







这是第一篇关于big data的文章,首先来搭建一个ubuntu 14.04 LTS 系统的hadoop 2.x 的一个伪分布式环境。
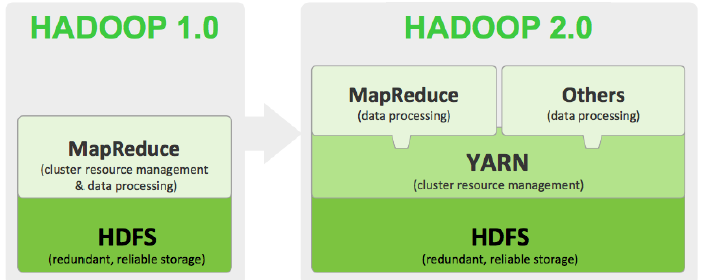
Hadoop 1.x 和 2.x 架构
修改ubuntu的hostname 和hosts
修改hostname为kuyu
$ sudo vim /etc/hostname在hosts中添加192.168.128.134 kuyu,其中192.168.128.134 是主机的ip地址,可以通过 ifconfig 命令查询得到.
$ sudo vim /etc/hosts安装JDK
hadoop官网介绍推荐安装的jdk版本是jdk1.6和jdk1.7,所以在Oracle 官网下载JDK 7 .
# 解压JDK
$ tar -zxvf jdk-*-linux-x64.tar.gz
# 重命令jdk* 为java
$ mv jdk*/ java
# 移动java到/usr/local 目录下
$ sudo mv java/ /usr/local/
# 配置环境变量
$ sudo vim /etc/profile
export JAVA_HOME=/usr/local/java
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOM/jre/lib
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
# source
$ source /etc/profile安装Hadoop
在hadoop的官方滤镜下载hadoop的最新稳定版hadoop 2.x
# 解压hadoop
$ tar -zxvf hadoop-2.*.*.tar.gz
# 重命令hadoop-2.*.*为hadoop
$ mv hadoop-2.*.* hadoop
# 移动hadoop到/usr/local 目录下
$ sudo mv hadoop/ /usr/local/
# 配置环境变量
$ sudo vim /etc/profile
# hadoop
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# source
$ source /etc/profile除此之外,我们还需要修改hadoop的配置文件
$ cd /usr/local/hadoop/etc/hadoophadoop-env.sh
#添加java 安装路径
$ export JAVA_HOME=/usr/local/javaCore-site.xml
<configuration>
<!-- 指定HDFS namenode的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://kuyu:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/loca/hadoop/tmp</value>
</property>
</configuration>hdfs-site.xml
<configuration>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/dfs.data/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/dfs.data/data</value>
</property>
</configuration>
mapred-site.xml
如果mapred-site.xml 没有的话,需要cp一份
$ cp mapred-site.xml.template mapred-site.xml<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>yarn-site.xml
<configuration>
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>kuyu</value>
</property>
</configuration>注意
在安装hadoop 的时候另外指定了两个目录/usr/local/hadoop/tmp 和 /usr/local/hadoop/dfs.data, 需要事先创建
$ mkdir /usr/local/hadoop/tmp
$ mkdir /usr/local/hadoop/dfs.data格式化 Hadoop
$ hdfs namenode -format测试hadoop
# 启动hadoop
$ start-dfs.sh
$ start-yarn.sh
# 上传文件
$ hadoop fs -put [ubuntu file path] [hdfs file path]
# 下载文件
$ hadoop fs -get [hdfs file path] [ubuntu file path]
#运行wordconut 代码
$ hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount [hdfs file input path] [hdfs file output path]














 2479
2479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









