






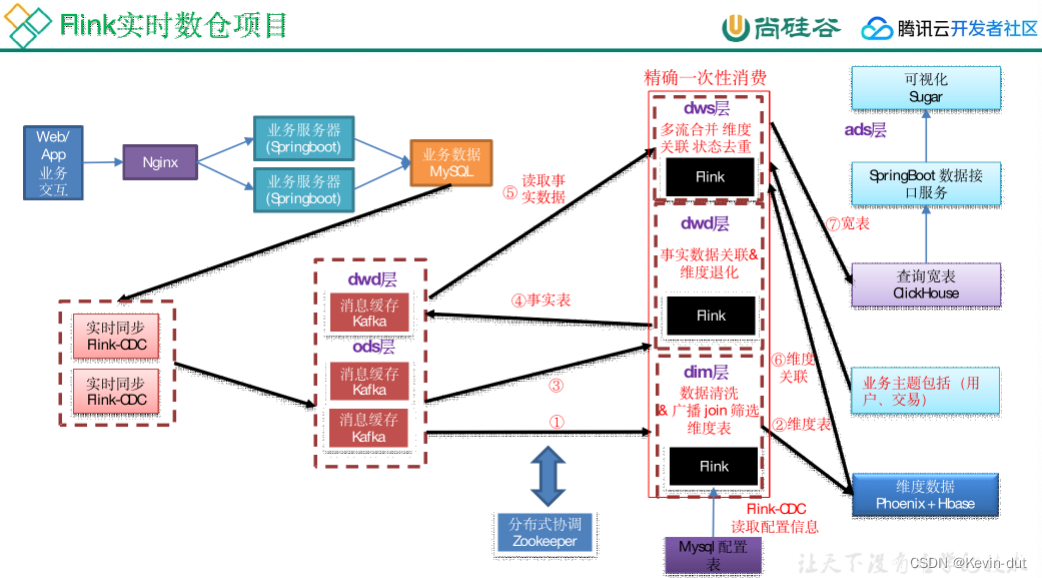
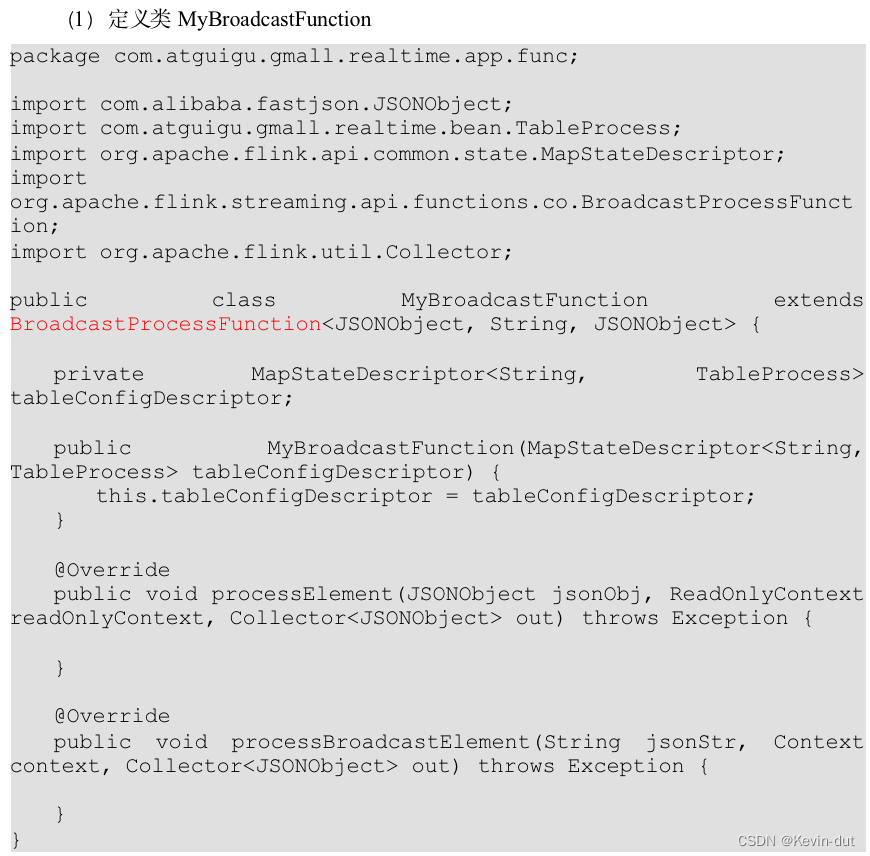
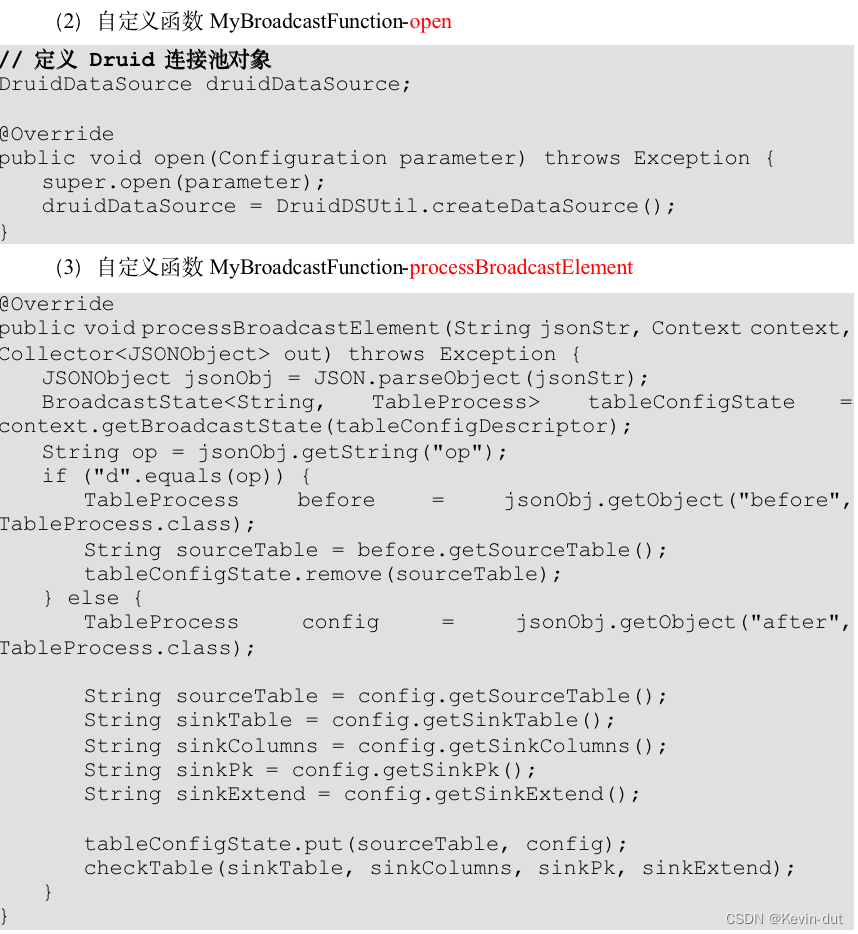
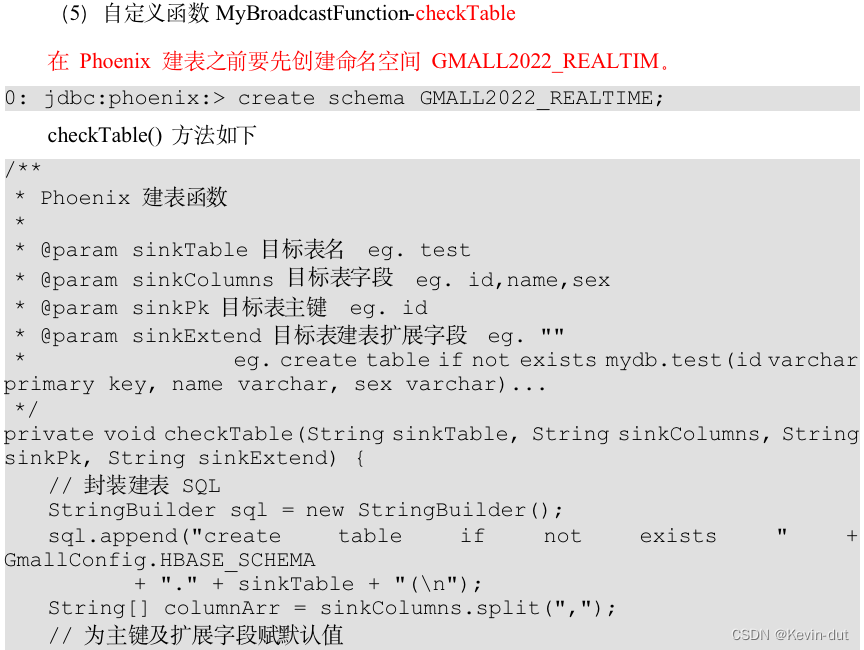
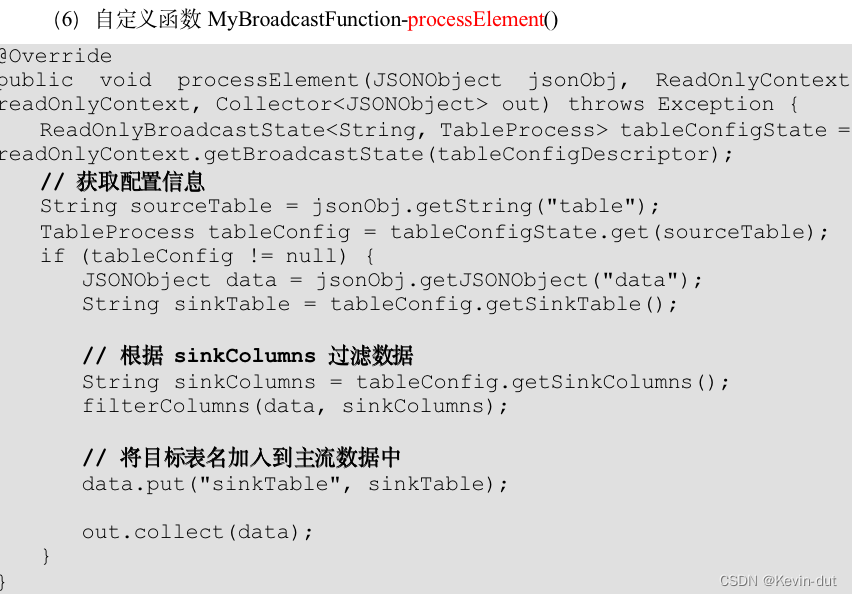
1数据仓库概述
1.2数据仓库核心架构
Flink CDC(Change Data Capture)和 Apache Flink 之间存在密切的关联,但它们并不是直接相关的概念。下面是它们之间的关系:
-
Apache Flink:
- Apache Flink 是一个流式计算框架,用于实时处理和分析大规模数据流。它提供了丰富的流处理 API 和功能,能够处理各种复杂的流式处理任务,包括实时ETL、事件驱动应用、实时分析等。
-
CDC(Change Data Capture):
- CDC 是一种数据捕获技术,用于在源数据库发生变化时捕获和传输变更数据。CDC 技术可以捕获数据库中的数据变更操作,如插入、更新、删除等,将这些变更数据以流的形式传输到目标系统,以支持实时数据同步、数据仓库加载、数据湖建设等应用场景。
-
Flink CDC:
- Flink CDC 是基于 Apache Flink 的一种应用场景,主要用于实时捕获和处理数据库变更数据。通过结合 Flink 的流处理能力和 CDC 技术,可以实现实时的数据库变更数据捕获和处理,以支持实时ETL、数据仓库实时加载、实时报表生成等应用需求。
- Flink CDC 可以与各种数据库进行集成,如 MySQL、PostgreSQL、Oracle、MongoDB 等,实时捕获数据库的变更数据,并将其转换为流式数据流,然后通过 Flink 进行实时处理和分析。
总的来说,Flink CDC 是 Flink 在数据库变更捕获和处理方面的一种应用场景,通过结合 Flink 的流处理能力和 CDC 技术,可以实现实时的数据库变更数据处理,为实时数据分析和应用提供支持。
2 数据仓库建模概述
同离线
3维度建模理论之事实表
4维度建模理论之维度表
5数据仓库设计
6数据仓库环境准备
6.1IDEA开发环境准备
1)创建模块 gmall-realtime
2)删除当前项目的src目录并创建gmall-realtime模块

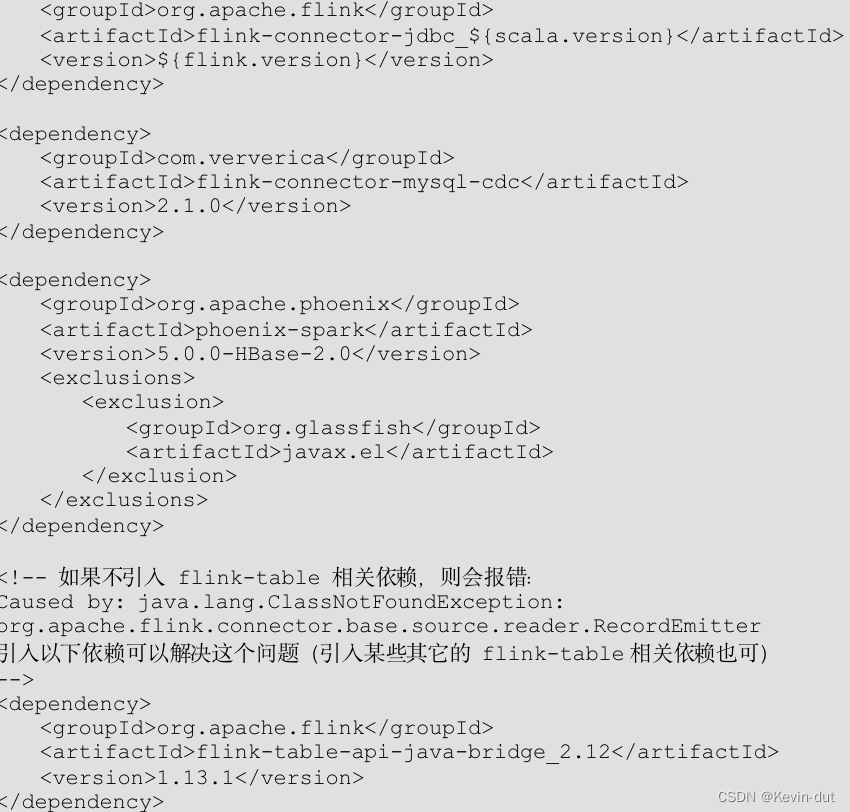
3)导入依赖
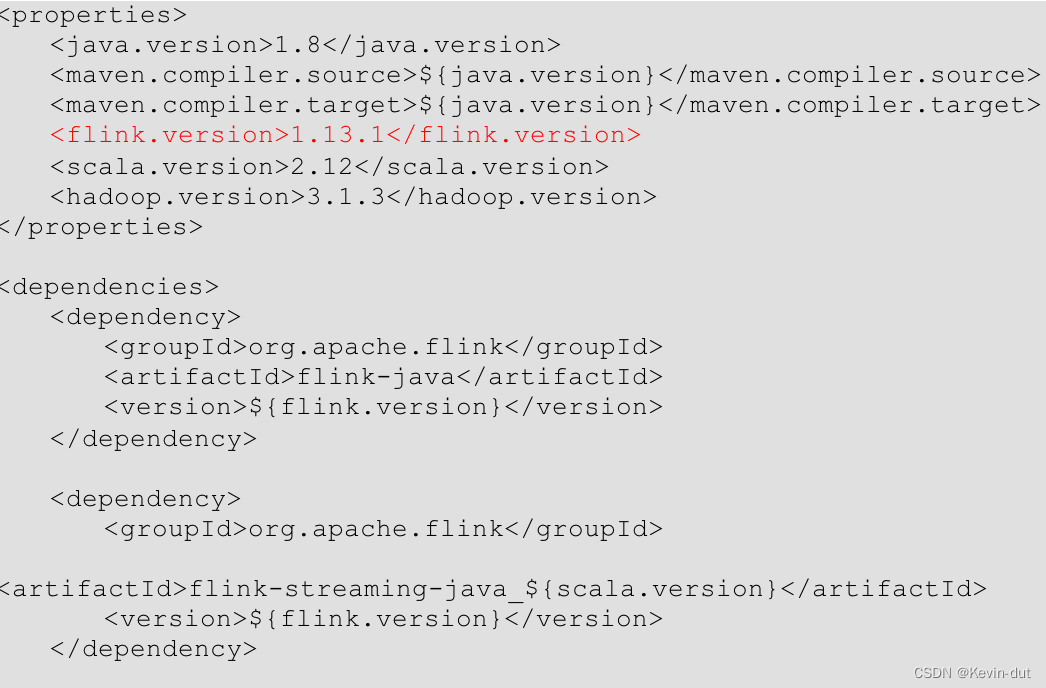


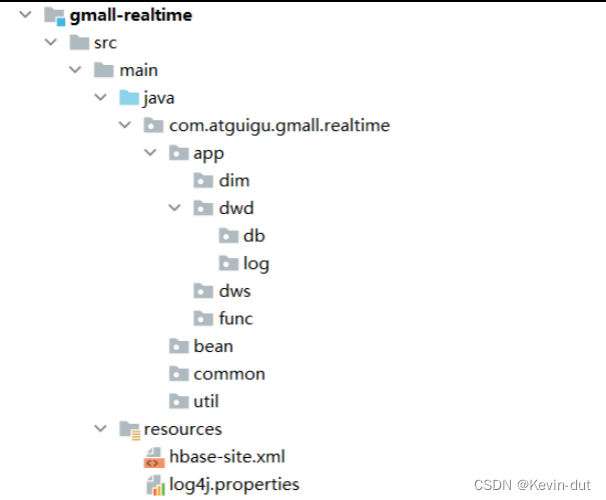
4)创建相关的包
5)在resource目录下创建log4j.properties文件,写入如下内容

6.2数据仓库运行环境
6.2.1Phoenix环境搭建
Phoenix 是一个开源的、基于 Apache Hadoop 和 Apache HBase 的 SQL 引擎,它提供了类似于关系型数据库的 SQL 查询和事务功能,同时利用 HBase 提供的分布式存储和处理能力。Phoenix 的设计目标是为 HBase 提供低延迟的、高性能的 SQL 查询能力,使得用户可以使用熟悉的 SQL 语言来查询和分析 HBase 中的数据。
以下是 Phoenix 的一些主要特点:
-
SQL 接口: Phoenix 提供了标准的 SQL 接口,支持 SQL92 标准和部分 SQL99、SQL2003 标准,用户可以使用熟悉的 SQL 语言进行数据查询、插入、更新和删除操作。
-
低延迟查询: Phoenix 的查询引擎被优化为在 HBase 上执行低延迟的 SQL 查询,使得用户可以快速地从大规模的 HBase 数据集中检索数据。
-
分布式计算: Phoenix 利用 HBase 提供的分布式存储和计算能力,能够在分布式环境中并行处理查询请求,实现水平扩展和高吞吐量。
-
事务支持: Phoenix 提供了 ACID(原子性、一致性、隔离性、持久性)事务支持,保证了数据的一致性和可靠性。
-
索引优化: Phoenix 支持多种类型的索引,包括主键索引、二级索引等,可以提高查询性能和降低查询成本。
-
与生态系统集成: Phoenix 可以与 Apache Hadoop 生态系统中的其他组件(如 Spark、Hive、MapReduce 等)无缝集成,实现数据的多种处理和分析方式。
-
易于部署和管理: Phoenix 提供了易于部署和管理的特性,用户可以通过简单的配置和命令即可搭建和管理 Phoenix 集群。
Phoenix 在很多场景下都能够提供高效的 SQL 查询能力,尤其适用于需要低延迟查询大规模结构化数据的场景,如数据仓库、实时分析、日志处理等。
Apache HBase 是一个开源的、分布式的、面向列的 NoSQL 数据库(非关系型数据库),它构建在 Apache Hadoop 上,并提供了高可靠性、高可扩展性和高性能的大规模数据存储和处理能力。HBase 最初是以 Google 的 Bigtable 论文为基础而开发的,旨在为大规模数据集提供实时读写访问。
以下是 HBase 的一些主要特点:
-
面向列存储: HBase 使用面向列存储的数据模型,将数据按照列族进行存储,每个列族可以包含任意数量的列。这种数据存储模型适合存储结构相对稀疏的数据,可以实现高效的列操作和灵活的数据模型设计。
-
分布式存储: HBase 数据被分片存储在集群中的多个节点上,以实现数据的分布式存储和处理。每个数据表可以水平扩展到数千个节点,从而实现了无限扩展的存储能力。
-
高可用性: HBase 提供了数据的自动复制和容错机制,以保证数据的高可用性和可靠性。数据副本分布在不同的节点上,当某个节点发生故障时,系统可以自动切换到其他可用节点,从而保证数据的可用性。
-
实时读写访问: HBase 支持实时的读写访问,可以实现高吞吐量的数据写入和实时的数据检索。HBase 采用 LSM 树等高效数据结构,实现了快速的数据写入和读取能力。
-
强一致性: HBase 提供了强一致性的数据访问模型,保证了数据的一致性和可靠性。它支持原子性的读写操作和分布式事务,确保了数据的一致性和可靠性。
-
与 Hadoop 生态系统集成: HBase 与 Hadoop 生态系统紧密集成,可以与 HDFS、MapReduce、Hive、Spark 等组件无缝连接,实现数据的多种处理和分析方式。
总的来说,HBase 是一个功能强大的分布式 NoSQL 数据库,适用于大规模数据存储和实时访问的场景,如日志处理、实时分析、实时推荐等。它提供了高可靠性、高可扩展性和高性能的特性,可以满足各种复杂的数据处理和分析需求。
1)Phoenix集群部署
2)IDEA Phoenix环境准备:
1 引入 Phoenix Thick Client 依赖
2 在 resources目录下创建 hbase-site.xml文件,并添加配置
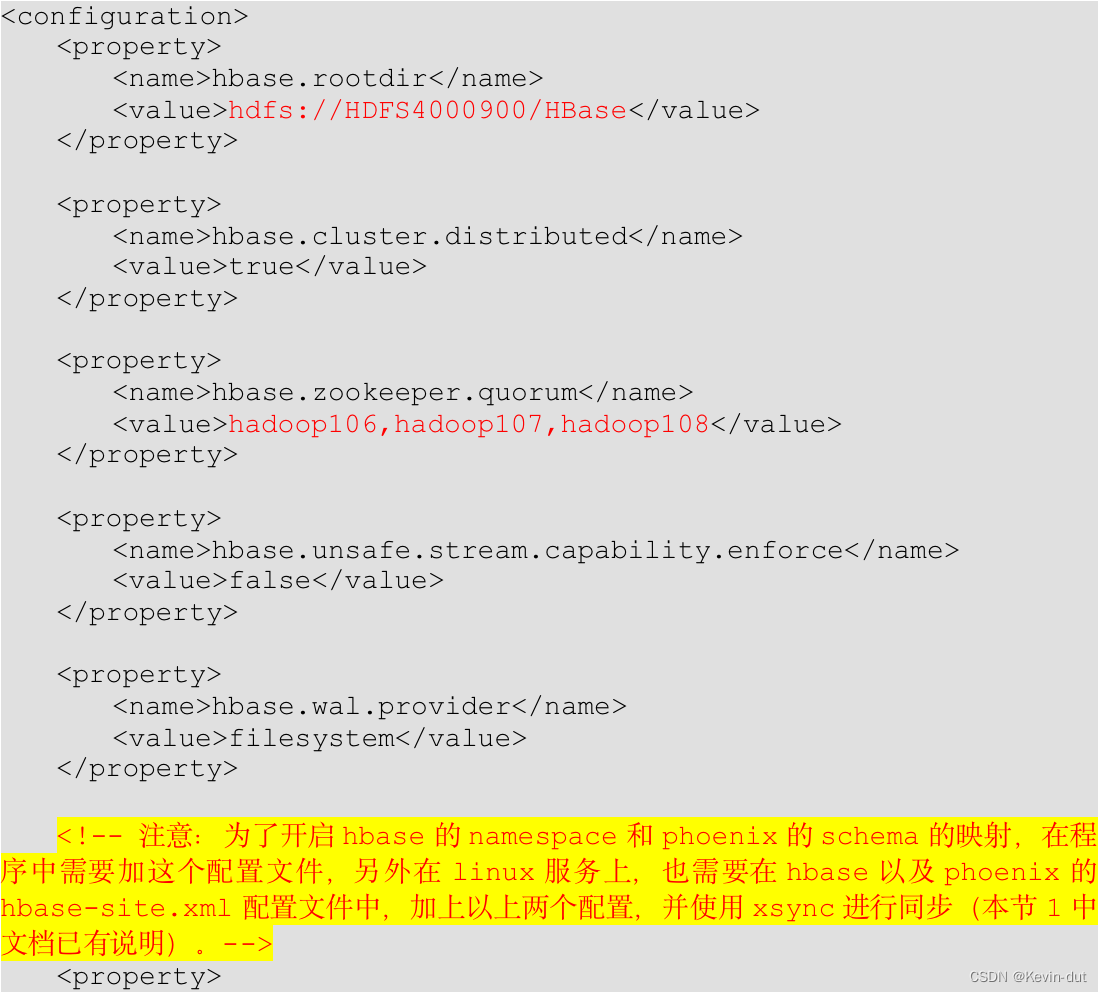
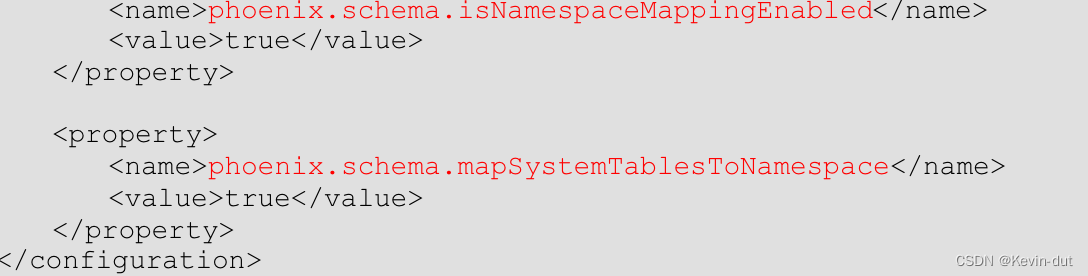 6.2.2 Redis 环境搭建
6.2.2 Redis 环境搭建
6.2.3 ClickHouse 环境搭建
7数仓开发之ODS层
采集到Kafka的topic_db主题的数据即为实时数仓的ODS层,这一层的作用是对数据做原样展示和备份
8数仓开发之DIM层
DIM层设计要点:
(1)存储维度模型的维度表
(2)DIM层数据存储在HBase表中
DIM层表是用于维度关联的,要通过主键去获取维度信息,这种场景下KV类型数据库的效率较高,常见的KV类型数据库有Redis、HBase,而Redis的数据常驻内存,会给内存造成较大压力,因而选用HBase存储维度数据。
(3)DIM层表名的命名规范为dim_表名
8.1配置表
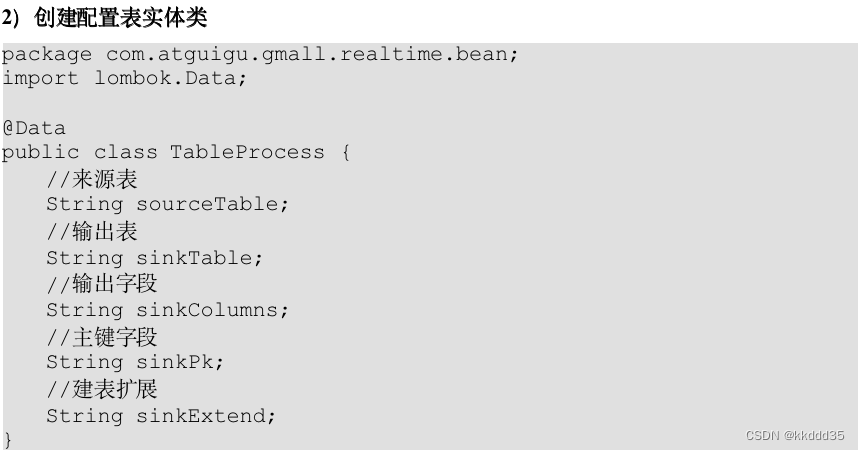
本层任务是将业务数据直接写入不同的HBase表中,那么如何让程序知道流中哪些数据是维度数据?维度数据又应该写到HBase的哪些表中?为了解决这个问题,选择在MySQL中构建一张配置表,通过FlinkCDC将配置表信息读取到程序中
8.1.1配置表设计


8.2主要任务
8.2.1 接收Kafka数据,过滤空值数据
对FlinkCDC抓取的数据进行ETL,有用的部分保留,没用的过滤掉
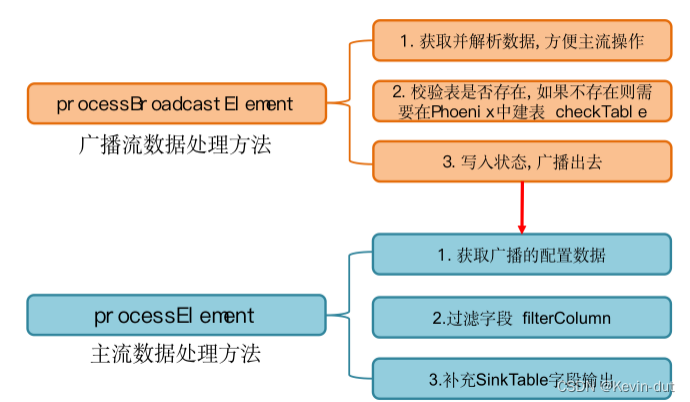
8.2.2 动态拆分维度表功能


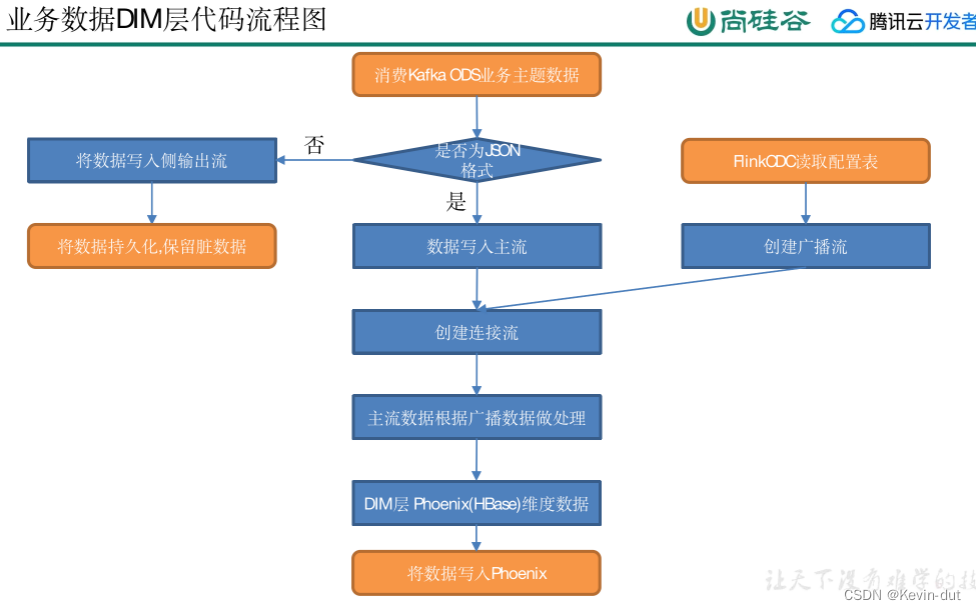
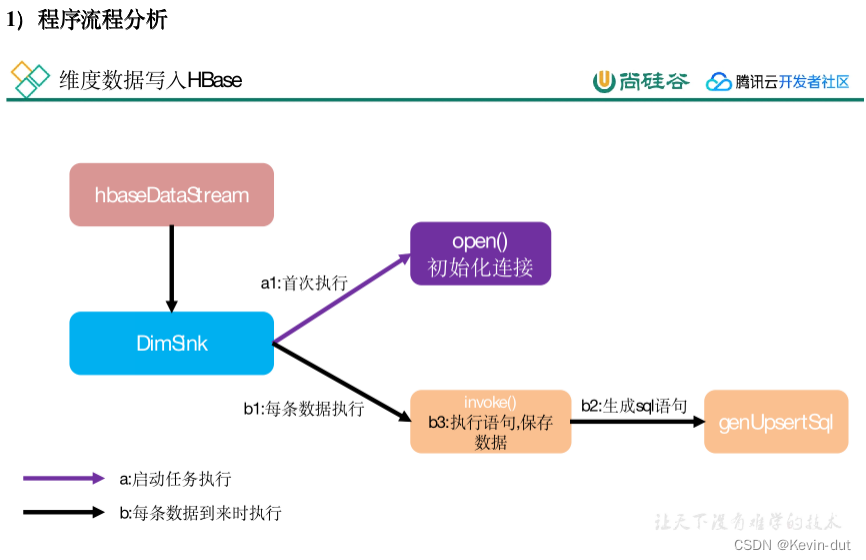
8.2.3把流中的数据保存到对应的维度表
维度数据保存到HBase的表中
8.3代码实现
8.3.1 接收Kafka数据,过滤空值数据(FlinkKafkaConsumer、FlinkKafkaProducer,一起封装提高复用性)



8.3.2根据MySQL的配置表,动态进行分流




![]()




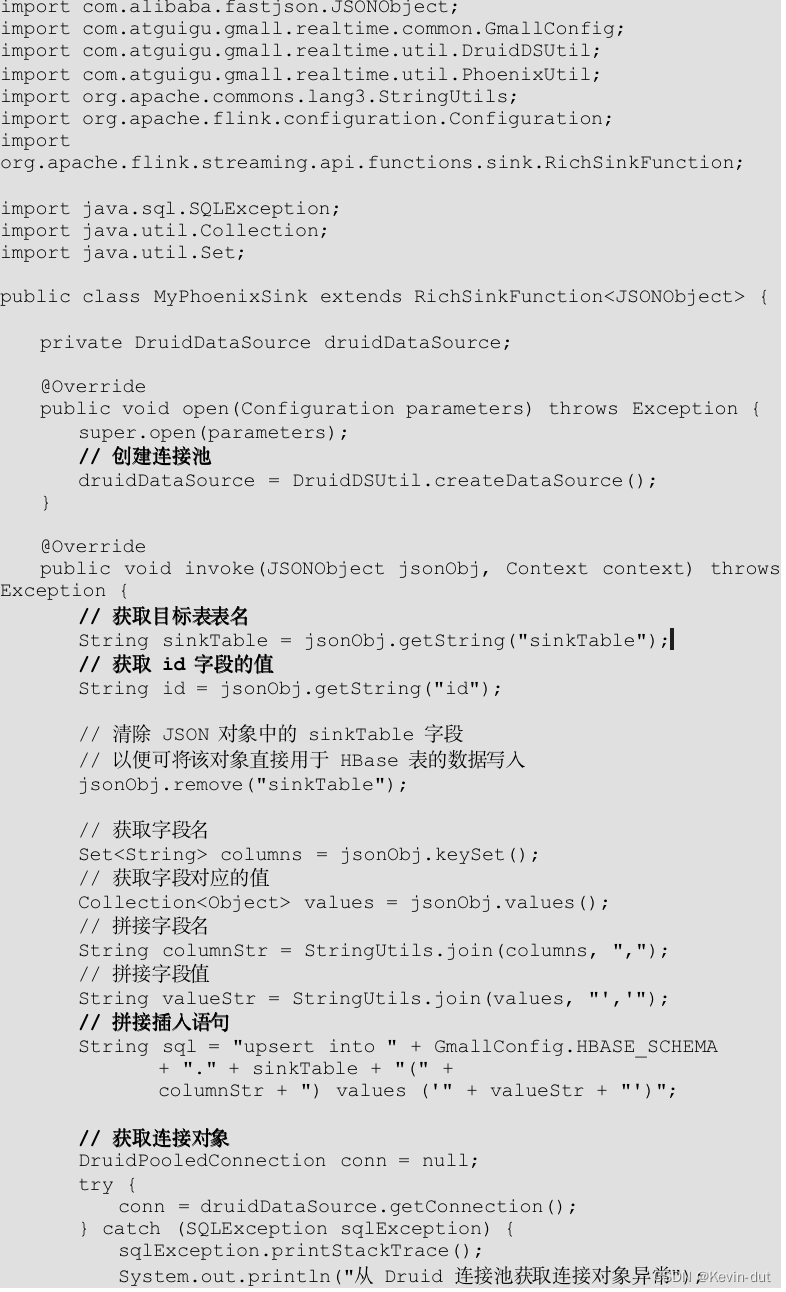
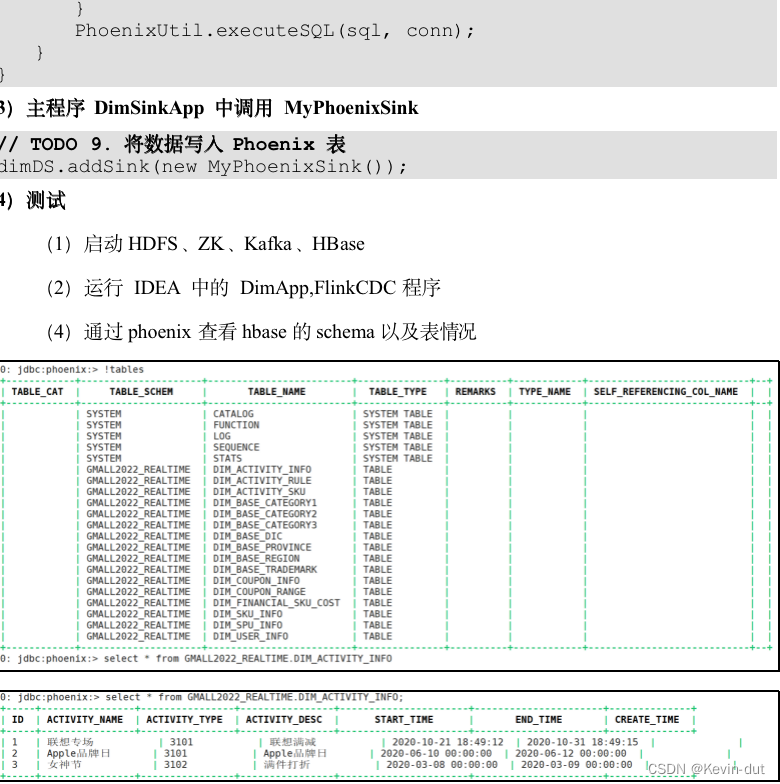
8.3.3保存维度到HBase(Phoenix)


9 数仓开发之DWD层
DWD层设计要点:
1)存储维度模型的事实表
2)命名规范为dwd_数据域_表名
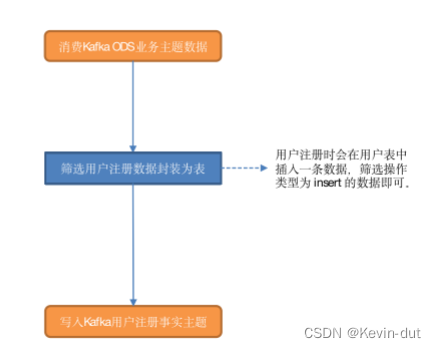
9.1用户域用户注册事务事实表
9.1.1主要任务
读取用户表数据,获取注册时间,将用户注册信息写入Kafka用户注册主题。
9.1.2思路分析
用户注册会在用户表中插入一条数据,筛选操作类型为insert的数据即可
9.1.3图解
9.1.4 代码


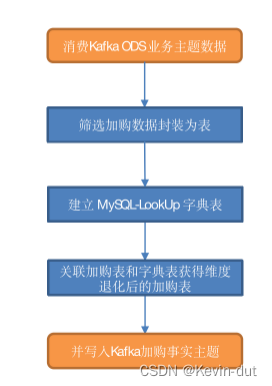
9.2交易域加购事务事实表
9.2.1 主要任务
提取加购操作生成加购表,并将字典中的相关维度退化到加购表中,写出到Kafka对应主题
9.2.2思路分析(Flink的JDBC SQL Connector 、Kafka Connector)





9.2.3图解
9.2.4 代码





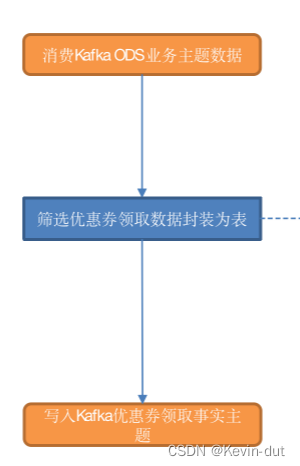
9.3 工具域优惠券领取事务事实表
9.3.1 主要任务
读取优惠券领用数据,写入Kafka优惠券领用主题
9.3.2 思路分析
用户领取优惠券后,业务数据库的优惠券领用表会新增一条数据,因此操作类型为 insert 的数据即为优惠券领取数据。
9.3.3 图解
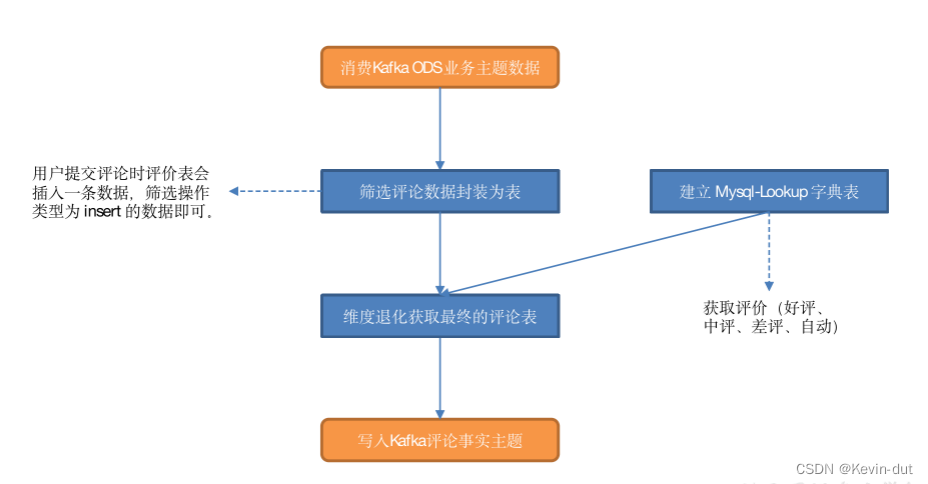
9.4 互动域评价事务事实表
9.4.1 主要任务
建立 MySQL-Lookup 字典表,读取评论表数据,关联字典表以获取评价(好评、中评、差评、自动),将结果写入 Kafka 评价主题。
9.4.2 思路分析
1)设置 ttl
前文提到,与字典表关联时 ttl 的设置主要是考虑到从外部介质查询维度数据的时间,此处设置为 5s。
2)筛选评论数据
用户提交评论时评价表会插入一条数据,筛选操作类型为 insert 的数据即可。
3)建立 Mysql-Lookup 字典表
4)关联两张表
5)写入 Kafka 互动域评论事实主题
9.4.3 图解
9.4.4 代码
大步骤类似
9.5 交易域下单事务事实表
9.5.1 主要任务
关联订单明细表、订单表、订单明细活动关联表、订单明细优惠券关联表四张事实业务表的insert操作和字典表(维度业务表)形成订单明细表,写入 Kafka 对应主题。
9.5.2 思路分析(Upsert Kafka Connector)
1)知识储备
(1)left join 实现过程
假设 A 表作为主表与 B 表做等值左外联。当 A 表数据进入算子,而 B 表数据未至时会先生成一条 B 表字段均为 null 的关联数据ab1,其标记为 +I。其后,B 表数据到来,会先将之前的数据撤回,即生成一条与 ab1 内容相同,但标记为 -D 的数据,再生成一条关联后的数据,标记为 +I。这样生成的动态表对应的流称之为回撤流。
(2)Kafka SQL Connector
Kafka SQL Connector 分为 Kafka SQL Connector 和 Upsert Kafka SQL Connector
① 功能
Upsert Kafka Connector支持以 upsert 方式从 Kafka topic 中读写数据
Kafka Connector支持从 Kafka topic 中读写数据
② 区别
a)建表语句的主键
i)Kafka Connector 要求表不能有主键,如果设置了主键,报错信息如下
Caused by: org.apache.flink.table.api.ValidationException: The Kafka table 'default_catalog.default_database.normal_sink_topic' with 'json' format doesn't support defining PRIMARY KEY constraint on the table, because it can't guarantee the semantic of primary key.
ii)而 Upsert Kafka Connector 要求表必须有主键,如果没有设置主键,报错信息如下
Caused by: org.apache.flink.table.api.ValidationException: 'upsert-kafka' tables require to define a PRIMARY KEY constraint. The PRIMARY KEY specifies which columns should be read from or write to the Kafka message key. The PRIMARY KEY also defines records in the 'upsert-kafka' table should update or delete on which keys.
iii)语法: primary key(id) not enforced
注意:not enforced 表示不对来往数据做约束校验,Flink 并不是数据的主人,因此只支持 not enforced 模式
如果没有 not enforced,报错信息如下
Exception in thread "main" org.apache.flink.table.api.ValidationException: Flink doesn't support ENFORCED mode for PRIMARY KEY constaint. ENFORCED/NOT ENFORCED controls if the constraint checks are performed on the incoming/outgoing data. Flink does not own the data therefore the only supported mode is the NOT ENFORCED mode
b)对表中数据操作类型的要求
i)Kafka Connector 不能消费带有 Upsert/Delete 操作类型数据的表,如 left join 生成的动态表。如果对这类表进行消费,报错信息如下
Exception in thread "main" org.apache.flink.table.api.TableException: Table sink 'default_catalog.default_database.normal_sink_topic' doesn't support consuming update and delete changes which is produced by node TableSourceScan(table=[[default_catalog, default_database, Unregistered_DataStream_Source_9]], fields=[l_id, tag_left, tag_right])
ii)Upsert Kafka Connector 将 INSERT/UPDATE_AFTER 数据作为正常的 Kafka 消息写入,并将 DELETE 数据以 value 为空的 Kafka 消息写入(表示对应 key 的消息被删除)。Flink 将根据主键列的值对数据进行分区,因此同一主键的更新/删除消息将落在同一分区,从而保证同一主键的消息有序。
③ left join 结合 Upsert Kafka Connector 使用范例
说明:Kafka 并行度为 4
a)表结构
left表
id tag
A left
B left
C left
right 表
id tag
A right
B right
C right
b)查询语句
select
l.id l_id,
l.tag l_tag,
r.tag r_tag
from left l
left join right r
on l.id = r.id
c)关联结果写入到 Upsert Kafka 表,消费 Kafka 对应主题数据结果展示
{"l_id":"A","tag_left":"left","tag_right":null}
null
{"l_id":"A","tag_left":"left","tag_right":"right"}
{"l_id":"C","tag_left":"left","tag_right":null}
null
{"l_id":"C","tag_left":"left","tag_right":"right"}
{"l_id":"B","tag_left":"left","tag_right":null}
null
{"l_id":"B","tag_left":"left","tag_right":"right"}
④ 参数解读
本节需要用到 Kafka 连接器的明细表数据来源于 topic_db 主题,于 Kafka 而言,该主题的数据的操作类型均为 INSERT,所以读取数据使用 Kafka Connector 即可。而由于 left join 的存在,流中存在修改数据,所以写出数据使用 Upsert Kafka Connector。
Upsert Kafka Connector 参数
- connector:指定使用的连接器,对于 Upsert Kafka,使用 'upsert-kafka'
- topic:主题
- properties.bootstrap.servers:以逗号分隔的 Kafka broker 列表
- key.format:key 的序列化和反序列化格式
- value.format:value 的序列化和反序列化格式
(3)Flink中的处理时间函数
FlinkSQL 提供了几个可以获取当前时间戳的函数
- localtimestamp:返回本地时区的当前时间戳,返回类型为 TIMESTAMP(3)。在流处理模式下会对每条记录计算一次时间。而在批处理模式下,仅在查询开始时计算一次时间,所有数据使用相同的时间。
- current_timestamp:返回本地时区的当前时间戳,返回类型为 TIMESTAMP_LTZ(3)。在流处理模式下会对每条记录计算一次时间。而在批处理模式下,仅在查询开始时计算一次时间,所有数据使用相同的时间。
- now():与 current_timestamp 相同。
- current_row_timestamp():返回本地时区的当前时间戳,返回类型为 TIMESTAMP_LTZ(3)。无论在流处理模式还是批处理模式下,都会对每行数据计算一次时间。
函数测试。查询语句如下。
tableEnv.sqlQuery("select localtimestamp," +
"current_timestamp," +
"now()," +
"current_row_timestamp()")
.execute()
.print();
查询结果如下。
+----+-------------------------+-------------------------+-------------------------+-------------------------+
| op | localtimestamp | current_timestamp | EXPR$2 | EXPR$3 |
+----+-------------------------+-------------------------+-------------------------+-------------------------+
| +I | 2022-04-13 20:42:28.529 | 2022-04-13 20:42:28.529 | 2022-04-13 20:42:28.529 | 2022-04-13 20:42:28.529 |
+----+-------------------------+-------------------------+-------------------------+-------------------------+
1 row in set
动态表属于流处理模式,所以四种函数任选其一即可。此处选择 current_row_timestamp()。
2)执行步骤
(1)设置 ttl;
ttl(time-to-live)即存活时间。表之间做普通关联时,底层会将两张表的数据维护到状态中,默认情况下状态永远不会清空,这样会对内存造成极大的压力。表状态的 ttl 是 Idle(空闲,即状态未被更新)状态被保留的最短时间,假设 ttl 为 10s,若状态中的数据在 10s 内未被更新,则未来的某个时间会被清除(故而 ttl 是最短存活时间)。ttl 默认值为 0,表示永远不会清空状态。
下单操作发生时,订单明细表、订单表、订单明细优惠券关联表和订单明细活动关联表的数据操作类型均为insert,不存在业务上的滞后问题,只考虑可能的数据乱序即可,因此将 ttl 设置为5s。
要注意:前文提到,本项目保证了同一分区、同一并行度的数据有序。此处的乱序与之并不冲突,以下单业务过程为例,用户完成下单操作时,订单表中会插入一条数据,订单明细表中会插入与之对应的多条数据,本项目业务数据是按照主键分区进入 Kafka 的,虽然同分区数据有序,但是同一张业务表的数据可能进入多个分区,会乱序。这样一来,订单表数据与对应的订单明细数据可能被属于其它订单的数据“插队”,因而导致主表或从表数据迟到,可能 join 不上,为了应对这种情况,设置了乱序程度,让状态中的数据等待一段时间。
(2)从 Kafka topic_db 主题读取业务数据;
这一步要调用 PROCTIME() 函数获取系统时间作为与字典表做 Lookup Join 的处理时间字段。
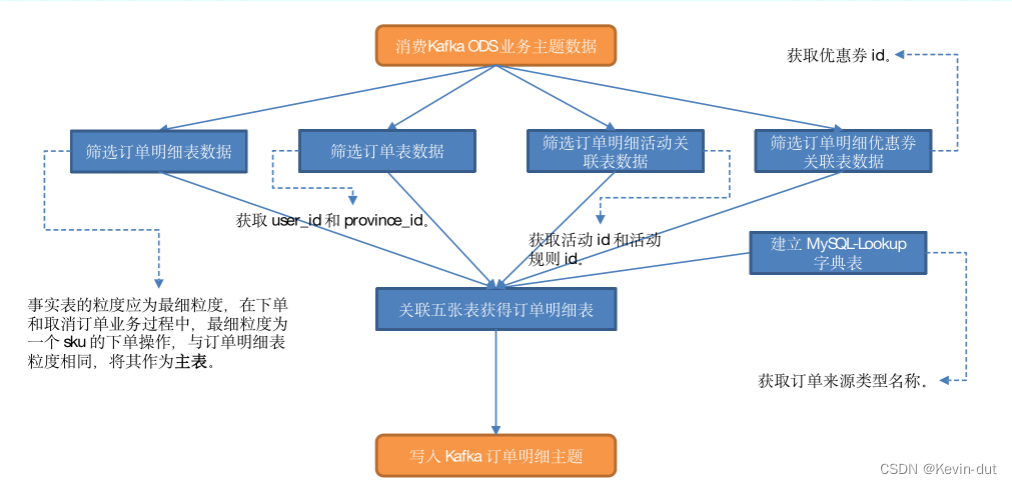
(3)筛选订单明细表数据;
应尽可能保证事实表的粒度为最细粒度,在下单业务过程中,最细粒度的事件为一个订单的一个 SKU 的下单操作,订单明细表的粒度与最细粒度相同,将其作为主表。筛选insert操作类型的数据即可。
(4)筛选订单表数据;
通过该表获取 user_id 和 province_id。筛选insert操作类型的数据。
(5)筛选订单明细活动关联表数据;
通过该表获取活动 id 和活动规则 id。筛选insert操作类型的数据。
(6)筛选订单明细优惠券关联表数据;
通过该表获取优惠券 id。筛选insert操作类型的数据。
(7)建立 MySQL-Lookup 字典表;
通过字典表获取订单来源类型名称。
(8)关联上述五张表获得订单宽表,写入 Kafka 主题
事实表的粒度应为最细粒度,在下单业务过程中,最细粒度为一个 sku 的下单操作,与订单明细表粒度相同,将其作为主表。
① 订单明细表和订单表的所有记录在另一张表中都有对应数据,内连接即可。
② 订单明细数据未必参加了活动也未必使用了优惠券,因此要保留订单明细独有数据,所以与订单明细活动关联表和订单明细优惠券关联表的关联使用 left join。
③ 与字典表的关联是为了获取 source_type 对应的 source_type_name,订单明细数据在字典表中一定有对应,内连接即可。
9.5.3 图解
9.5.4 代码
1)在 MyKafkaUtil 中补充 getUpsertKafkaDDL 方法
/**
* UpsertKafka-Sink DDL 语句
*
* @param topic 输出到 Kafka 的目标主题
* @return 拼接好的 UpsertKafka-Sink DDL 语句
*/
public static String getUpsertKafkaDDL(String topic) {
return "WITH ( " +
" 'connector' = 'upsert-kafka', " +
" 'topic' = '" + topic + "', " +
" 'properties.bootstrap.servers' = '" + BOOTSTRAP_SERVERS + "', " +
" 'key.format' = 'json', " +
" 'value.format' = 'json' " +
")";
}
10 数仓开发之DWS层(ClickHouse,基于OLAP数据库)
设计要点:
(1)DWS层的设计参考指标体系;
(2) DWS层表名的命名规范为dws_数据域_统计粒度_业务过程_统计周期(window)。
注:window 表示窗口对应的时间范围
10.1 用户域用户注册各窗口汇总表
10.1.1 主要任务
从 DWD 层用户注册表中读取数据,统计各窗口注册用户数,写入 ClickHouse。
10.1.2 思路分析
1)读取 Kafka 用户注册主题数据
2)转换数据结构
String 转换为 JSONObject。
3)设置水位线
水位线(Watermark)是 Apache Flink 中用于处理事件时间的概念。在流式处理中,事件时间是事件发生的实际时间,与处理事件的系统时间和顺序无关。水位线用于表示事件时间的进度,通常用于处理延迟数据和乱序数据。
水位线的主要作用包括:
-
处理乱序数据:在流式处理中,事件可能以不确定的顺序到达处理节点,造成数据的乱序。水位线可以用于确定事件时间的进度,帮助系统正确地处理乱序数据,保证结果的正确性。
-
处理延迟数据:在流式处理中,有些事件可能由于网络延迟、系统故障等原因而延迟到达处理节点。水位线可以用于检测延迟数据,确保及时地处理和更新结果。
-
触发窗口计算:水位线通常与窗口计算结合使用,用于触发窗口的计算和关闭。当水位线达到窗口的结束时间时,表示窗口内的所有事件都已到达,可以触发窗口的计算和输出。
水位线通常由源算子(Source Function)生成,并随着数据流一起传播到整个流式处理任务中。Flink 提供了各种水位线生成器和处理函数,如周期性水位线生成器、自定义水位线生成器等,可以根据应用场景和需求来选择合适的水位线策略。
总的来说,水位线是流式处理中用于处理事件时间的重要概念,可以帮助系统正确地处理乱序数据和延迟数据,保证结果的正确性和时效性。
4)开窗、聚合
5)写入 ClickHouse
在 Apache Flink 中,将从 Kafka 消费的数据封装为 FlinkSQL 或封装为流的区别在于数据的处理方式和使用场景:
-
FlinkSQL:
- 使用 FlinkSQL 将从 Kafka 消费的数据进行封装,意味着您将数据处理逻辑定义为 SQL 查询。Flink 提供了对 SQL 查询的支持,可以直接在 Flink 程序中使用 SQL 语句来定义数据流的处理逻辑。
- FlinkSQL 使得数据处理逻辑更加简单和直观,尤其是对于熟悉 SQL 的用户来说,可以更快速地编写和理解数据处理逻辑。
- FlinkSQL 还提供了查询优化、执行计划优化等功能,可以帮助优化 SQL 查询的性能和效率。
-
封装为流:
- 将从 Kafka 消费的数据封装为流,意味着您需要使用 Flink 的 DataStream API 来定义数据处理逻辑。DataStream API 提供了一组丰富的操作符和函数,可以实现各种复杂的数据处理任务。
- 封装为流使得您可以更灵活地定义数据处理逻辑,可以使用丰富的操作符和函数来实现复杂的数据处理需求,如窗口操作、状态管理、自定义函数等。
- 封装为流适用于需要更复杂数据处理逻辑的场景,或者对 FlinkSQL 不够灵活的情况下使用。
10.1.3 图解
10.1.4 ClickHouse 建表语句
drop table if exists dws_user_user_register_window;
create table if not exists dws_user_user_register_window
(
stt DateTime,
edt DateTime,
register_ct UInt64,
ts UInt64
) engine = ReplacingMergeTree(ts)
partition by toYYYYMMDD(stt)
order by (stt, edt);10.1.5 代码




10.2 交易域加购各窗口汇总表
10.2.1 主要任务
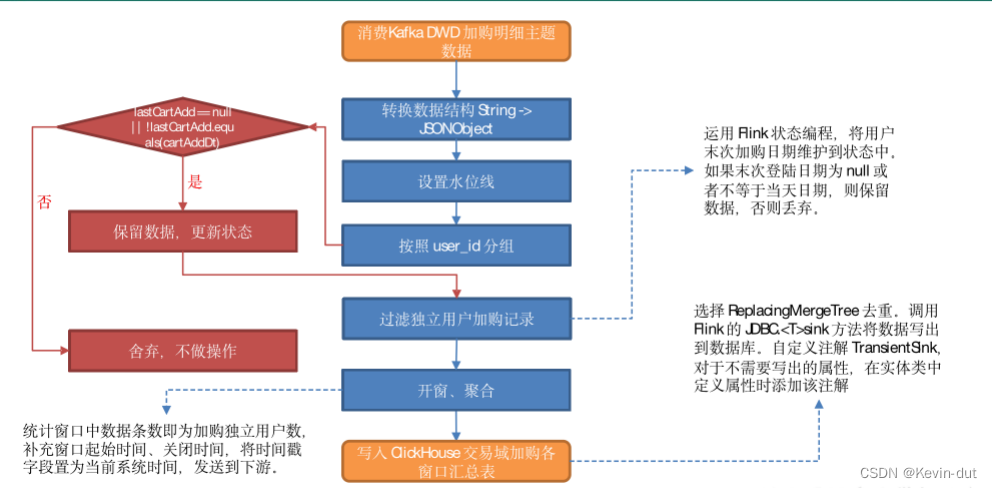
从 Kafka 读取用户加购明细数据,统计各窗口加购独立用户数,写入 ClickHouse。
10.2.2 思路分析
1)从 Kafka 加购明细主题读取数据
2)转换数据结构
将流中数据由 String 转换为 JSONObject。
3)设置水位线
4)按照用户 id 分组
5)过滤独立用户加购记录
运用 Flink 状态编程,将用户末次加购日期维护到状态中。
如果末次登陆日期为 null 或者不等于当天日期,则保留数据并更新状态,否则丢弃,不做操作。
Flink 状态编程是指在 Apache Flink 中使用状态(State)来管理和维护应用程序的状态信息,以支持复杂的流处理任务。状态是指在流式处理任务中需要跟踪和维护的数据信息,可以是计数器、累加器、聚合结果、窗口状态等。状态编程是 Flink 中非常重要的一部分,它提供了丰富的状态管理功能,支持各种复杂的流处理场景。
Flink 状态编程的主要特点和功能包括:
-
状态管理:Flink 提供了灵活的状态管理功能,可以在流处理任务中方便地创建、更新和访问状态。状态可以是键控状态(Keyed State)或操作符状态(Operator State),并且可以根据需要选择不同的状态后端(如内存、RocksDB)进行持久化存储。
-
状态访问:在流处理任务中,可以使用 Flink 提供的状态访问接口来读取和更新状态。状态可以在处理函数中直接访问,也可以在窗口函数、ProcessFunction 等特定的处理函数中使用。
-
状态恢复:Flink 支持容错机制,可以在任务失败或重启时自动恢复状态。Flink 使用检查点(Checkpoint)和保存点(Savepoint)来实现状态的持久化和恢复,保证任务的数据一致性和可靠性。
-
有限状态机:Flink 提供了有限状态机(Finite State Machine)API,用于定义和管理有限状态机。有限状态机是一种模型,用于描述对象在不同状态之间的转换和行为。
-
状态后端:Flink 支持多种状态后端,如内存状态后端、RocksDB 状态后端等。不同的状态后端具有不同的性能和特性,可以根据应用场景和需求选择合适的状态后端。
通过状态编程,用户可以方便地实现各种复杂的流处理任务,如状态管理、窗口操作、事件处理等。状态编程是 Flink 中实现高性能、可靠和可伸缩的流处理应用的关键技术之一。
6)开窗、聚合
统计窗口中数据条数即为加购独立用户数,补充窗口起始时间、关闭时间,将时间戳字段置为当前系统时间,发送到下游。
7)将数据写入 ClickHouse。
10.2.3 图解
10.3 交易域SKU粒度下单各窗口汇总表
10.3.1 主要任务
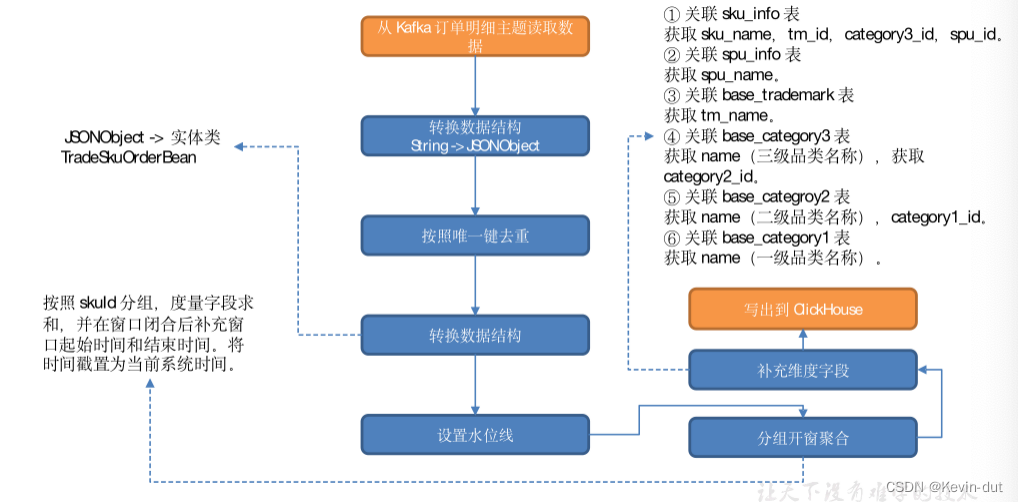
从 Kafka 订单明细主题读取数据,按照唯一键对数据去重,分组开窗聚合,统计各维度各窗口的订单数、原始金额、活动减免金额、优惠券减免金额和订单金额,补全维度信息,将数据写入 ClickHouse 交易域SKU粒度下单各窗口汇总表。
10.3.2 思路分析
与上文提到的 DWS 层宽表相比,本程序新增了维度关联操作。
维度表保存在 HBase,首先要在 PhoenixUtil 工具类中补充查询方法。
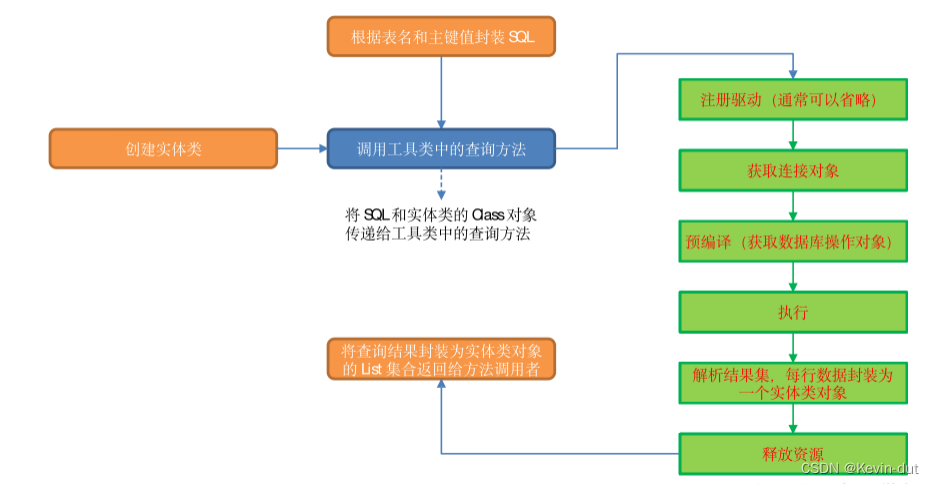
1)PhoenixUtil 查询方法思路
本程序要通过已知的主键、表名从 HBase 中获取相关维度字段的值。根据已知信息,我们可以拼接查询语句,通过参数传递给查询方法,在方法内部执行注册驱动、获取连接对象、预编译(获取数据库操作对象)、执行、解析结果集、关闭资源六个步骤即可取出数据。
查询结果必然要通过返回值的方式将数据传递给调用者。那么,返回值应该是什么类型?查询结果可能有多条,所以返回值应该是一个集合。确定了这一点,接下来要考虑集合元素用什么类型?查询结果可能有多个字段,此处提出两种方案:元组或实体类。下文将对两种方案的实现方式进行分析。
(1)元组
如果用元组封装每一行的查询结果,可以有两种策略。a)把元组的元素个数传递给方法,然后通过 switch … case … 针对不同的元素个数调用对应的元组 API 对查询结果进行封装;b)把元组的 Class 对象传给方法,通过反射的方式将查询结果赋值给元组对象。a 的问题是需要编写大量的重复代码,对于每一个分支都要写一遍相同的处理逻辑;b 的问题是丢失了元组元素的类型信息。
由于没有元组元素的类型信息,所以只能调用 Field 对象的 set 方法赋值,导致元组元素类型均为 Object,如此一来可能会为下游数据处理带来不便。
此外,Flink 提供的元组最大元素个数为 25,当查询结果字段过多时会出问题。
(2)实体类
将实体类的 Class 对象通过参数传递到方法内,通过反射将查询结果赋值给实体类对象。
基于以上分析,此处选择自定义实体类作为集合元素,查询结果的每一行对应一个实体类对象,将所有对象封装到 List 集合中,返回给方法调用者。
2)Phoenix 维度查询图解
3)旁路缓存优化
外部数据源的查询常常是流式计算的性能瓶颈。以本程序为例,每次查询都要连接 Hbase,数据传输需要做序列化、反序列化,还有网络传输,严重影响时效性。可以通过旁路缓存对查询进行优化。
旁路缓存模式是一种非常常见的按需分配缓存模式。所有请求优先访问缓存,若缓存命中,直接获得数据返回给请求者。如果未命中则查询数据库,获取结果后,将其返回并写入缓存以备后续请求使用。
(1)旁路缓存策略应注意两点
a)缓存要设过期时间,不然冷数据会常驻缓存,浪费资源。
b)要考虑维度数据是否会发生变化,如果发生变化要主动清除缓存。
(2)缓存的选型
一般两种:堆缓存或者独立缓存服务(memcache,redis)
堆缓存,性能更好,效率更高,因为数据访问路径更短。但是难于管理,其它进程无法维护缓存中的数据。
独立缓存服务(redis,memcache),会有创建连接、网络IO等消耗,较堆缓存略差,但性能尚可。独立缓存服务便于维护和扩展,对于数据会发生变化且数据量很大的场景更加适用,此处选择独立缓存服务,将 redis 作为缓存介质。
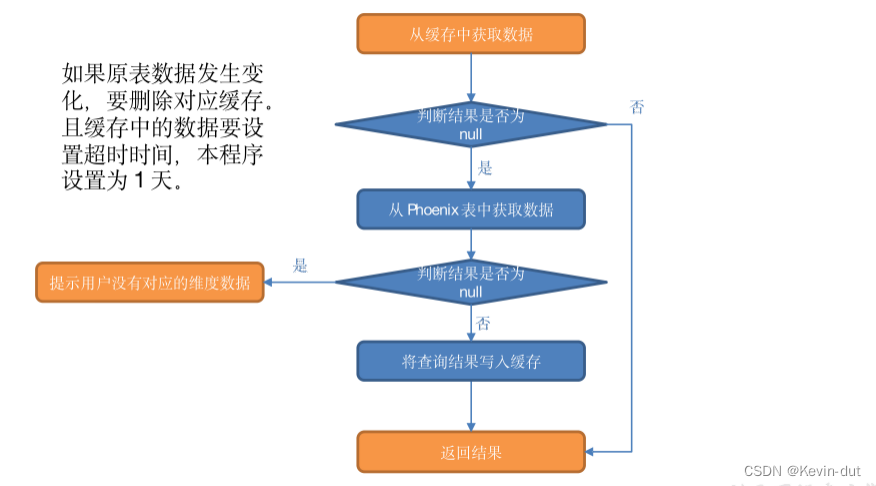
(3)实现步骤
从缓存中获取数据。
① 如果查询结果不为 null,则返回结果。
② 如果缓存中获取的结果为 null,则从 Phoenix 表中查询数据。
a)如果结果非空则将数据写入缓存后返回结果。
b)否则提示用户:没有对应的维度数据
注意:缓存中的数据要设置超时时间,本程序设置为 1 天。此外,如果原表数据发生变化,要删除对应缓存。为了实现此功能,需要对维度分流程序做如下修改:
i)在 MyBroadcastFunction的 processElement 方法内将操作类型字段添加到 JSON 对象中。
ii)在 DimUtil 工具类中添加 deleteCached 方法,用于删除变更数据的缓存信息。
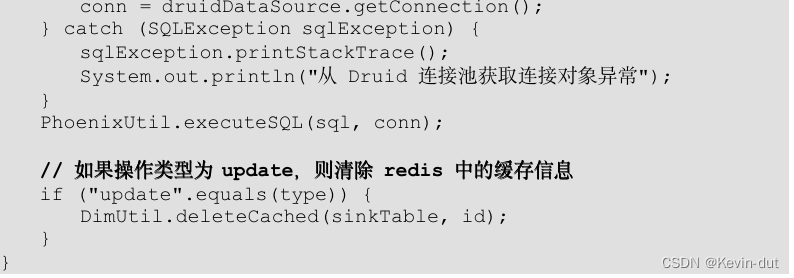
iii)在 MyPhoenixSink 的 invoke 方法中补充对于操作类型的判断,如果操作类型为 update 则清除缓存。
4)旁路缓存图解
5)异步 IO
在Flink 流处理过程中,经常需要和外部系统进行交互,如通过维度表补全事实表中的维度字段。
默认情况下,在Flink 算子中,单个并行子任务只能以同步方式与外部系统交互:将请求发送到外部存储,IO阻塞,等待请求返回,然后继续发送下一个请求。这种方式将大量时间耗费在了等待结果上。
为了提高处理效率,可以有两种思路。
(1)增加算子的并行度,但需要耗费更多的资源。
(2)异步 IO。
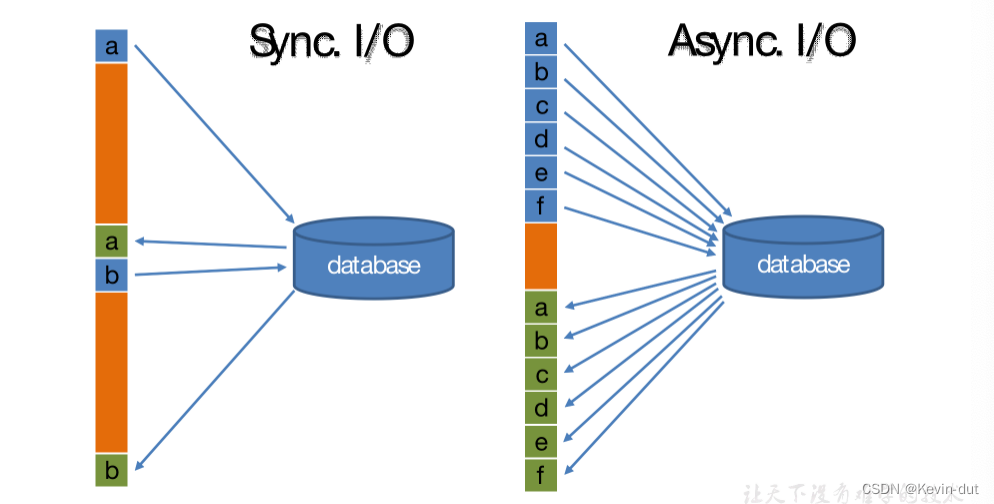
Flink 在1.2中引入了Async I/O,将IO操作异步化。在异步模式下,单个并行子任务可以连续发送多个请求,按照返回的先后顺序对请求进行处理,发送请求后不需要阻塞式等待,省去了大量的等待时间,大幅提高了流处理效率。
Async I/O 是阿里巴巴贡献给社区的特性,呼声很高,可用于解决与外部系统交互时网络延迟成为系统瓶颈的问题。
异步查询实际上是把维表的查询操作托管给单独的线程池完成,这样不会因为某一个查询造成阻塞,因此单个并行子任务可以连续发送多个请求,从而提高并发效率。对于涉及网络IO的操作,可以显著减少因为请求等待带来的性能损耗。
6)异步 IO 图解
7)模板方法设计模式
(1)定义
在父类中定义完成某一个功能的核心算法骨架,具体的实现可以延迟到子类中完成。模板方法类一定是抽象类,里面有一套具体的实现流程(可以是抽象方法也可以是普通方法)。这些方法可能由上层模板继承而来。
(2)优点
在不改变父类核心算法骨架的前提下,每一个子类都可以有不同的实现。我们只需要关注具体方法的实现逻辑而不必在实现流程上分心。
本程序中定义了模板类 DimAsyncFunction,在其中定义了维度关联的具体流程
a)根据流中对象获取维度主键。
b)根据维度主键获取维度对象。
c)用上一步的查询结果补全流中对象的维度信息。
8)去重思路分析
我们在 DWD 层提到,订单明细表数据生成过程中会形成回撤流。left join 生成的数据集中,相同唯一键的数据可能会有多条。上文已有讲解,不再赘述。回撤数据在 Kafka 中以 null 值的形式存在,只需要简单判断即可过滤。我们需要考虑的是如何对其余数据去重。
对回撤流数据生成过程进行分析,可以发现,字段内容完整数据的生成一定晚于不完整数据的生成,要确保统计结果的正确性,我们应保留字段内容最全的数据,基于以上论述,内容最全的数据生成时间最晚。要想通过时间筛选这部分数据,首先要获取数据生成时间。上文已经对FlinkSQL中几个获取当前时间戳的函数进行了讲解,此处不再赘述。获取时间之后要考虑如何比较时间,保留时间最大的数据,由此引出时间比较工具类。
(1)时间比较工具类
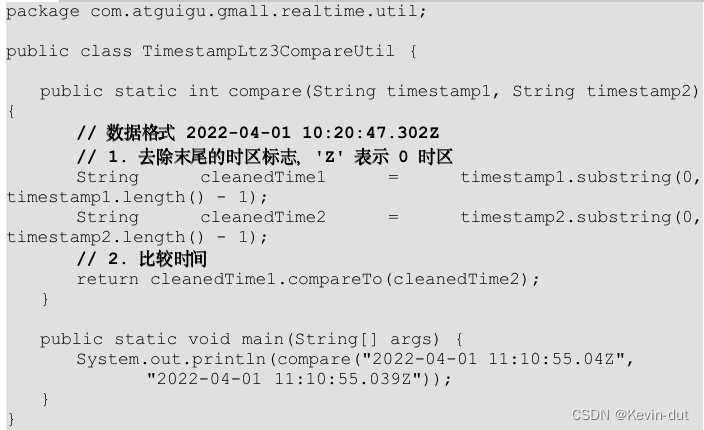
动态表中获取的数据生成时间精确到毫秒,前文提供的日期格式化工具类无法实现此类日期字符串向时间戳的转化,也就不能通过直接转化为时间戳的方式比较两条数据的生成时间。因此,单独封装工具类用于比较 TIME_STAMP(3) 类型的时间。比较逻辑是将时间拆分成两部分:小数点之前和小数点之后的。小数点之前的日期格式为 yyyy-MM-dd HH:mm:ss,这部分可以直接转化为时间戳比较,如果这部分时间相同,再比较小数点后面的部分,将小数点后面的部分转换为整型比较,从而实现 TIME_STAMP(3) 类型时间的比较。
(2)去重思路
获取了数据生成时间,接下来要考虑的问题就是如何获取生成时间最晚的数据。此处提供两种思路。
① 按照唯一键分组,开窗,在窗口闭合前比较窗口中所有数据的时间,将生成时间最晚的数据发送到下游,其它数据舍弃。
② 按照唯一键分组,对于每一个唯一键,维护状态和定时器,当状态中数据为 null 时注册定时器,把数据维护到状态中。此后每来一条数据都比较它与状态中数据的生成时间,状态中只保留生成最晚的数据。如果两条数据生成时间相同(系统时间精度不足),则保留后进入算子的数据。因为我们的 Flink 程序并行度和 Kafka 分区数相同,可以保证数据有序,后来的数据就是最新的数据。
两种方案都可行,此处选择方案二。
本节数据来源于 Kafka dwd_trade_order_detail 主题,后者的数据来源于 Kafka dwd_trade_order_pre_process 主题,dwd_trade_order_pre_process 数据生成过程中使用了 left join,因此包含 null 数据和重复数据。订单明细表读取数据使用的 Kafka Connector 会过滤掉 null 数据,程序内只做了过滤没有去重,因此该表不存在 null 数据,但对于相同唯一键 order_detail_id 存在重复数据。综上,订单明细表存在唯一键 order_detail_id 相同的数据,但不存在 null 数据,因此仅须去重。
9)执行步骤
(1)从 Kafka 订单明细主题读取数据
(2)转换数据结构
(3)按照唯一键去重
(4)转换数据结构
JSONObject 转换为实体类 TradeSkuOrderBean。
(5)设置水位线
(6)分组、开窗、聚合
按照维度信息分组,度量字段求和,并在窗口闭合后补充窗口起始时间和结束时间。将时间戳置为当前系统时间。
(7)维度关联,补充维度字段
① 关联 sku_info 表
获取 sku_name,tm_id,category3_id,spu_id。
② 关联 spu_info 表
获取 spu_name。
③ 关联 base_trademark 表
获取 tm_name。
④ 关联 base_category3 表
获取 name(三级品类名称),获取 category2_id。
⑤ 关联 base_categroy2 表
获取 name(二级品类名称),category1_id。
⑥ 关联 base_category1 表
获取 name(一级品类名称)。
(8)写出到 ClickHouse。
10.3.3 图解
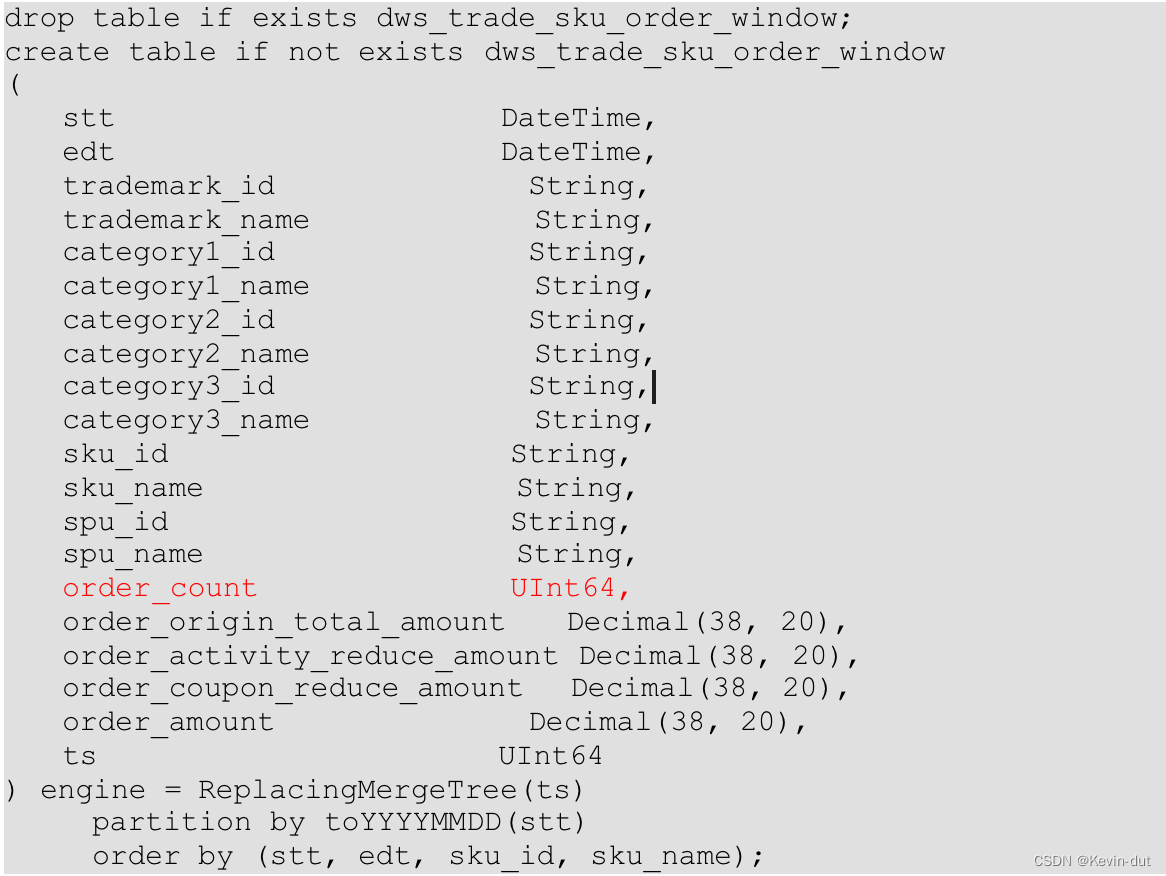
10.3.4 ClickHouse 建表语句
10.3.5 代码
(1)补充 Jedis 相关依赖

Jedis 是一个用于 Java 语言的 Redis 客户端库,用于与 Redis 服务器进行通信。Redis 是一个内存键值存储数据库,支持各种数据结构,如字符串、哈希、列表、集合等,同时具有持久化、复制、客户端分区等功能。Jedis 提供了一组 Java API,使得开发人员可以方便地使用 Java 与 Redis 进行交互。
以下是 Jedis 提供的一些主要功能和特性:
-
连接池管理:Jedis 提供了连接池管理功能,可以在应用程序中维护一组与 Redis 服务器的连接,以提高连接的复用率和性能。
-
简单易用的 API:Jedis 提供了简单易用的 API,封装了与 Redis 服务器交互的各种操作,如设置键值对、获取键值对、执行命令等。
-
数据类型支持:Jedis 支持 Redis 中的各种数据类型,如字符串、哈希、列表、集合、有序集合等,提供了相应的 API 来操作这些数据类型。
-
事务支持:Jedis 支持事务操作,可以将多个操作组合成一个事务,保证这些操作的原子性。
-
发布-订阅模式:Jedis 支持发布-订阅模式,可以实现消息的发布和订阅,用于实现消息队列、事件通知等功能。
-
管道操作:Jedis 支持管道操作,可以将多个命令打包发送到 Redis 服务器,减少网络开销和提高性能。
-
支持 Redis 集群:Jedis 支持与 Redis 集群进行通信,可以对 Redis 集群进行读写操作。
总的来说,Jedis 是一个功能强大、简单易用的 Java Redis 客户端库,适用于各种 Java 应用程序中与 Redis 服务器进行交互的场景。它提供了丰富的功能和灵活的 API,使得开发人员可以方便地使用 Redis 数据库进行数据存储和处理。
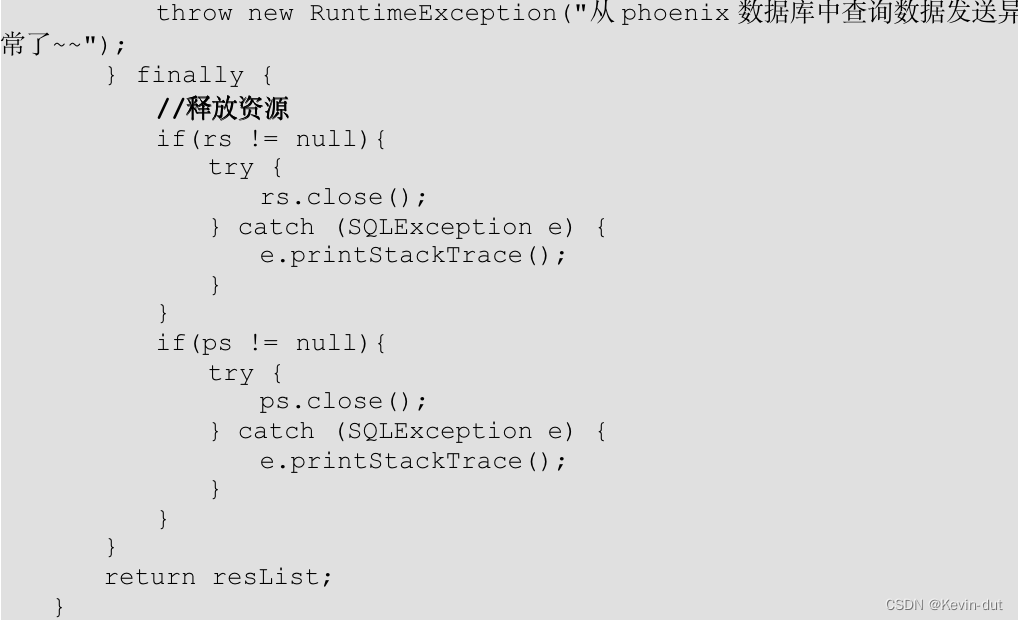
(2)Phoenix 查询数据方法 queryList()

(3)Jedis 工具类 JedisUtil
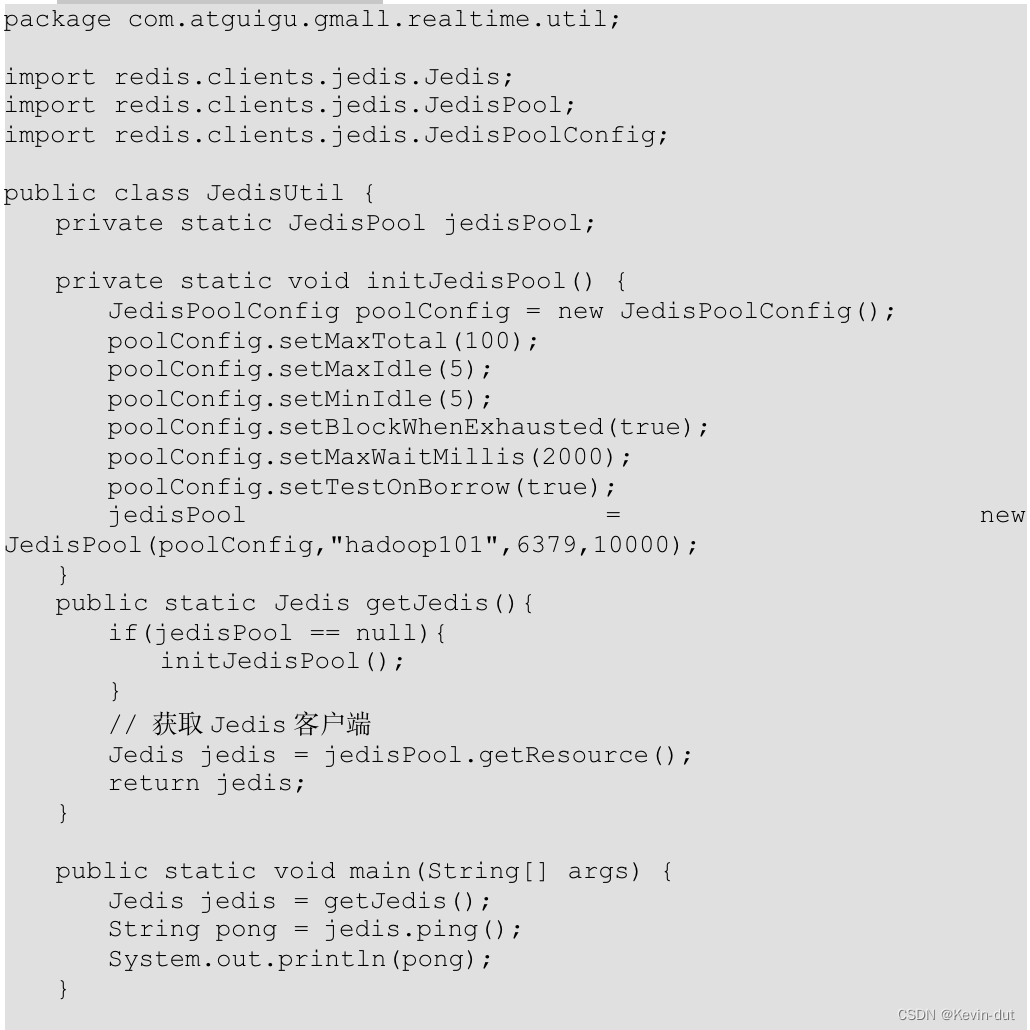
(4)维度查询工具类 DimUtil



(5)修改 MyBroadcastFunction 中的 processElement 方法
补充操作类型字段,用于清除过期缓存,当操作类型为 update 时,清除缓存。
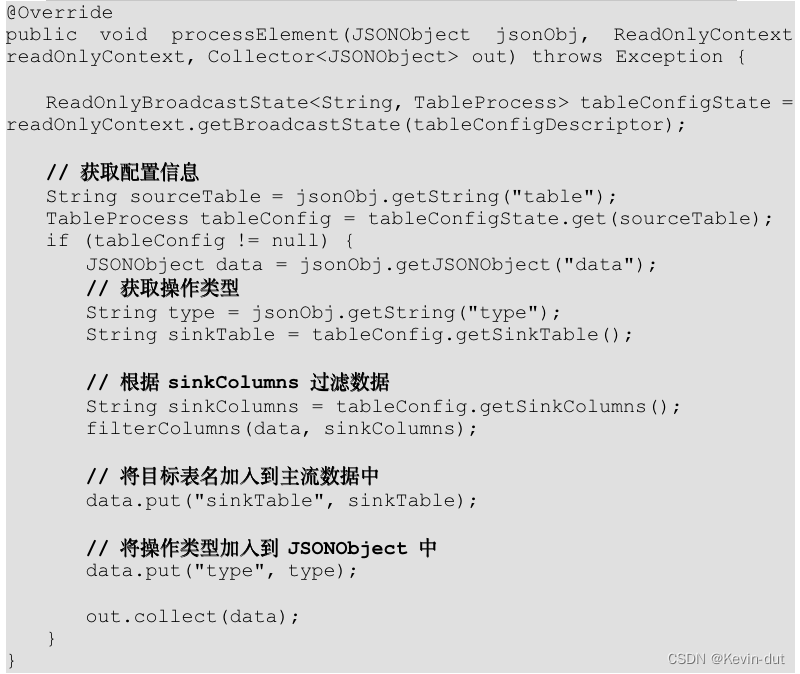
(6)在 DimUtil 中补充 deleteCached 方法,用于清除过期缓存。

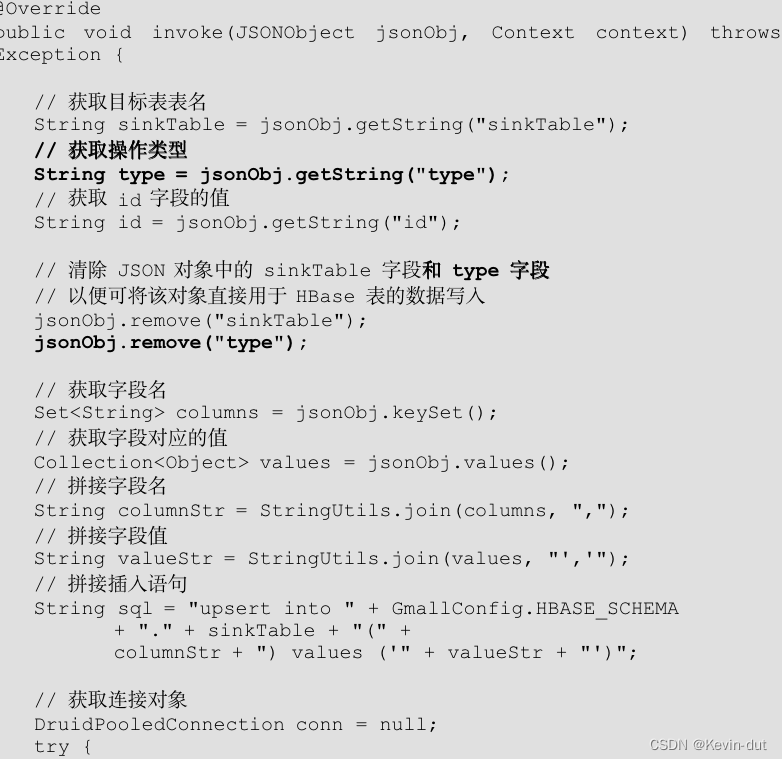
(7)修改 MyPhoenixSink 类中的 invoke 方法,补充对于操作类型的判断,当操作类型为修改(update)时清除缓存,并补充写入 HBase 之前 JSON 对象中 type 字段的清除操作。
(8)模板方法设计模式模板接口 DimJoinFunction

(9)线程池工具类 ThreadPoolUtil
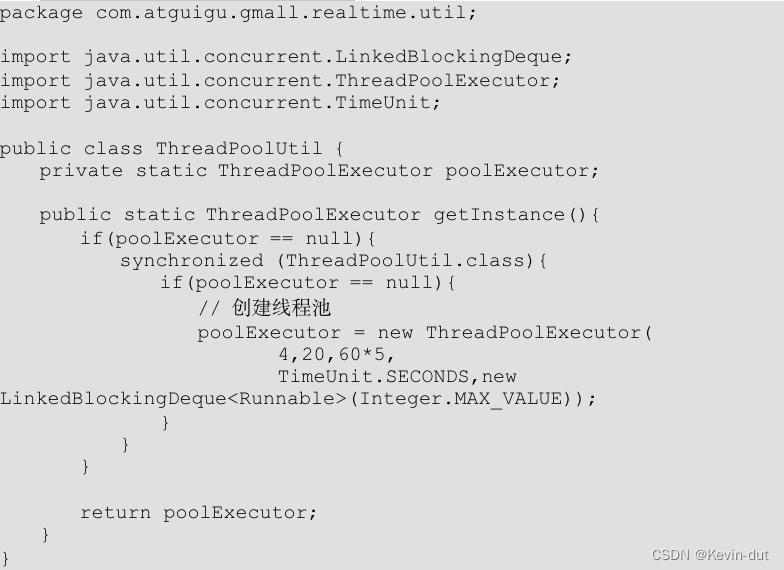
(10)异步 IO 函数 DimAsyncFunction


11)FlinkSQL 时间数据类型 TimestampLtz3 比较工具类 TimestampLtz3CompareUtil
(12)实体类 TradeSkuOrderBean


(13)主程序
package com.atguigu.gmall.realtime.app.dws;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.atguigu.gmall.realtime.app.func.DimAsyncFunction;
import com.atguigu.gmall.realtime.bean.TradeSkuOrderBean;
import com.atguigu.gmall.realtime.util.ClickHouseUtil;
import com.atguigu.gmall.realtime.util.DateFormatUtil;
import com.atguigu.gmall.realtime.util.KafkaUtil;
import com.atguigu.gmall.realtime.util.TimestampLtz3CompareUtil;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.runtime.state.hashmap.HashMapStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.io.IOException;
import java.time.Duration;
import java.util.concurrent.TimeUnit;
public class DwsTradeSkuOrderWindow {
public static void main(String[] args) throws Exception {
// TODO 1. 环境准备
Configuration conf = new Configuration();
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
env.setParallelism(4);
// TODO 2. 状态后端设置
env.enableCheckpointing(3000L, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60 * 1000L);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000L);
env.getCheckpointConfig().enableExternalizedCheckpoints(
CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION
);
env.setRestartStrategy(
RestartStrategies.failureRateRestart(
3, Time.days(1L), Time.minutes(1L)
)
);
env.setStateBackend(new HashMapStateBackend());
env.getCheckpointConfig().setCheckpointStorage(
"hdfs://HDFS4000900/ck"
);
System.setProperty("HADOOP_USER_NAME", "atguigu");
// TODO 3. 从 Kafka dwd_trade_order_detail 主题读取下单明细数据
String topic = "dwd_trade_order_detail";
String groupId = "dws_trade_sku_order_window";
FlinkKafkaConsumer<String> kafkaConsumer = KafkaUtil.getKafkaConsumer(topic, groupId);
DataStreamSource<String> source = env.addSource(kafkaConsumer);
// TODO 4. 过滤字段不完整数据并转换数据结构
SingleOutputStreamOperator<String> filteredDS = source.filter(
new FilterFunction<String>() {
@Override
public boolean filter(String jsonStr) throws Exception {
JSONObject jsonObj = JSON.parseObject(jsonStr);
String userId = jsonObj.getString("user_id");
String sourceTypeName = jsonObj.getString("source_type_name");
return userId != null && sourceTypeName != null;
}
}
);
SingleOutputStreamOperator<JSONObject> mappedStream = filteredDS.map(JSON::parseObject);
// TODO 5. 按照 order_detail_id 分组
KeyedStream<JSONObject, String> keyedStream = mappedStream.keyBy(r -> r.getString("id"));
// TODO 6. 去重
SingleOutputStreamOperator<JSONObject> processedStream = keyedStream.process(
new KeyedProcessFunction<String, JSONObject, JSONObject>() {
private ValueState<JSONObject> lastValueState;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
lastValueState = getRuntimeContext().getState(
new ValueStateDescriptor<JSONObject>("last_value_state", JSONObject.class)
);
}
@Override
public void processElement(JSONObject jsonObj, Context ctx, Collector<JSONObject> out) throws Exception {
JSONObject lastValue = lastValueState.value();
if (lastValue == null) {
long currentProcessingTime = ctx.timerService().currentProcessingTime();
ctx.timerService().registerProcessingTimeTimer(currentProcessingTime + 5000L);
lastValueState.update(jsonObj);
} else {
String lastRowOpTs = lastValue.getString("row_op_ts");
String rowOpTs = jsonObj.getString("row_op_ts");
if (TimestampLtz3CompareUtil.compare(lastRowOpTs, rowOpTs) <= 0) {
lastValueState.update(jsonObj);
}
}
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<JSONObject> out) throws IOException {
JSONObject lastValue = this.lastValueState.value();
if (lastValue != null) {
out.collect(lastValue);
}
lastValueState.clear();
}
}
);
// TODO 7. 转换数据结构
SingleOutputStreamOperator<TradeSkuOrderBean> javaBeanStream = processedStream.map(
jsonObj -> {
String skuId = jsonObj.getString("sku_id");
Double splitOriginalAmount = jsonObj.getDouble("split_original_amount");
Double splitActivityAmount = jsonObj.getDouble("split_activity_amount");
Double splitCouponAmount = jsonObj.getDouble("split_coupon_amount");
Double splitTotalAmount = jsonObj.getDouble("split_total_amount");
Long ts = jsonObj.getLong("ts") * 1000L;
TradeSkuOrderBean trademarkCategoryUserOrderBean = TradeSkuOrderBean.builder()
.skuId(skuId)
.originalAmount(splitOriginalAmount)
.activityAmount(splitActivityAmount == null ? 0.0 : splitActivityAmount)
.couponAmount(splitCouponAmount == null ? 0.0 : splitCouponAmount)
.orderAmount(splitTotalAmount)
.ts(ts)
.build();
return trademarkCategoryUserOrderBean;
}
);
// TODO 8. 设置水位线
SingleOutputStreamOperator<TradeSkuOrderBean> withWatermarkDS = javaBeanStream.assignTimestampsAndWatermarks(
WatermarkStrategy
.<TradeSkuOrderBean>forBoundedOutOfOrderness(Duration.ofSeconds(5L))
.withTimestampAssigner(
new SerializableTimestampAssigner<TradeSkuOrderBean>() {
@Override
public long extractTimestamp(TradeSkuOrderBean javaBean, long recordTimestamp) {
return javaBean.getTs();
}
}
)
);
// TODO 9. 分组
KeyedStream<TradeSkuOrderBean, String> keyedForAggregateStream = withWatermarkDS.keyBy(
new KeySelector<TradeSkuOrderBean, String>() {
@Override
public String getKey(TradeSkuOrderBean javaBean) throws Exception {
return javaBean.getSkuId();
}
}
);
// TODO 10. 开窗
WindowedStream<TradeSkuOrderBean, String, TimeWindow> windowDS = keyedForAggregateStream.window(TumblingEventTimeWindows.of(
org.apache.flink.streaming.api.windowing.time.Time.seconds(10L)));
// TODO 11. 聚合
SingleOutputStreamOperator<TradeSkuOrderBean> reducedStream = windowDS
.reduce(
new ReduceFunction<TradeSkuOrderBean>() {
@Override
public TradeSkuOrderBean reduce(TradeSkuOrderBean value1, TradeSkuOrderBean value2) throws Exception {
value1.setOriginalAmount(value1.getOriginalAmount() + value2.getOriginalAmount());
value1.setActivityAmount(value1.getActivityAmount() + value2.getActivityAmount());
value1.setCouponAmount(value1.getCouponAmount() + value2.getCouponAmount());
value1.setOrderAmount(value1.getOrderAmount() + value2.getOrderAmount());
return value1;
}
},
new ProcessWindowFunction<TradeSkuOrderBean, TradeSkuOrderBean, String, TimeWindow>() {
@Override
public void process(String key, Context context, Iterable<TradeSkuOrderBean> elements, Collector<TradeSkuOrderBean> out) throws Exception {
String stt = DateFormatUtil.toYmdHms(context.window().getStart());
String edt = DateFormatUtil.toYmdHms(context.window().getEnd());
for (TradeSkuOrderBean element : elements) {
element.setStt(stt);
element.setEdt(edt);
element.setTs(System.currentTimeMillis());
out.collect(element);
}
}
}
);
// TODO 12. 维度关联,补充与分组无关的维度字段
// 12.1 关联 sku_info 表
SingleOutputStreamOperator<TradeSkuOrderBean> withSkuInfoStream = AsyncDataStream.unorderedWait(
reducedStream,
new DimAsyncFunction<TradeSkuOrderBean>("dim_sku_info".toUpperCase()) {
@Override
public void join(TradeSkuOrderBean javaBean, JSONObject jsonObj) throws Exception {
javaBean.setSkuName(jsonObj.getString("sku_name".toUpperCase()));
javaBean.setTrademarkId(jsonObj.getString("tm_id".toUpperCase()));
javaBean.setCategory3Id(jsonObj.getString("category3_id".toUpperCase()));
javaBean.setSpuId(jsonObj.getString("spu_id".toUpperCase()));
}
@Override
public String getKey(TradeSkuOrderBean javaBean) {
return javaBean.getSkuId();
}
},
60 * 5, TimeUnit.SECONDS
);
// 12.2 关联 spu_info 表
SingleOutputStreamOperator<TradeSkuOrderBean> withSpuInfoStream = AsyncDataStream.unorderedWait(
withSkuInfoStream,
new DimAsyncFunction<TradeSkuOrderBean>("dim_spu_info".toUpperCase()) {
@Override
public void join(TradeSkuOrderBean javaBean, JSONObject dimJsonObj) throws Exception {
javaBean.setSpuName(
dimJsonObj.getString("spu_name".toUpperCase())
);
}
@Override
public String getKey(TradeSkuOrderBean javaBean) {
return javaBean.getSpuId();
}
},
60 * 5, TimeUnit.SECONDS
);
// 12.3 关联品牌表 base_trademark
SingleOutputStreamOperator<TradeSkuOrderBean> withTrademarkStream = AsyncDataStream.unorderedWait(
withSpuInfoStream,
new DimAsyncFunction<TradeSkuOrderBean>("dim_base_trademark".toUpperCase()) {
@Override
public void join(TradeSkuOrderBean javaBean, JSONObject jsonObj) throws Exception {
javaBean.setTrademarkName(jsonObj.getString("tm_name".toUpperCase()));
}
@Override
public String getKey(TradeSkuOrderBean javaBean) {
return javaBean.getTrademarkId();
}
},
5 * 60, TimeUnit.SECONDS
);
// 12.4 关联三级分类表 base_category3
SingleOutputStreamOperator<TradeSkuOrderBean> withCategory3Stream = AsyncDataStream.unorderedWait(
withTrademarkStream,
new DimAsyncFunction<TradeSkuOrderBean>("dim_base_category3".toUpperCase()) {
@Override
public void join(TradeSkuOrderBean javaBean, JSONObject jsonObj) throws Exception {
javaBean.setCategory3Name(jsonObj.getString("name".toUpperCase()));
javaBean.setCategory2Id(jsonObj.getString("category2_id".toUpperCase()));
}
@Override
public String getKey(TradeSkuOrderBean javaBean) {
return javaBean.getCategory3Id();
}
},
5 * 60, TimeUnit.SECONDS
);
// 12.5 关联二级分类表 base_category2
SingleOutputStreamOperator<TradeSkuOrderBean> withCategory2Stream = AsyncDataStream.unorderedWait(
withCategory3Stream,
new DimAsyncFunction<TradeSkuOrderBean>("dim_base_category2".toUpperCase()) {
@Override
public void join(TradeSkuOrderBean javaBean, JSONObject jsonObj) throws Exception {
javaBean.setCategory2Name(jsonObj.getString("name".toUpperCase()));
javaBean.setCategory1Id(jsonObj.getString("category1_id".toUpperCase()));
}
@Override
public String getKey(TradeSkuOrderBean javaBean) {
return javaBean.getCategory2Id();
}
},
5 * 60, TimeUnit.SECONDS
);
// 12.6 关联一级分类表 base_category1
SingleOutputStreamOperator<TradeSkuOrderBean> withCategory1Stream = AsyncDataStream.unorderedWait(
withCategory2Stream,
new DimAsyncFunction<TradeSkuOrderBean>("dim_base_category1".toUpperCase()) {
@Override
public void join(TradeSkuOrderBean javaBean, JSONObject jsonObj) throws Exception {
javaBean.setCategory1Name(jsonObj.getString("name".toUpperCase()));
}
@Override
public String getKey(TradeSkuOrderBean javaBean) {
return javaBean.getCategory1Id();
}
},
5 * 60, TimeUnit.SECONDS
);
// TODO 13. 写出到 OLAP 数据库
SinkFunction<TradeSkuOrderBean> jdbcSink =
ClickHouseUtil.<TradeSkuOrderBean>getJdbcSink(
"insert into dws_trade_sku_order_window values(?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)"
);
withCategory1Stream.<TradeSkuOrderBean>addSink(jdbcSink);
env.execute();
}
}














 996
996











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









