







HMM模型是个经典模型,处理的是序列的判决问题。本文大体讲解一下HMM的过程,而对其原理不作深入探究。
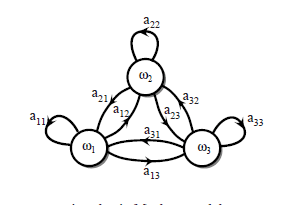
一阶马尔科夫模型
判断一个状态
vi
到另一个状态
vj
的转变。
比如今天的天气状态是“晴天”,那明天的天气状态是?,我们推测极大的可能也是“晴天”。这就是一个简单的一阶马尔科夫模型的应用。
一阶马尔科夫假设:每个状态只依赖于前一个状态。(不是依赖于其前几个状态)
前后关系用时间
t
和
表示在当前时刻
t
时,状态
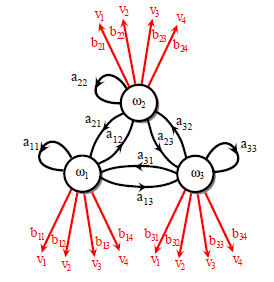
一阶隐马尔科夫模型
含有隐藏状态
s(t)
,目标仍然是判断可视状态
v(t)
的转变。
我们若是只能观测到某一状态,但是可观测状态是由隐含的某一状态决定的,那么就需要隐马尔科夫模型出马了。
独立性假设:可视状态只取决于当前隐藏状态。
P(vk(t)|sj(t))=bjk
齐次马尔科夫假设:每个状态只依赖于前一个状态。
P(vj(t+1)|vi(t))=aij
归一化约束:
∑jaij=1
和
∑kbkj=1
下面解决三个关键问题:
估值:计算可视序列 VT=v1,v2,v3,...,vn 出现的概率。根据转移概率 aij 和 bjk 。
解码:根据可视序列 VT=v1,v2,v3,...,vn 及转移概率 aij 和 bjk ,计算最可能出现的隐状态序列 ST=s1,s2,s3,...,sn 。
学习:由一组样本序列确定状态转移概率 aij 和 bjk 及隐状态的先验概率 πi 。
HMM估值
已知HMM模型(
aij
和
bjk
),如何求解产生可视序列
VT
的概率。
可视序列的产生概率如下:
P(VT)=∑rmaxr=1P(VT|STr)P(STr)
其中
rmax
为
c
个隐状态时的可能隐序列种数。
因为隐序列的当前状态仅仅取决于前一状态,故:
因为当前可视状态仅仅由当前隐状态决定,故:
P(VT|ST)=P(v1|ST)P(v2|ST)∗...∗P(vT|ST)
可视状态间互不影响。
P(VT|ST)=P(v1|s1)P(v2|s2)∗...∗P(vT|sT)=∏Tt=1P(vt|st)
综上所述:
P(VT)=∑rmaxr=1∏Tt=1P(vt|st)∏Tt=1P(st|st−1)
P(VT)=∑rmaxr=1∏Tt=1P(vt|st)P(st|st−1)
上面这个式子计算起来实在太过复杂~现在介绍一种简单计算方法,递归地计算
P(VT)
,累积前面的,计算当次的,再累积前面的,计算当次的,直到整个序列都计算完毕。
设
αi(t)
表示HMM在
t
时刻,位于隐状态
HMM前向估计的递归方法示意图(这里的
w
是上面的
HMM前向算法过程
1. Initialize t=0,aij,bjk ,可见序列 VT , αj(0)=1
2. for t=t+1
3.
4. until t=T
5. returnP(VT)
HMM后向算法过程
1. Initialize t=T,aij,bjk ,可见序列 VT , βj(T)
2. for t=t−1
3.
4. until t=1
5. returnP(VT)
其中,定义 βi(t) 为在 t 时刻位于状态
HMM解码
已知一个观测序列
VT
,解码就是找到与其对应的最可能的隐状态序列
ST
。
一种简单的方法是遍历所有的可能的隐状态序列的概率,选择最大的作为解码结果。但是这很明显不现实,因为计算量实在过于巨大。
现提供一种简单思路,把每个时刻最可能的隐状态
s(t)
找到。
HMM解码算法(Viterbi)
1.
Initialize
paht为空
,
t=0
2.
for
t=t+1
3.
j=1
4.
for
j=j+1
5.
αj(t)=bjkv(t)∑ci=1αi(t−1)aij
6.
until
j=c
7.
j′=argmaxjαj(t)
8. 将隐状态
sj′
添加到
path
中
9.
until
t=T
10.
return
path
这种解码方法(维特比算法)的缺点是:不能够保证找到的路径就是合法的路径,即找到的路径有可能是不连贯的。因为是用局部最优解串联成的解。
HMM学习
学习模型的过程就是确定模型的参数,转移概率
aij,bjk
及隐状态的先验概率
πi
。
(1)对于有监督问题
a^ij=隐状态si转到sj的频次隐状态si的所有隐状态转移频次
b^ij=隐状态sj转到可视状态vk的频次隐状态sj的所有可视状态转移频次
π^i=样本中
t=1
时,可视状态对应的隐藏状态为si的频率
(2)对于无监督问题
解决无监督的HMM训练问题,就是大名鼎鼎的Baum-Welch算法,也叫前向-后向算法。
该算法是“广义期望最大化算法”的一种具体实现,其核心思想是:通过递归方式更新权重,以得到能够更好地描述(解释)训练样本的模型参数。
定义从隐状态
si(t−1)
到
sj(t)
的概率
γij(t)
如下:
其中, P(VT|θ) 是模型用任意的隐含路径产生序列 VT 的概率, γij(t) 则表示了在产生可序列 VT 的条件下,从隐状态 si(t−1) 到 sj(t) 的概率。
aij 的估计值 aij^ 如下, K 表示可转移的状态数量:
上式中,分子表示了 si 到 sj 的期望;分母表示了 si 转移的总期望。
bjk 的估计值 bjk^ 如下:
上式中,分子表示了隐状态 sj 对应的特定的可视状态 vk 对应的频次;分母表示了隐状态 sj 对应的所有的可视状态的频次。
?初始状态概率怎么确定的?
前向-后向算法过程
1. Initial aij,bjk 训练序列 VT ,收敛判据 θ , z=0
2. doz=z+1
3. 由a(z−1)和b(z−1)计算a^(z)
4. 由a(z−1)和b(z−1)计算b^(z)
5. update:
6. aij(z)=a^ij(z−1)
7. bjk(z)=b^jk(z−1)
8. until maxi,j,k[aij(z)−aij(z−1),bjk(z)−bjk(z−1)]<θ
9. return aij=aij(z);
bjk=bjk(z)
πi=当前参数下,初始隐状态s1=si的概率当前参数下,VT的概率=P(VT,s1=si|a,b)P(VT|a,b)
πi 是隐状态的先验概率估计,需要根据样本推测隐状态样本,然后计算。
小结
HMM算法是个经典算法,在语音识别、自然语言处理、生物信息等领域应用广泛。隐马尔科夫模型是关于时序的概率模型,描述一个由隐藏的马尔科夫链随机生成不可观测的状态的序列,再由各个状态随机生成一个观测值而产生观测序列的过程。















 22万+
22万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









