







摘自:http://www.cnblogs.com/lvpengms/p/3473961.html
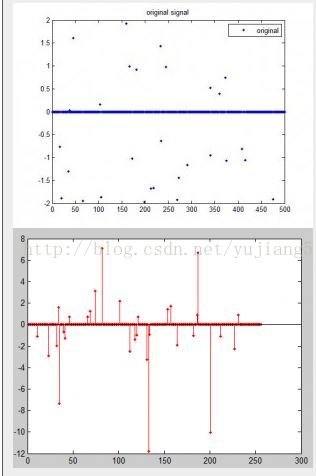
踏入“稀疏表达”(Sparse Representation)这个领域,纯属偶然中的必然。之前一直在研究压缩感知(Compressed Sensing)中的重构问题。照常理来讲,首先会找一维的稀疏信号(如下图)来验证CS理论中的一些原理,性质和算法,如测量矩阵为高斯随机矩阵,贝努 利矩阵,亚高斯矩阵时使用BP,MP,OMP等重构算法的异同和效果。然后会找来二维稀疏信号来验证一些问题。当然,就像你所想的,这些都太简单。是的, 接下来你肯定会考虑对于二维的稠密信号呢,如一幅lena图像?我们知道CS理论之所以能突破乃奎斯特采样定律,使用更少的采样信号来精确的还原原始信 号,其中一个重要的先验知识就是该信号的稀疏性,不管是本身稀疏,还是在变换域稀疏的。因此我们需要对二维的稠密信号稀疏化之后才能使用CS的理论完成重 构。问题来了,对于lena图像这样一个二维的信号,其怎样稀疏表示,在哪个变换域上是稀疏的,稀疏后又是什么?于是竭尽全力的google…后来发现了 马毅的“Image Super-Resolution via Sparse Representation”(IEEE Transactions on Image Processing,Nov.2010)这篇文章,于是与稀疏表达的缘分开始啦! [break] 谈到稀疏表示就不能不提下面两位的团队,Yi Ma ANDElad Michael,国内很多高校(像TSinghua,USTC)的学生直奔两位而去。(下图是Elad M的团队,后来知道了CS界大牛Donoho是Elad M的老师,怪不得…)其实对于马毅,之前稍有了解,因为韦穗老师,我们实验室的主任从前两年开始着手人脸识别这一领域并且取得了不错的成绩,人脸识别这个 领域马毅算是大牛了…因此每次开会遇到相关的问题,韦老师总会提到马毅,于是通过各种渠道也了解了一些有关他科研和个人的信息。至于Elad.M,恕我直 言,我在踏入这个领域其实真的完全不知道,只是最近文章看的比较多,发现看的文章中大部分的作者都有Elad,于是乎,好奇心驱使我了解了这位大牛以及他 的团队成员…也深深的了解到了一个团队对一个领域的贡献,从Elad.M那儿毕业的学生现在都成了这个领域中的佼佼者…不禁感叹到:一个好的导师是多么的 重要!!下面举个简单的例子,说说二维信号的稀疏性,也为后面将稀疏表示做个铺垫。我们以一幅大小为256×256的Lena图像为例,过完备字典 (Dictionary,具体含义见后文,先理解为基吧,其实不完全等同)选择离散余弦变换DCT,字典大小选择64×256,对图像进行分块处理,由于 仅仅为了说明稀疏性的概念,所以不进行重叠处理,每块大小8×8(pixel)…简单的稀疏表示后的稀疏如下图。可以看出,绝大多数的稀疏集中在0附近。 当然,这里仅仅是简单的说明一下。后面我们有更好的选择,比如说,字典的选择,图像块的选择等等…
http://www.win7soft.com/justplus/srstepbystep1 | JustPlus
-----------------------------------------------------
压缩感知(CS),或许你最近听说的比较多,不错,CS最近比较火,什么问题不管三七二十一就往上粘连,先试试能不能解决遇到的问题,能的话就把文 章发出来忽悠大家,这就是中国学术浮躁的表现…我们没有时间去思考的更多,因为你一思考,别人可能就把“你的东西”抢先发表了…不扯了,反正也干预不了… 稀疏表示的现状有点像CS,能做很多事,也不能做很多事…但是它确实是解决一些棘手问题的方法,至少能提供一种思路…目前用稀疏表示解决的问题主要集中在 图像去噪(Denoise),代表性paper:Image Denoise Via Sparse and Redundant Representations Over Learned Dictionaries(Elad M. and Aharon M. IEEE Trans. on Image Processing,Dec,2006);Image Sequence Denoising Via Sparse and Redundant Representations(Protter M. and Elad M.IEEE Trans. on Image Processing,Jan,2009), 还有超分辨率(Super-Resolution OR Scale-Up),代表性paper:Image Super-Resolution via Sparse Representation(Jianchao Yang, John Wright, Thomas Huang, and Yi Ma,IEEE Transactions on Image Processing, Nov,2010),A Shrinkage Learning Approach for Single Image Super-Resolution with Overcomplete Representations( A. Adler, Y. Hel-Or, and M. Elad,ECCV,Sep,2010)…. 另外还有inpait,deblur,Face Recognition,compression等等..更多应用参考Elad M的书,google能找到电子档,这里不提
供下载地址

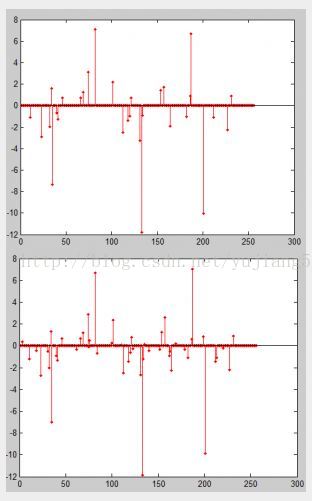
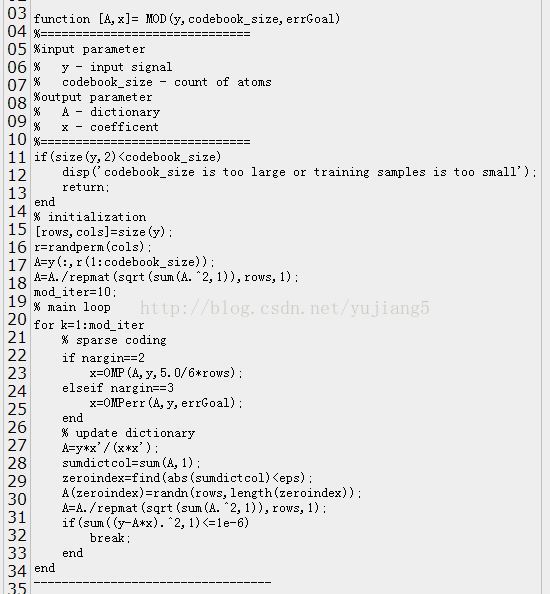
我们再回到我们一开始提到的问题上来,一开始说字典D已知,求出y在过完备字典D上的稀疏表示x,这个在稀疏表示里面被称作为Sparse Coding…问题的模型是 x=argmin norm(y-D*x,2)^2 s.t.norm(x,1)<=k; 我们下面来介绍一下解决这个问题的常用方法OMP(Orthogonal Matching Pursuit) .我们主要目标是找出x中最主要的K个分量(即x满足K稀疏),不妨从第1个系数找起,假设x中仅有一个非零元x(m),那么 y0=D(:,m)*x(m)即是在只有一个主元的情况下最接近y的情况,norm(y-y0,2)/norm(y,2)<=sigma,换句话说 在只有一个非零元的情况下,D的第m列与y最“匹配”,要确定m的值,只要从D的所有列与y的内积中找到最大值所对应的D的列数即可,然后通过最小二乘法 即可确定此时的稀疏系数。考虑非零元大于1的情况,其实是类似的,只要将余量r=y-y0与D的所有列做内积,找到最大值所对应D的列即可。…下面是代码 和示例结果[其中图1是lena图像某个8x8的图像块在其自身训练得到的字典上的稀疏表示,稀疏值k=30,相对误差norm(y- y0,2)/norm(y,2)=1.8724,图2是相同的块在相同的字典下的稀疏表述,稀疏值k=50,相对误差为0.0051]
function A=OMP(D,X,L) % 输入参数: % D - 过完备字典,注意:必须字典的各列必须经过了规范化 % X - 信号 %L - 系数中非零元个数的最大值(可选,默认为D的列数,速度可能慢) % 输出参数: % A - 稀疏系数 if nargin==2 L=size(D,2); end P=size(X,2); K=size(D,2); for k=1:1:P, a=[]; x=X(:,k); residual=x; indx=zeros(L,1); for j=1:1:L, proj=D'*residual; [maxVal,pos]=max(abs(proj)); pos=pos(1); indx(j)=pos; a=pinv(D(:,indx(1:j)))*x; residual=x-D(:,indx(1:j))*a; if sum(residual.^2) < 1e-6 break; end end; temp=zeros(K,1); temp(indx(1:j))=a; A(:,k)=sparse(temp); end; return;



















 2571
2571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









