






 本文详细介绍了Hadoop在大数据时代的应用,包括其作为分布式存储和计算框架的基础架构,以及如何进行Hadoop集群的安装、配置步骤,如静态IP设置、远程连接、防火墙管理、主机名设置和JAVA安装等。
本文详细介绍了Hadoop在大数据时代的应用,包括其作为分布式存储和计算框架的基础架构,以及如何进行Hadoop集群的安装、配置步骤,如静态IP设置、远程连接、防火墙管理、主机名设置和JAVA安装等。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
一、Hadoop是什么?
二、Hadoop集群的搭建和配置
1、安装方式
2、设置静态IP
3、远程连接虚拟机
4、防火墙
5、设置主机名
6、设置主机名与IP的映射
7、安装JAVA
8、安装Hadoop
大数据时代下,针对大数据处理的新技术也在不断地开发和运用中,并逐渐成为数据处理挖掘行业广泛使用的主流技术之一。在大数据时代,Hadoop作为处理大数据的分布式存储和计算框架,在国内外大、中、小型企业中已得到了广泛应用。学习Hadoop技术是从事大数据行业工作必不可少的一步。
提示:下面案例可供参考
一、Hadoop是什么?
分布式系统基础架构
Hadoop是一个由Apache基金会开发的分布式系统基础架构,主要解决海量数据的存储和计算问题。具体来说:
狭义上,Hadoop是一个框架平台。它包含三大组件:HDFS(分布式文件系统),用于提供高吞吐量的数据访问能力并存储在低廉的硬件设备上;MapReduce(分布式计算框架)为海量的数据提供了计算能力;YARN(集群资源管理和任务调度)。这些组件共同协作使得用户可以在不了解分布式底层细节的情况下开发分布式程序,充分利用集群的威力进行高速运算和存储。
广义上讲,Hadoop代表大数据的一个技术生态圈,包括很多与数据采集、导入、分析、挖掘以及可视化等相关的软件框架。
二、Hadoop集群的搭建和配置
1.安装方式
1.1 独立(本地)运行模式
(1)将Hadoop安装包直接解压到某个路径即可
(2)无需运行,故不会有Hadoop相关进程在实时运行
(3)用在开发、测试场景
1.2 伪分布式运行模式
(1)在一个节点/机器上部署Hadoop
(2)需要将Hadoop相关进程都运行起来
(3)一般用在学习、开发、测试等场景
1.3 完全分布式模式
(1)在多个节点部署Hadoop,一般至少3个节点
(2)生产环境、测试环境
(3)部署难度相对较高
2.设置静态IP
(1)切换超级用户,命令:su

(2)固定IP
- 查看并修改配置文件,命令:vi /etc/sysconfig/network-scripts/ifcfg-ens33
- 点击键盘i键,更改当前编辑模式,切换为输入模式insert
- 修改文件,如下
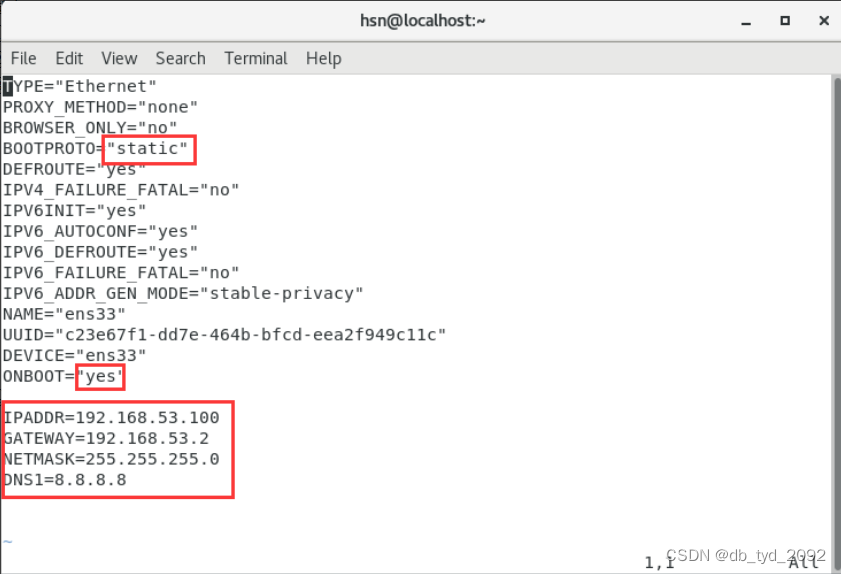
(3)保存文件(注意,鼠标要确定点进了虚拟机里再操作): - 点击键盘ESC键,切换模式
- 输入:wq,保存并退出
- 点击键盘↑键,调出上一次命令,检查是否已经修改
- 查看如下,表示我们已经修改成功了
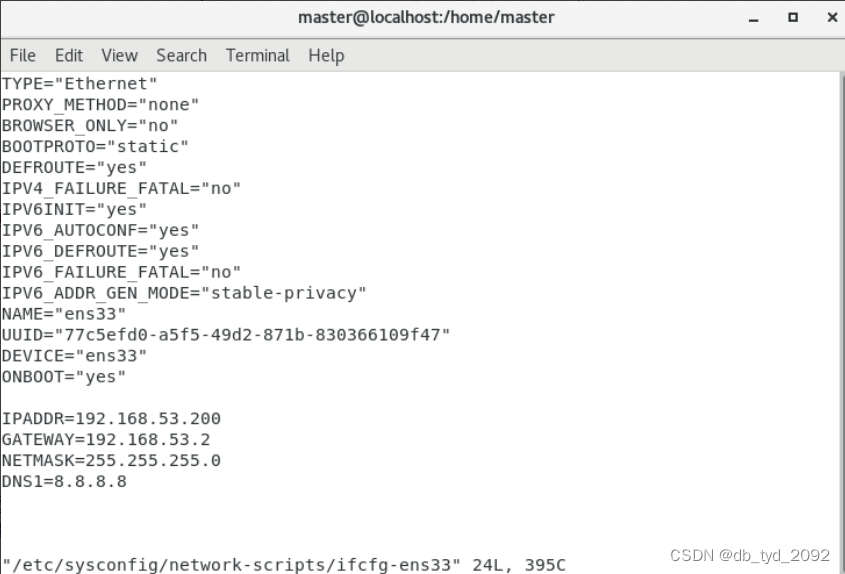
- 输入:q退出当前文档
(4)重启网卡服务:service network restart

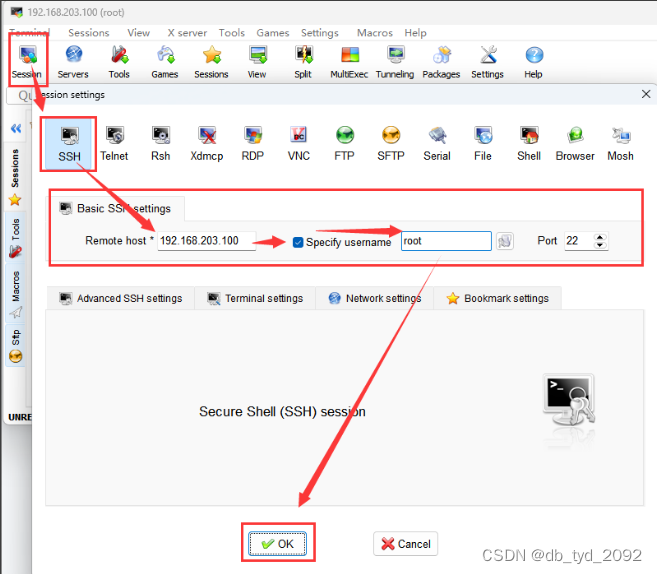
3.远程链接虚拟机
注意,IP是前面设定的,如我设定的是192.168.203.100,帐号写root,端口号22,那么填入信息如下:
4.防火墙
防火墙实质是一个程序,它可以控制系统进来或者出去的流量。Centos7默认情况下,防火墙是开机自启的。在集群部署模式下,各个节点之间的进程要通信,为了方便,一般都要关闭防火墙。
(1)查看防火墙状态,命令:systemctl status firewalld
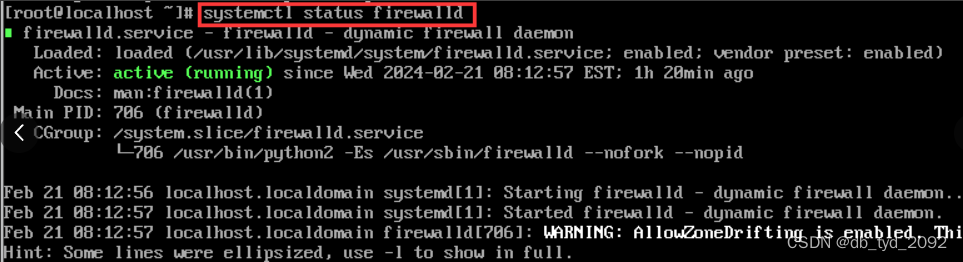
当前active(running)表示防火墙在启动状态
(2)关闭防火墙,命令:systemctl stop firewalld
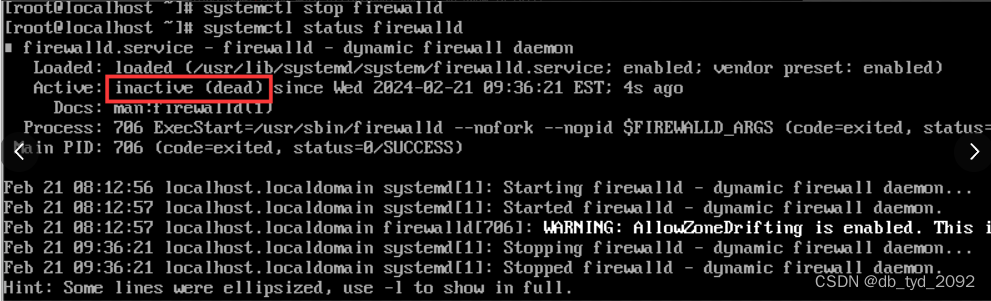
当前inactive(dead)表示已经关闭防火墙了
(3)查看防火墙是否开机自启,命令:systemctl is-enabled firewalld

(4)禁止防火墙开机自启,命令:systemctl disable firewalld
5.设置主机名
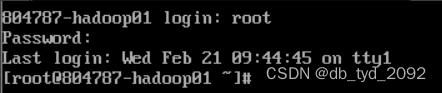
简单理解,给机器起一个名字。一般在集群当中,都是通过配置主机名来和其他节点通信,所以需要改下机器的名字。命令:hostnamectl set-hostname 804787-hadoop01(课本是master,大家可以都设置成master。原本的是localhost,指的是本地主机的意思)

使用logout命令登出,再重新登录,用户名已经改变,由上次改成的aaa,变成了刚刚改成的804787-hadoop01
6.设置主机名和IP的映射
在网络中,可以通过IP通信,因此,在集群中,如果想要通过主机名通信,则还要设置IP来与之对应,类似于域名要绑定IP。
使用vi命令编辑/etc/hosts文件(一般ip+主机就行,不需要第三段,如192.168.203.200 master),设置如下图所示:


7.安装JAVA
(1)使用命令,java -version,检查原本系统自带jdk

(2)卸载自带jdk,命令:rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps。
解析:
- rpm -qa:查询所安装的所有rpm软件包
- grep -i:忽略大小写(JAVA,java,Java)
- xargs -n1:每次只传递一个参数
- rpm -e -nodeps:强制卸载软件
(3)拖拽方式,上传安装包到Linux的/opt目录下:
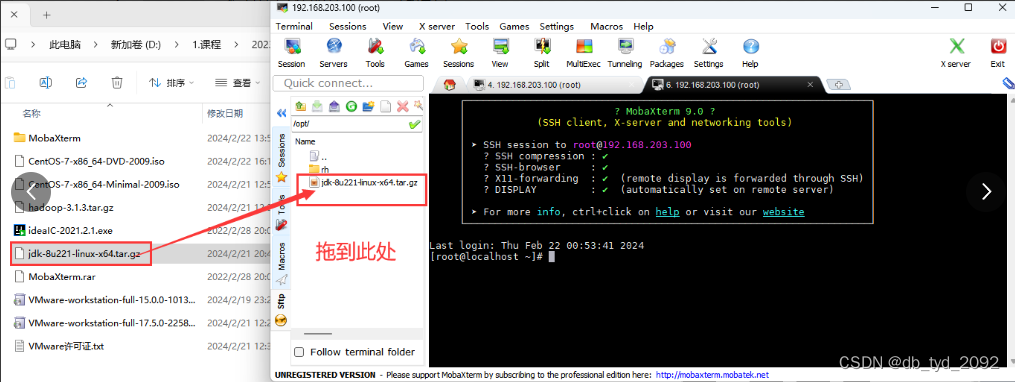
(4)使用cd命令进入/opt并解压文件到/opt下,命令:tar -xzvf jdk-8u221-linux-x64.tar.gz -C /opt
解析: - tar:主命令,用于文件归档和压缩的工具。
- -xzvf:tar命令的选项
- x: 指解压操作(extract)
- z: 指解压.gz文件等
- v: 指详细模式(verbose),在解压过程中,会显示正在处理的文件名
- f: 指文件名(file),tar命令后面会跟随要处理的文件名
- jdk-8u221-linux-x64.tar.gz: 要解压的文件的名称
- -C: 指更改目录(change directory),在解压前首先切换到指定的目录。
- /opt: 要切换到的目录
(5)使用cd命令进入到jdk解压后文件夹,用pwd查看路径,并使用鼠标复制路径/opt/jdk1.8.0_221

(6)在/etc/profile.d下创建一个my_env.sh,进行配置JAVA环境变量,命令:vi /etc/profile.d/my_env.sh(新文件)

(7)重新启动profile,命令:source /etc/profile
(8)验证java是否安装成功:java -version

8.安装Hadoop
(1)上传文件
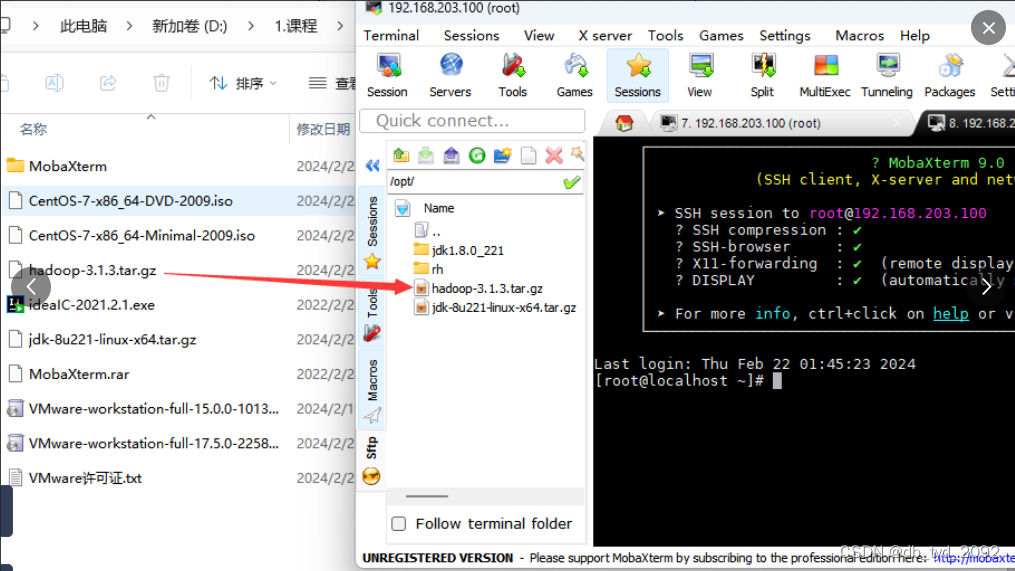
(2)使用cd命令进入文件所在路径,再解压安装,命令:tar -xzvf hadoop-3.1.3.tar.gz -C /usr/local
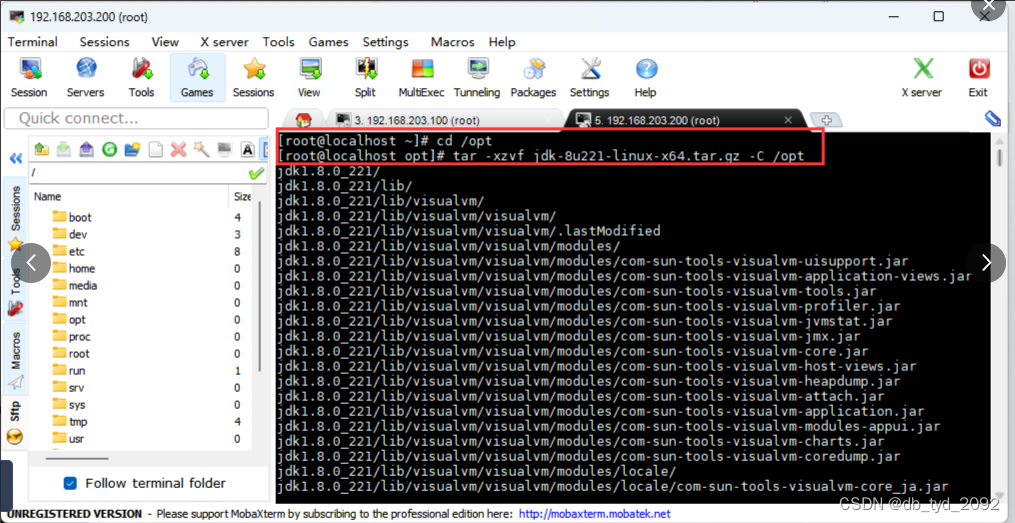
(3)配置环境变量,同JAVA,在/etc/profile.d修改my_env.sh
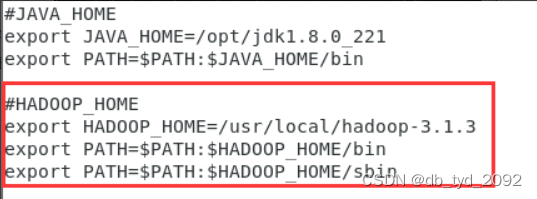
(4)使用cd命令,进入/usr/local/hadoop-3.1.3/etc/hadoop,配置vi hadoop-env.sh,在末尾加上2句
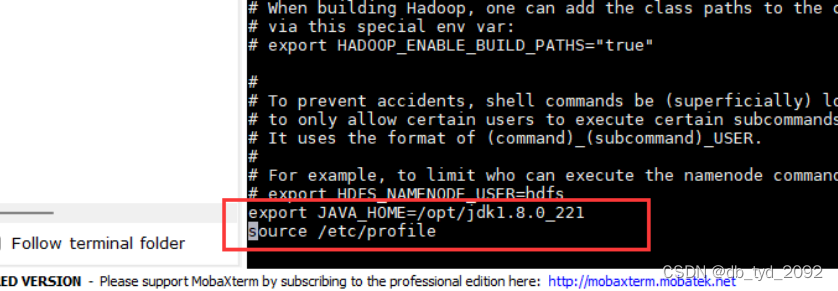
(5)重启profile,命令:source /etc/profile
(6)使用命令hadoop version检查是否安装成功

总结
以上就是今天要讲的内容,本文仅仅简单介绍了Hadoop集群的搭建与配置

















 496
496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









