 Python垃圾回收机制:引用计数与循环引用解决方案
Python垃圾回收机制:引用计数与循环引用解决方案





一、垃圾回收机制详解
1.1、简介
python 采用的是引用计数机制为主,标记 - 清除和分代收集两种机制为辅的策略
引用计数(python默认):记录该对象当前被引用的次数,每当新的引用指向该对象时,它的引用计数ob_ref加1,每当该对象的引用失效时计数ob_ref减1,一旦对象的引用计数为0,该对象立即被回收
标记清除:第一段给所有活动对象标记,第二段清除非活动对象
分代回收:python将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代,比如有年轻代、中年代、老年代,年轻代最先被回收
GC作为现代编程语言的自动内存管理机制,专注于两件事:1. 找到内存中无用的垃圾资源 2. 清除这些垃圾并把内存让出来给其他对象使用。
1.2、引用计数
Python语言默认采用的垃圾收集机制是『引用计数法 Reference Counting』,该算法最早George E. Collins在1960的时候首次提出,50年后的今天,该算法依然被很多编程语言使用。
『引用计数法』的原理是:每个对象维护一个ob_ref字段,用来记录该对象当前被引用的次数,每当新的引用指向该对象时,它的引用计数ob_ref加1,每当该对象的引用失效时计数ob_ref减1,一旦对象的引用计数为0,该对象立即被回收,对象占用的内存空间将被释放。
它的缺点是需要额外的空间维护引用计数,这个问题是其次的,不过最主要的问题是它不能解决对象的“循环引用”,因此,也有很多语言比如Java并没有采用该算法做来垃圾的收集机制。
引用计数就是:变量值被变量名关联的次数
如:age=18
变量值18被关联了一个变量名age,称之为引用计数为1
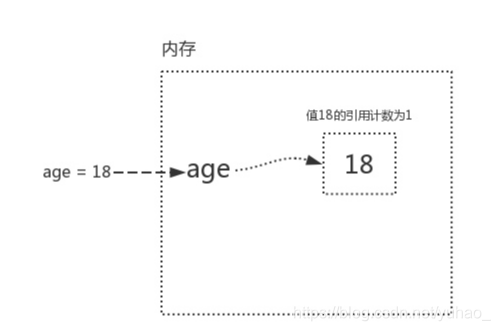
引用计数增加:
age=18 (此时,变量值18的引用计数为1)
m=age (把age的内存地址给了m,此时,m,age都关联了18,所以变量值18的引用计数为2)
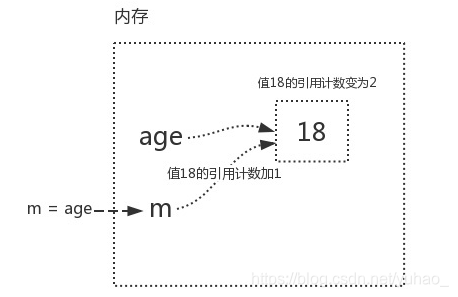
引用计数减少:
age=10(名字age先与值18解除关联,再与3建立了关联,变量值18的引用计数为1)
del m(del的意思是解除变量名x与变量值18的关联关系,此时,变量18的引用计数为0)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-481UH4li-1624363438263)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20210622165956508.png)]](https://i-blog.csdnimg.cn/blog_migrate/9ae5136094fe2605329e8d0dfc2fa9ff.png)
值18的引用计数一旦变为0,其占用的内存地址就应该被解释器的垃圾回收机制回收
注
导致引用计数+1的情况
对象被创建,例如a=23
对象被引用,例如b=a
对象被作为参数,传入到一个函数中,例如func(a)
对象作为一个元素,存储在容器中,例如list1=[a,a]`
导致引用计数-1的情况
对象的别名被显式销毁,例如del a
对象的别名被赋予新的对象,例如a=24
一个对象离开它的作用域,例如f函数执行完毕时,func函数中的局部变量(全局变量不会)
对象所在的容器被销毁,或从容器中删除对象
1.3、引用计数带来的问题与解决方案
引用计数带来的问题为循环引用(交叉引用)
# 如下我们定义了两个列表,简称列表1与列表2,变量名l1指向列表1,变量名l2指向列表2
>>> l1=['xxx'] # 列表1被引用一次,列表1的引用计数变为1
>>> l2=['yyy'] # 列表2被引用一次,列表2的引用计数变为1
>>> l1.append(l2) # 把列表2追加到l1中作为第二个元素,列表2的引用计数变为2
>>> l2.append(l1) # 把列表1追加到l2中作为第二个元素,列表1的引用计数变为2
# l1与l2之间有相互引用
# l1 = ['xxx'的内存地址,列表2的内存地址]
# l2 = ['yyy'的内存地址,列表1的内存地址]
>>> l1
['xxx', ['yyy', [...]]]
>>> l2
['yyy', ['xxx', [...]]]
>>> l1[1][1][0]
'xxx'
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0y52SnAe-1624363438264)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20210622172011482.png)]](https://i-blog.csdnimg.cn/blog_migrate/7c681275ca6e989b9a5d79fd4ba39e07.png)
循环引用会导致:值不再被任何名字关联,但是值的引用计数并不会为0,应该被回收但不能被回收,如
>>> del l1 # 列表1的引用计数减1,列表1的引用计数变为1
>>> del l2 # 列表2的引用计数减1,列表2的引用计数变为1
只剩下列表1与列表2之间的相互引用
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g6BPjM53-1624363438265)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20210622172136797.png)]](https://i-blog.csdnimg.cn/blog_migrate/7e7602f3366d48b35137f710e1a73e06.png)
但此时两个列表的引用计数均不为0,但两个列表不再被任何其他对象关联,没有任何人可以再引用到它们,所以它俩占用内存空间应该被回收,但由于相互引用的存在,每一个对象的引用计数都不为0,因此这些对象所占用的内存永远不会被释放,所以循环引用是致命的,这与手动进行内存管理所产生的内存泄露毫无区别。 所以Python引入了“标记-清除” 与“分代回收”来分别解决引用计数的循环引用与效率低的问题
1.3.1、解決方案:标记-清除
容器对象(比如:list,set,dict,class,instance)都可以包含对其他对象的引用,所以都可能产生循环引用。而“标记-清除”计数就是为了解决循环引用的问题。
标记/清除算法的做法是当应用程序可用的内存空间被耗尽的时,就会停止整个程序,然后进行两项工作,第一项则是标记,第二项则是清除
标记的过程其实就是,遍历所有的GC Roots对象(栈区中的所有内容或者线程都可以作为GC Roots对象),然后将所有GC Roots的对象可以直接或间接访问到的对象标记为存活的对象,其余的均为非存活对象,应该被清除。
清除的过程将遍历堆中所有的对象,将没有标记的对象全部清除掉。
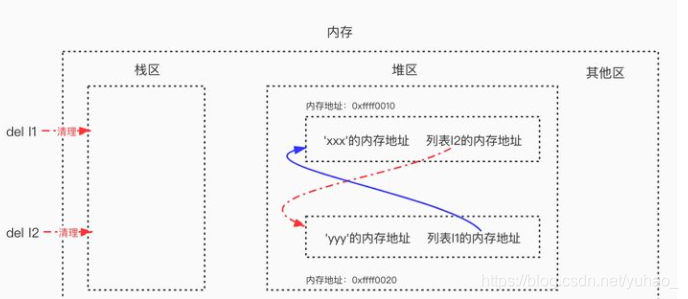
同时删除l1与l2时,会清理到栈区中l1与l2的内容以及直接引用关系。这样在启用标记清除算法时,从栈区出发,没有任何一条直接或间接引用可以访达l1与l2,即l1与l2成了“无根之人”,于是l1与l2都没有被标记为存活,二者会被清理掉,这样就解决了循环引用带来的内存泄漏问题。
1.3.2、效率问题–分代回收
分代回收是一种以空间换时间的操作方式,Python将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代,Python将内存分为了3“代”,分别为年轻代(第0代)、中年代(第1代)、老年代(第2代),他们对应的是3个链表,它们的垃圾收集频率与对象的存活时间的增大而减小。
新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推,老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。
同时,分代回收是建立在标记清除技术基础之上。分代回收同样作为Python的辅助垃圾收集技术处理那些容器对象
虽然分代回收可以起到提升效率的效果,但也存在一定的缺点:
例如一个变量刚刚从新生代移入青春代,该变量的绑定关系就解除了,该变量应该被回收,但青春代的扫描频率低于新生代,这就到导致了应该被回收的垃圾没有得到及时地清理。
毫无疑问,如果没有分代回收,即引用计数机制一直不停地对所有变量进行全体扫描,可以更及时地清理掉垃圾占用的内存,但这种一直不停地对所有变量进行全体扫描的方式效率极低,所以我们只能将二者中和。
综上
垃圾回收机制是在清理垃圾&释放内存的大背景下,允许分代回收以极小部分垃圾不会被及时释放为代价,以此换取引用计数整体扫描频率的降低,从而提升其性能,这是一种以空间换时间的解决方案目录

















 135
135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









