







Description:
Given a collection of candidate numbers (C) and a target number (T), find all unique combinations in C where the candidate numbers sums to T.
Each number in C may only be used once in the combination.
Note:
- All numbers (including target) will be positive integers.
- The solution set must not contain duplicate combinations.
For example, given candidate set [10, 1, 2, 7, 6, 1, 5] and target 8,
A solution set is:
[ [1, 7], [1, 2, 5], [2, 6], [1, 1, 6] ]————————————————————————————————————————————————————————————————————————
Solution:
原理和Combination Sum相同,只是这道题多了一个要求:同一个元素不能重复使用。
实际上可以直接在上一题的代码中,将局部数组压入全局数组前利用find函数查找是否含有相同子集,若有则不压入,否则压入。但是这种做法相当于每次成功配对时都要遍历一遍结果数组,是非常耗时的。因此可以考虑另一种思路:
排好序的数组中,相同的元素是紧挨着的,即相同元素中的第一个进入迭代的时候,会将后面所有元素包括与自身相同的元素的组合情况都考察了一遍,那么到后面相同元素进入迭代的时候就没必要再重复一遍工作了。因此可以想到,第一个元素迭代完后跳过剩下的相同元素,这样既省时又简便。但是要注意的是:跳过相同元素的步骤不能提到前面,即我们是以第一个相同元素的角度考虑的,而不是最后一个相同元素,否则就会漏掉许多可能结果。
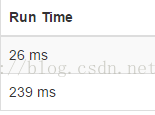
这里只给出两种算法的时间对比:上面是第二种跳过相同元素的思路,下面是使用find函数思路,可见时间差距有多大,而且随着测试用例的增大,差距会越来越大。
具体代码请参照Combination Sum.

















 305
305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









