







装好scrapy框架和一些相关的包后,为了方便,设置好系统变量,如果你电脑装了多个python版本,要把你需要用的python版本的路径写在系统变量PATH的最前面

现在E:\python learn下建一个文件夹scrapy test,接着运行命令行转到新建的文件夹下。
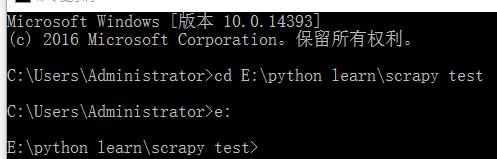
运行命令scrapy startproject article新建项目 目录,

再转到项目目录下

输入scrapy genspider book quanshuwang.com,创建爬虫框架,其中book为爬虫名字,quanshuwang.com为待爬取网站的域名。

以上步骤即可创建简单的爬虫框架。
进入pycharm软件,导入刚才创建的目录,在与scrapy.cfg同级下创建main.py,
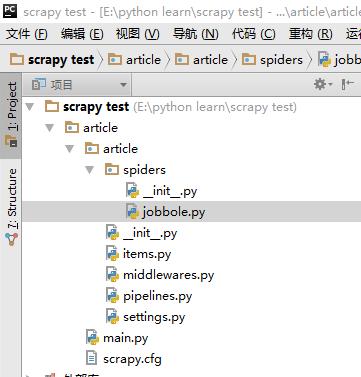
此文件是用来运行的文件,输入以下内容

以后运行爬虫时运行这个main.py就行。
jobbole.py既是爬虫具体实现的文件,为测试,输入以下代码用来爬取全书网的网站地图里的所有书籍详情页的网址并打印出来。:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
from urllib import parse
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['quanshuwang.com'] #待爬取网站的域名
start_urls = ['http://www.quanshuwang.com/map/1.html'] #开始爬取的网址
global j
j=1
def parse(self, response):
i=1
post_urls=response.css("a[target='_blank']::attr(href)").extract() #用CSS选择器从html页面中得到相应的网址
for post_url in post_urls:
print(str(i)+":"+post_url)
i=i+1
yield Request(url=parse.urljoin(response.url,post_url),callback=self.parse_detail)#parse可以自动拼接域名和网页相对地址 #1.获取网站地图里的小说详情页的网址URL并交给解析函数处理 #yield可以将url交给scrapy进行下载
#提取下一页并交付给scrapy下载 global j j=j+1 next_url='http://www.quanshuwang.com/map/%s.html'%j print(next_url) if next_url: yield Request(url=next_url,callback=self.parse) #2.获取下一页的URL并交给scrapy进行下载,下载完成后交给parse def parse_detail(self,response): #解析函数,具体写将要爬取此页面的什么内容 pass写完后,直接运行main.py就能得到结果。
这是一次简单的测试。















 341
341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









