







1.主机规划
a.准备4台centos虚拟机分别是hadoop61,hadoop62,hadoop63,hadoop64(分别修改每一台hostname值(vi /etc/sysconfig/network)为对应的值)
b.所有机器的host文件内容修改(vi /etc)为如下:
192.168.100.61 hadoop61
192.168.100.62 hadoop62
192.168.100.63 hadoop63
192.168.100.64 hadoop64

2.配置SSH无密码登录(
仅在hadoop61上执行
)
//生成密钥对
[root@]# ssh-keygen –t rsa //直接四个回车
//复制公钥到其他机器(中途输入目标机的密码)
[root@]# ssh-xcopy-id hadoop61
[root@]# ssh-xcopy-id hadoop62
[root@]# ssh-xcopy-id hadoop63
[root@]# ssh-xcopy-id hadoop64
//以后hadoop61访问另外几台机器就不用输入密码(反过来不成立),
3.
安装64位
(官网下载的都是32位)hadoop-xxx.tar.gz(
所有机器都执行如下操作
)
a.解压文件
[root@]# tar -zxvf hadoop-xxx.tar.gz
目录结构如下:
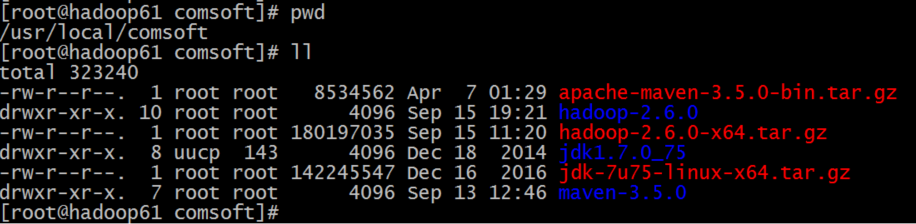
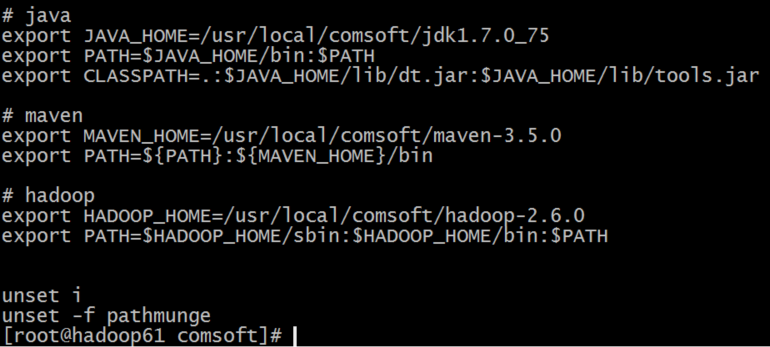
b.配置环境变量
[root@]# vi /etc/profile
添加内容如下:
# hadoop
export HADOOP_HOME=/usr/local/comsoft/hadoop-2.6.0
export PATH=$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH
c.修该hadoop的配置文件
[root@hadoop61 comsoft]# cd /usr/local/comsoft/hadoop-2.6.0/etc/hadoop/
c1.编辑hadoop-env.sh 和mapreduce-env.sh文件只需配置JAVA_HOME的值(export JAVA_HOME=/usr/local/comsoft/jdk1.7.0_75不能写成${JAVA_HOME}取环境变量的值)
c2.编辑slaves文件添加内容如下:
hadoop61
hadoop62
hadoop63
hadoop64
//指定集群中那几台机器为任务执行机
c3.编辑hdfs-site.xml
<configuration>
<property>
<name>dfs.secondary.http.address</name>
<value>hadoop61:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
//dfs.replication 配置的是数据文件备份的数量
c4.编辑mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
c5.编辑yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop61</value>
</property>
</configuration>
c6.编辑core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop61:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/softdata/data/hadoop/tmp</value>
</property>
</configuration>
c7.创建数据存储目录
[root@hadoop61 comsoft]# mkdir -p /softdata/data/hadoop/tmp
4.启动hadoop(
仅在hadoop61上执行,其他机器开机即可
)
//启动dfs
[root@hadoop61] # start-dfs.sh
//启动yarn
[root@hadoop61] # start-yarn.sh
5.常见问题分析
a.64位系统使用32位的hadoop
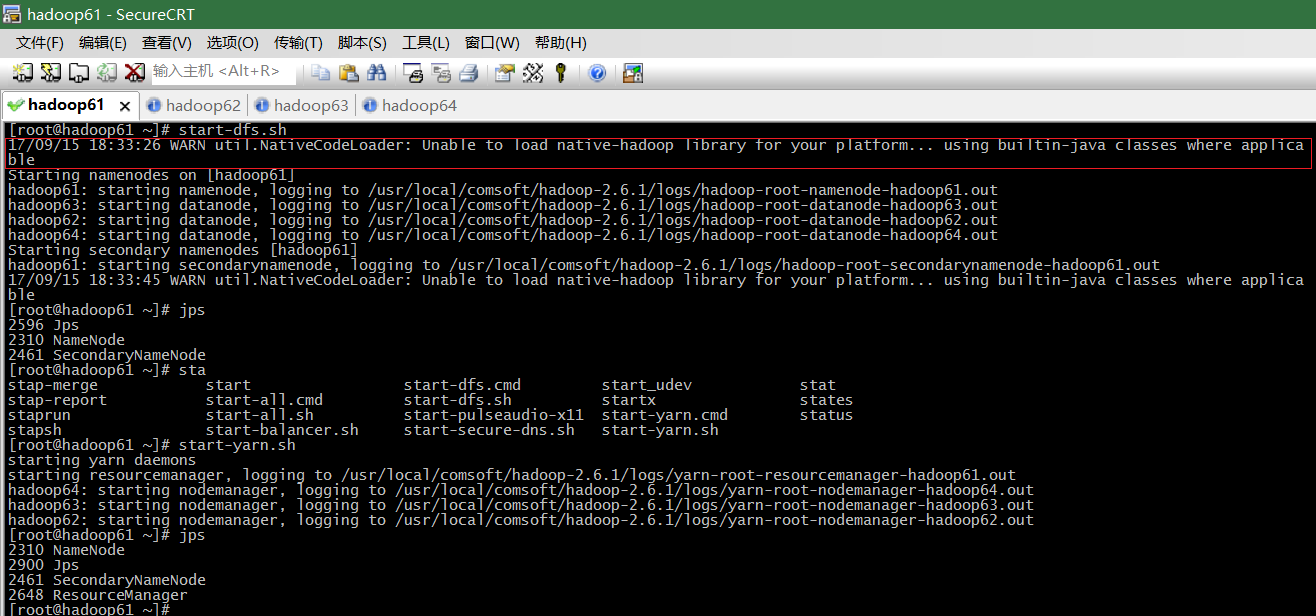
b.jps执行报错,原因java环境变量没有生效

c.jps命令看不到nameNode或者dataNode
在hadoop61上执行 stop-all.sh
清空所有机器上hadoop.tmp.di所指定的目录 rm -rf /softdata/data/hadoop/tmp
所有机器上执行格式化hadoop namenode -format
在hadoop61上执行 start-dfs.sh启动即可















 1424
1424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









