处理速度:要保证在流量峰值的情况下有极强的处理能力,并且具备消费低延迟性甚至0延迟。
技术基础
目前流式计算框架相对成熟,以Flink、Storm、Spark Streaming为代表的开源组件也被广泛应用。流式数据处理,简单来讲,就是系统每产生一条数据,都会被立刻采集并发送到流式任务中心进行处理,不需要额外的定时调度来执行任务。
流式框架具备以下优点:
- 时效性高:延迟粒度通常在秒级;
- 任务常驻:流式任务一旦启动,就会一直运行,直到人为终止,且数据源是无界的;
- 处理性能高:流式计算通常会采用较好的服务器来运行任务,因为一旦处理吞吐量赶不上采集吞吐量,就会出现数据计算延迟;
- 逻辑简单:由于流式计算通常是针对单条数据做处理,缺乏数据之间的关联运算能力,所以在支持的业务逻辑上相对简单,并且处理结果会与离线存在一定的差异。
二、应用场景

2.1、实时 OLAP 分析
OLAP 分析本身就非常适合用数仓去解决的一类问题,我们通过实时数仓的扩展,把数仓的时效性能力进行提升。甚至可能在分析层面上都不用再做太多改造,就可以使原有的 OLAP 分析工具具有分析实时数据的能力。
2.2、实时数据看板
这种场景比较容易接受,比如天猫双11的实时大屏滚动展示核心数据的变化。
2.3、实时特征
实时特征指通过汇总指标的运算来对商户或者用户标记上一些特征。比如多次购买商品的用户后台会判定为优质用户。另外,商户销售额高,后台会认为该商户商的热度更高。然后,在做实时精准运营动作时可能会优先考虑类似的门店或者商户。
2.4、实时业务监控
可以对一些核心业务指标进行监控,比如说当线上出现一些问题的时候,可能会导致某些业务指标下降,我们可以通过监控尽早发现这些问题,进而来减少损失。
三、技术架构
3.1、Lambda 架构
为了计算一些实时指标,就在原来离线数仓的基础上增加了一个实时计算的链路,并对数据源做流式改造(即把数据发送到消息队列),实时计算去订阅消息队列,直接完成指标增量的计算,推送到下游的数据服务中去,由数据服务层完成离线&实时结果的合并。
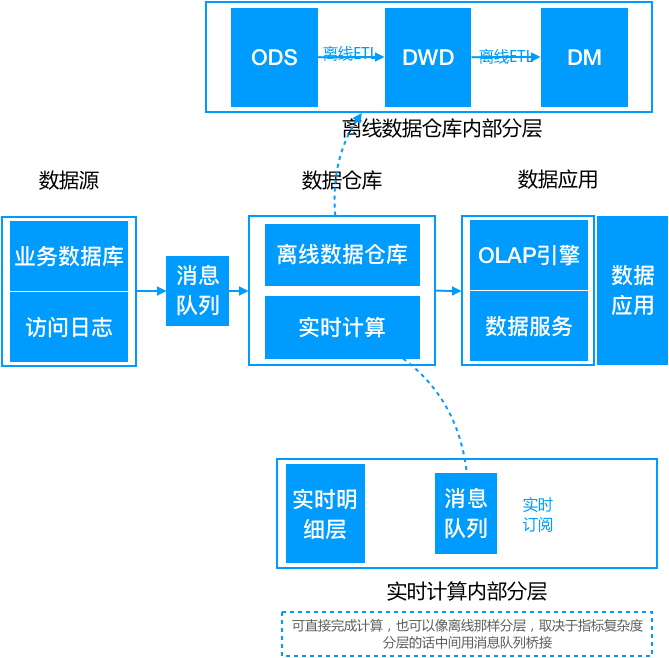
3.2、Kappa 架构
Lambda 架构虽然满足了实时的需求,但带来了更多的开发与运维工作,其架构背景是流处理引擎还不完善,流处理的结果只作为临时的、近似的值提供参考。后来随着 Flink 等流处理引擎的出现,流处理技术很成熟了,这时为了解决两套代码的问题,LickedIn 的 Jay Kreps 提出了 Kappa 架构。
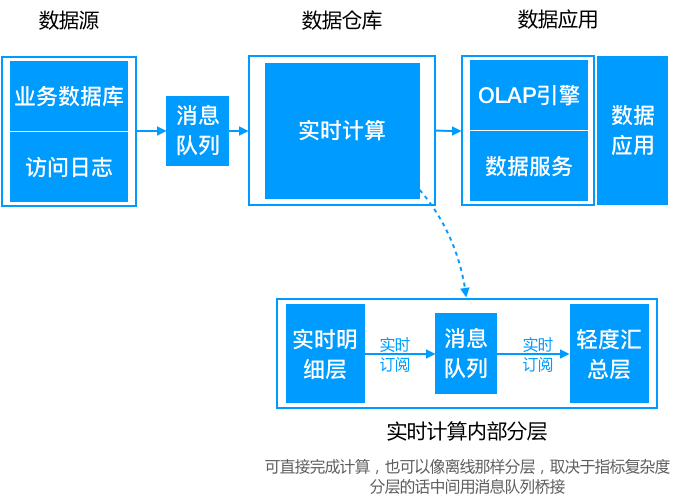
3.3、实时数据生产 + 实时分析引擎

上图是美团实时数仓架构设计,数据从日志统一采集到消息队列,再到数据流的 ETL 过程,作为基础数据流的建设是统一的。之后对于日志类实时特征,实时大屏类应用走实时流计算。对于 Binlog 类业务分析走实时 OLAP 批处理。美团实时数仓架构主要是将一些在实时处理面临的难点,由实时 OLAP 处理。
3.4、架构对比
| Lambda 架构 | Kappa 架构 | 实时OLAP | |
|---|---|---|---|
| 计算引擎 | 流批两套计算引擎 | 流计算引擎 | 流计算引擎 |
| 开发成本 | 高,需要维护实时,离线两套代码 | 低,只需要维护一套代码 | 低,只需要维护一套代码 |
| OLAP分析灵活性 | 中 | 中 | 高 |
| 计算资源 | 需要批流两套计算资源 | 只需流计算资源 | 流计算资源 |
四、技术选型
4.1、存储引擎
实时数仓在设计中不同于离线数仓在各层级使用同种储存方案,比如都存储在 Hive 、DB 中的策略。首先对中间过程的表,采用将结构化的数据通过消息队列存储和高速 KV 存储混合的方案。实时计算引擎可以通过监听消费消息队列内的数据,进行实时计算。而在高速 KV 存储上的数据则可以用于快速关联计算,比如维度数据。 其次在应用层上,针对数据使用特点配置存储方案直接写入。避免了离线数仓应用层同步数据流程带来的处理延迟。 为了解决不同类型的实时数据需求,合理的设计各层级存储方案,对以下几种方案做了对比。
| 方案 | 优势 | 劣势 |
|---|---|---|
| MySQL | 1. 具有完备的事务功能,可以对数据进行更新。2. 支持 SQL,开发成本低。 | 1. 横向扩展成本大,存储容易成为瓶颈; 2. 实时数据的更新和查询频率都很高,线上单个实时应用请求就有 1000+ QPS;使用 MySQL 成本太高。 |
| Elasticsearch | 1. 吞吐量大,单个机器可以支持 2500+ QPS,并且集群可以快速横向扩展。2. Term 查询时响应速度很快,单个机器在 2000+ QPS时,查询延迟在 20 ms以内。 | 1. 没有原生的 SQL 支持,查询 DSL 有一定的学习门槛;2. 进行聚合运算时性能下降明显。 |
| Druid | 1. 支持超大数据量,通过 Kafka 获取实时数据时,单个作业可支持 6W+ QPS;2. 可以在数据导入时通过预计算对数据进行汇总,减少的数据存储。提高了实际处理数据的效率;3. 有很多开源 OLAP 分析框架。实现如 Superset。 | 1. 预聚合导致无法支持明细的查询;2. 无法支持 Join 操作;3. Append-only 不支持数据的修改。只能以 Segment 为单位进行替换。 |
| Cellar | 1. 支持超大数据量,采用内存加分布式存储的架构,存储性价比很高;2. 吞吐性能好,经测试处理 3W+ QPS 读写请求时,平均延迟在 1ms左右;通过异步读写线上最高支持 10W+ QPS。 | 1. 接口仅支持 KV,Map,List 以及原子加减等;2. 单个 Key 值不得超过 1KB ,而 Value 的值超过 100KB 时则性能下降明显。 |
根据不同业务场景,实时数仓各个模型层次使用的存储方案大致如下:

4.2、计算引擎
在实时平台建设初期时,很多企业使用 Storm 引擎来进行实时数据处理。Storm 引擎虽然在灵活性和性能上都表现不错。但是由于 API 过于底层,在数据开发过程中需要对一些常用的数据操作进行功能实现。比如表关联、聚合等,产生了很多额外的开发工作,不仅引入了很多外部依赖比如缓存,而且实际使用时性能也不是很理想。同时 Storm 内的数据对象 Tuple 支持的功能也很简单,通常需要将其转换为 Java 对象来处理。对于这种基于代码定义的数据模型,通常我们只能通过文档来进行维护。不仅需要额外的维护工作,同时在增改字段时也很麻烦。综合来看使用 Storm 引擎构建实时数仓难度较大。我们需要一个新的实时处理方案。
| 项目/引擎 | Storm | Flink | spark-Streaming |
|---|---|---|---|
| API | 灵活的底层 API 和具有事务保证的 Trident API | 流 API 和更加适合数据开发的 Table API 和 Flink SQL 支持 | 流 API 和 Structured-Streaming API 同时也可以使用更适合数据开发的 Spark SQL |
| 容错机制 | ACK 机制 | State 分布式快照保存点 | RDD 保存点 |
| 状态管理 | Trident State状态管理 | Key State 和 Operator State两种 State 可以使用,支持多种持久化方案 | 有 UpdateStateByKey 等 API 进行带状态的变更,支持多种持久化方案 |
| 处理模式 | 单条流式处理 | 单条流式处理 | Mic batch处理 |
| 延迟 | 毫秒级 | 毫秒级 | 秒级 |
| 语义保障 | At Least Once,Exactly Once | Exactly Once,At Least Once | At Least Once |
虽然使用 Strom 引擎也可以处理结构化数据。但毕竟依旧是基于消息的处理 API ,在代码层层面上不能完全享受操作结构化数据的便利。而 Flink 不仅支持了大量常用的 SQL 语句,基本覆盖了我们的开发场景。而且 Flink 的 Table 可以通过 TableSchema 进行管理,支持丰富的数据类型和数据结构以及数据源。可以很容易的和现有的元数据管理系统或配置管理系统结合。通过下图我们可以清晰的看出 Storm 和 Flink 在开发统过程中的区别。
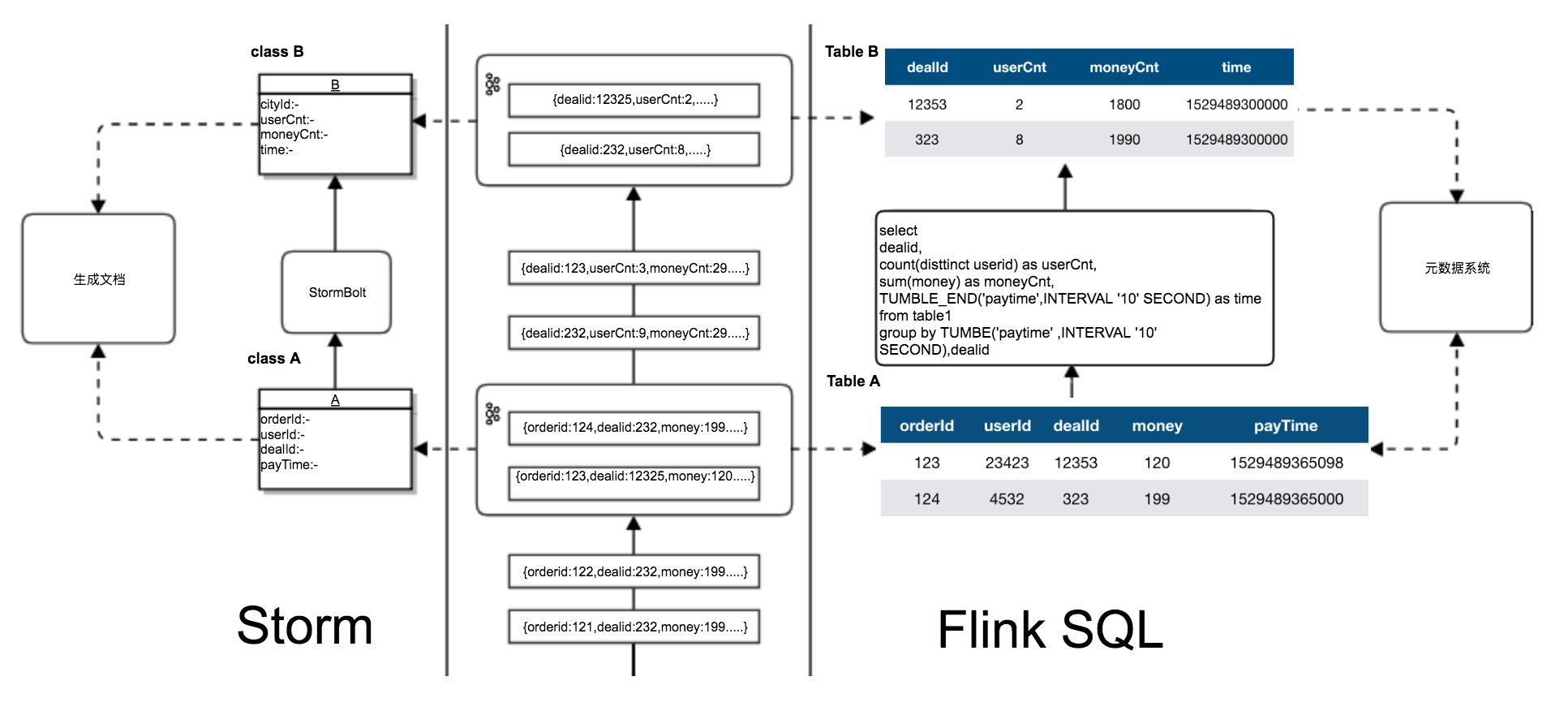
五、体系架构

整个实时数据体系架构分为五层,分别是接入层,存储层,计算层、平台层和应用层,上图只是整体架构的概要图,每一层具体要做的事情,接下来通过文字来详述。
- 接入层:该层利用各种数据接入工具收集各个系统的数据,包括 binlog 日志、埋点日志、以及后端服务日志,数据会被收集到 Kafka 中;这些数据不只是参与实时计算,也会参与离线计算,保证实时和离线的原始数据是统一的;
- 存储层:该层对原始数据、清洗关联后的明细数据进行存储,基于统一的实时数据模型分层理念,将不同应用场景的数据分别存储在 Kafka、HDFS、Kudu、 Clickhouse、Hbase、Redis、Mysql 等存储引擎中,各种存储引擎存放的具体的数据类型在实时数据模型分层部分会详细介绍;
- 计算层:计算层主要使用 Flink、Spark、Presto 以及 ClickHouse 自带的计算能力等四种计算引擎,Flink 计算引擎主要用于实时数据同步、 流式 ETL、关键系统秒级实时指标计算场景,Spark SQL 主要用于复杂多维分析的准实时指标计算需求场景,Presto 和 ClickHouse 主要满足多维自助分析、对查询响应时间要求不太高的场景;
- 平台层:在平台层主要做三个方面的工作,分别是对外提供统一查询服务、元数据及指标管理、数据质量及血缘;
- 应用层:以统一查询服务对各个业务线数据场景进行支持,业务主要包括实时大屏、实时数据产品、实时 OLAP、实时特征等。
六、模型分层

离线数仓考虑到效率问题,一般会采取空间换时间的方式,层级划分会比较多;实时数仓考虑到实时性问题,分层则越少越好,另外也减少了中间流程出错的可能性,因此将其分为四层。
ODS 层:
操作数据层,保存原始数据,对非结构化的数据进行结构化处理,轻度清洗,几乎不删除原始数据;
该层的数据主要来自业务数据库的 binlog 日志、埋点日志和应用程序日志;
对于 binlog 日志通过 canal 监听,写到消息队列 Kafka 中,对应于埋点和应用程序日志,则通过 Filebeat 采集 nginx 和 tomcat 日志,上报到Kafka 中;
除了存储在 Kafka 中,同时也会对业务数据库的 binlog 日志通过 Flink 写入 HDFS、Kudu 等存储引擎,落地到 5min Hive 表,供查询明细数据,同时也提供给离线数仓,做为其原始数据;另外,对于埋点日志数据,由于 ODS 层是非结构化的,则没有必要落地。
DWD 层:
实时明细数据层,以业务过程作为建模驱动,基于每个具体的业务过程特点,构建最细粒度的明细层事实表;可以结合企业的数据使用特点,将明细事实表的某些重要维度属性字段做适当冗余,也即宽表化处理;
该层的数据来源于 ODS 层,通过简单的 Streaming ETL 后得到,对于 binlog 日志的处理主要进行简单的数据清洗、处理数据漂移,以及可能对多个 ODS 层的表进行 Streaming Join,对流量日志主要是做一些通用ETL 处理,将非结构化的数据结构化,关联通用的维度字段;
该层的数据存储在消息队列 Kafka 中,同时也会用 Flink 实时写入 Hive 5min 表,供查询明细数据,同时要提供给离线数仓,做为其原始数据。
DIM 层:
- 公共维度层,基于维度建模理念思想,建立整个业务过程的一致性维度,降低数据计算口径和算法不统一风险;
- DIM 层数据来源于两部分:一部分是Flink程序实时处理ODS层数据得到,另外一部分是通过离线任务出仓得到;
- DIM 层维度数据主要使用 MySQL、Hbase、Redis 三种存储引擎,对于维表数据比较少的情况可以使用 MySQL,对于单条数据大小比较小,查询 QPS 比较高的情况,可以使用 Redis 存储,降低机器内存资源占用,对于数据量比较大,对维表数据变化不是特别敏感的场景,可以使用HBase 存储。
DM 层:
(1)轻度汇总层
- 轻度汇总层由明细层通过Streaming ETL得到,主要以宽表的形式存在,业务明细汇总是由业务事实明细表和维度表join得到,流量明细汇总是由流量日志按业务线拆分和维度表join得到;
- 轻度汇总层数据存储比较多样化,首先利用Flink实时消费DWD层Kafka中明细数据join业务过程需要的维表,实时打宽后写入该层的Kafka中,以Json或PB格式存储;
- 同时对多维业务明细汇总数据通过Flink实时写入Kudu,用于查询明细数据和更复杂的多维数据分析需求,对于流量数据通过Flink分别写入HDFS和ClickHouse用于复杂的多维数据分析, 实时特征数据则通过Flink join维表后实时写入HDFS,用于下游的离线ETL消费;
- 对于落地Kudu和HDFS的宽表数据,可用Spark SQL做分钟级的预计算,满足业务方复杂数据分析需求,提供分钟级延迟的数据,从而加速离线ETL过程的延迟, 另外随着Flink SQL与Hive生态集成的不断完善,可尝试用Flink SQL做离线ETL和OLAP计算任务(Flink流计算基于内存计算的特性,和presto非常类似,这使其也可以成为一个OLAP计算引擎),用一套计算引擎解决实时离线需求,从而实现批流统一;
- 对于Kudu中的业务明细数据、ClickHouse中的流量明细数据,也可以满足业务方的个性化数据分析需求,利用强大的OLAP计算引擎,实时查询明细数据,在10s量级的响应时间内给出结果,这类需求也即是实时OLAP需求,灵活性比较高。
(2)高度汇总层
- 高度汇总层由明细数据层或轻度汇总层通过聚合计算后写入到存储引擎中,产出一部分实时数据指标需求,灵活性比较差;
- 计算引擎使用Flink Datastream API和Flink SQL,指标存储引擎根据不同的需求,对于常见的简单指标汇总模型可直接放在MySQL里面,维度比较多的、写入更新比较大的模型会放在HBase里面, 还有一种是需要做排序、对查询QPS、响应时间要求非常高、且不需要持久化存储如大促活动期间在线TopN商品等直接存储在Redis里面;
- 在秒级指标需求中,需要混用Lambda和Kappa架构,大部分实时指标使用Kappa架构完成计算,少量关键指标(如金额相关)使用Lambda架构用批处理重新处理计算,增加一次校对过程。
七、相关问题
幂等机制
幂等是一个数学概念,特点是任意多次执行所产生的影响均与一次执行的影响相同,例如setTrue()函数就是一个幂等函数,无论多次执行,其结果都是一样的。在很多复杂情况下,例如网络波动、Storm重启等,会出现重复数据,因此并不是所有操作都是幂等的。
在幂等的概念下,我们需要了解消息传输保障的三种机制:At most once、At least once和Exactly once。
At most once:消息传输机制是每条消息传输零次或者一次,即消息可能会丢失;
At least once:意味着每条消息会进行多次传输尝试,至少一次成功,即消息传输可能重复但不会丢失;
Exactly once:的消息传输机制是每条消息有且只有一次,即消息传输既不会丢失也不会重复。
多表关联
在流式数据处理中,数据的计算是以计算增量为基础的,所以各个环节到达的时间和顺序,既是不确定的,也是无序的。在这种情况下,如果两表要关联,势必需要将数据在内存中进行存储,当一条数据到达后,需要去另一个表中查找数据,如果能够查到,则关联成功,写入下游;如果无法查到,可以被分到未分配的数据集合中进行等待。在实际处理中,考虑到数据查找的性能,会把数据按照关联主键进行分桶处理,以降低查找的数据量,提高性能。
八、相关博客
基于 Flink 的典型 ETL 场景实现方案(参考多表join)
万字干货还原美团Flink实时数仓建设
实时数仓在滴滴的实践和落地
美团外卖实时数仓建设实践
OPPO数据中台之基石:基于Flink SQL构建实时数仓
MaxCompute 交互式分析(Hologres)如何完美支撑双11智能客服实时数仓?
基于 Flink + Hive 构建流批一体准实时数仓
九、Flink部署
flink部署分为多种模式,这里采用高可用,运行在yarn上,使用Per-Job的模式。
集群规划
| 服务器 | JobManager | TaskManager |
|---|---|---|
| hadoop1 | √ | √ |
| hadoop2 | √ | |
| hadoop3 | √ |
欢迎使用面试题小程序
















 593
593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









