







三个节点的hadoop集群配置
这次我搭建的是一个三节点的hadoop集群,具体的集群部署规划如下:
| hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
虚拟机准备
我使用的是centos6.8版本的linux,三台虚拟机都是从一台干净的虚拟机中克隆而来,在克隆后,需要对这三台虚拟机进行ip地址,主机名称的修改,以下以其中一台虚拟机的配置为例。具体步骤如下:
- 修改网卡,复制物理地址
vim /etc/udev/rules.d/70-persistent-net.rules

将eth0的删除,原来的eth1修改为eth0,并将它的物理地址复制
操作结果为:

- 修改ip地址
vim /etc/sysconfig/network-scripts/ifcfg-eth0
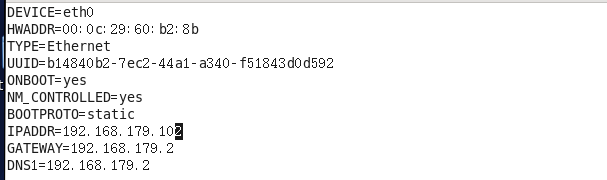
将之前复制的mac地址粘贴到HWADDR中,将IPADDR修改为设置的ip地址。
ONBOOT表示开机自动得到你配置的ip地址
BOOTPROTO表示本机的ip地址是静态获取的,不是动态dhcp获取
- 修改主机名称
vim /etc/sysconfig/network
将HOSTNAME修改为你想要的修改成的主机名

- 添加新的用户,并赋予它root权限
useradd zy
passwd zy
vim /etc/sudoers

- 对另外两台虚拟机都做同样操作,只不过主机名和ip地址不同,都做完后。reboot重启虚拟机
- 每个虚拟机都配置主机名与ip地址的映射关系
sudo vim /etc/hosts
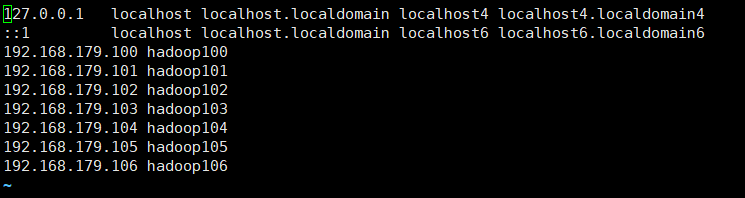
- 对集群中的每个主机都ping,对外网也ping,看集群间的网络是否联通
安装JDK和HADOOP,配置环境变量
- 通过xftp将jdk8和hadoop的tar包传输到/opt/software/目录下

- 解压tar包
tar -zxvf jdk-8u144-linux-x64.tar.gz -C ../module/
tar -zxvf hadoop-2.7.2.tar.gz -C ../module/
- 配置环境变量
vim /etc/profile

source /etc/profile
查看环境变量设置是否成功
java -version

hadoop version

- 通过scp方式将hadoop102上的/etc/profile传输到hadoop103和hadoop104
scp -r /etc/profile root@hadoop103:/etc/profile
scp -r /etc/profile root@hadoop104:/etc/profile
记得hadoop103和hadoop104要source环境变量
编写集群分发脚本
mkdir bin
cd bin/
touch xsync
vim xsync
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if ((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=103; host<105; host++)); do
echo ------------------- hadoop$host --------------
rsync -av $pdir/$fname $user@hadoop$host:$pdir
done
chmod 777 xsync
编写查看集群jps信息脚本
同样在hadoop102的/home/bin/下创建myjps
cd /home/zy/bin
touch myjps
vim myjps
#!/bin/bash
for i in hadoop102 hadoop103 hadoop104
do
ssh $i /opt/module/jdk8/bin/jps
done
chmod 777 myjps
SSH无密登录设置
以下以hadoop102为例:
- 生成公钥和私钥
ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
- 将公钥拷贝到要免密登录的目标机器上
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104
其他hadoop103,hadoop104都按照相同方法操作
集群配置
- 首先配置3个.env文件的java_home(hadoop-env.sh,yarn-env.sh,mapred-env.sh)
vim hadoop-env.sh

vim yarn-env.sh

vim mapred-env.sh

- 配置4个-site.xml文件
在core-site.xml配置namenode所在的节点和hadoop运行时产生文件的存储目录
vim core-site.xml

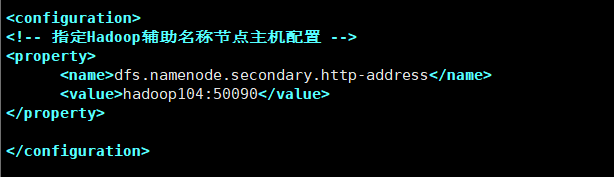
在hdfs-site.xml中配置2nn所在的节点
vim hdfs-site.xml
在yarn-site.xml中配置resourcemanager所在的节点,Reducer获取数据的方式,日志聚集
vim yarn-site.xml

在mapred-site.xml中添加历史服务器,制定mapreduce运行在yarn上
mv mapred-site.xml.template mapred-site.xml.
vim mapred-site.xml

- 配置slaves
vim slaves

- 将配置文件分发到集群中的所有机器
xsync hadoop/

5.格式化namenode
如果集群是第一次启动,需要格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
bin/hdfs namenode -format

群起集群
1.群起hdfs
start-dfs.sh
2.群起yarn
start-yarn.sh
3.通过myjps查看集群中的各个节点的jps情况

4.在web端查看namenode情况
http://hadoop102:50070/

5.在web端查看yarn的情况
http://hadoop103:8088/

结语
通过上面的步骤,一个简单的hadoop集群就搭建完成了。















 1616
1616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









