




文章目录
前言
随着python的发展网页的反爬机制也不断完善,下面我们来学习以下反爬机制的防盗链
现在有很多网站都在用防盗链的技术。
例如:梨视频
一、防盗链是什么?
一种反爬机制
二、 防盗链如何实现
首先我们进入一个带视频的网站
我通过我们的开发者工具进行正常抓包
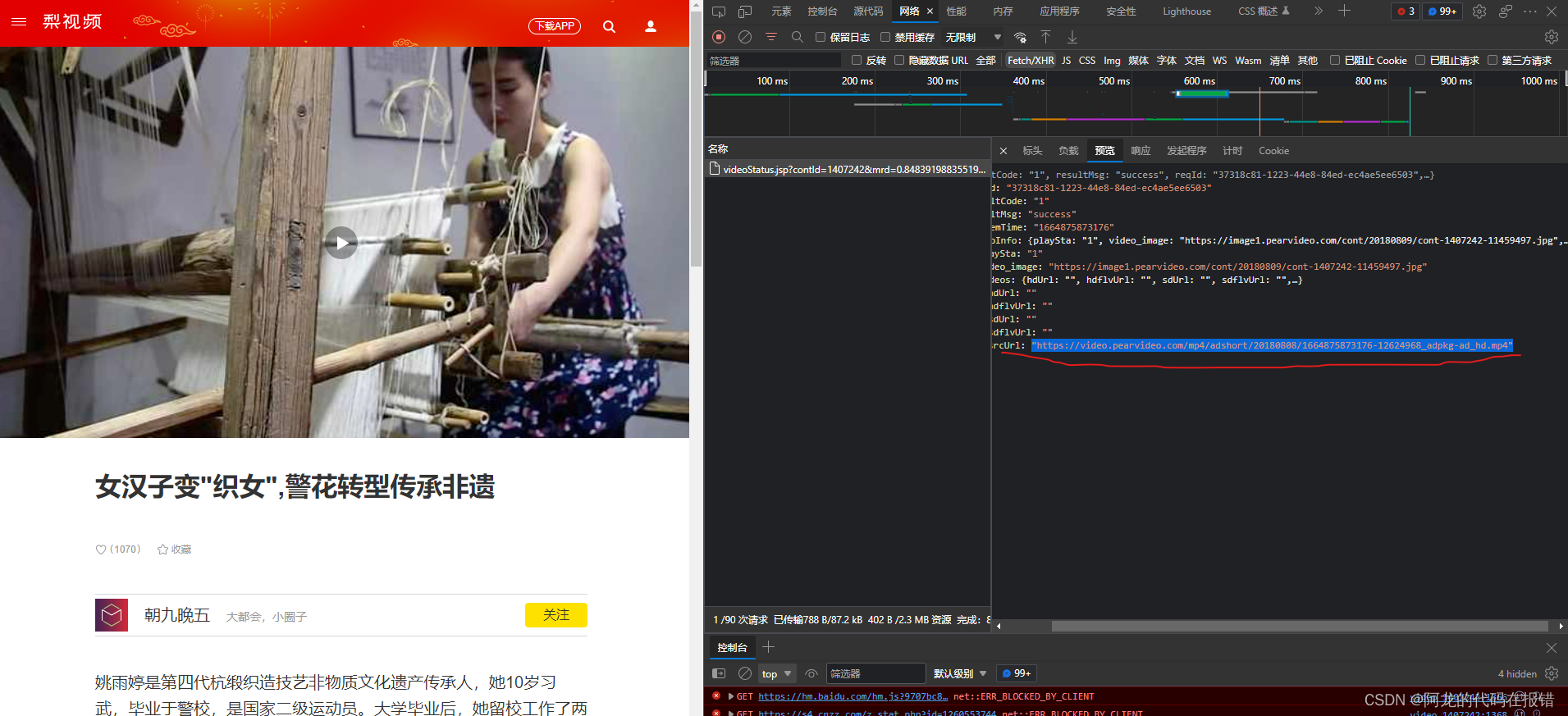
红线上面的应该为视频的下载地址:
https://video.pearvideo.com/mp4/adshort/20180808/1664876348330-12624968_adpkg-ad_hd.mp4
但是我们在打开这个链接是会出现以下的状况:

我们通过元素定位发现https://video.pearvideo.com/mp4/adshort/20180808/cont-1407242-12624968_adpkg-ad_hd.mp4这个链接可以播放原视频
我们可以对比两个链接的区别:
https://video.pearvideo.com/mp4/adshort/20180808/1664876348330-12624968_adpkg-ad_hd.mp4
https://video.pearvideo.com/mp4/adshort/20180808/cont-1407242-12624968_adpkg-ad_hd.mp4

红线的地方是两个链接的区别
这就是一个小小的防盗链
三、分析
既然知道了两个网站的区别我们利用我们的爬虫代码将他们两个修改成一样的不就可以了吗
四、 对有防盗链的网站进行爬取
- 对有视频连接的网站发出请求并且获取源码信息
- 提取出我们的视频网站
- 对我们提取的网址进行修改
4.下载视频
对有视频连接的网站发出请求并且获取源码信息
import requests
url = "https://www.pearvideo.com/video_1407242"
# 对网页进行分割获取有用的数据
data_ID = url.split("_")[1]
# 编写代有视频链接的url
url_ship = "https://www.pearvideo.com/videoStatus.jsp?contId=1407242&mrd=0.9916564465973412"
# 编写请求头
heead = {
"User-Agent": 'Mozilla / 5.0(WindowsNT10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / '
'104.0.5112.102Safari / 537.36Edg / 104.0.1293.63 ',
"Referer": url
}
# 发出请求
reqs = requests.get(url=url_ship,headers=heead)
# 获取数据
reqs_text = reqs.json()
提取出我们的视频网站
# 拿到网页中报错的404的视频网址
srcurl = reqs_text["videoInfo"]["videos"]['srcUrl']
对我们提取的网址进行修改,和拼凑
# 获取到systemTime的数据用于拼凑视频的下载连接
systime = reqs_text['systemTime']
# 拼凑出视频下载的有效连接
srcurl_1 = srcurl.replace(systime,f'cont-{data_ID}')
下载视频
# 对视频链接发出请求
reqs_sp = requests.get(srcurl_1)
with open("警花.mp4","wb") as fp:
fp.write(reqs_sp.content)
print('视频下载完成')
结束爬取
print("爬取结束")
# 关闭网络请求
reqs.close()
完整代码
import requests
url = "https://www.pearvideo.com/video_1407242"
# 对网页进行分割获取有用的数据
data_ID = url.split("_")[1]
# 编写代有视频链接的url
url_ship = "https://www.pearvideo.com/videoStatus.jsp?contId=1407242&mrd=0.9916564465973412"
# 编写请求头
heead = {
"User-Agent": 'Mozilla / 5.0(WindowsNT10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / '
'104.0.5112.102Safari / 537.36Edg / 104.0.1293.63 ',
"Referer": url
}
# 发出请求
reqs = requests.get(url=url_ship,headers=heead)
# 获取数据
reqs_text = reqs.json()
# 拿到网页中报错的404的视频网址
srcurl = reqs_text["videoInfo"]["videos"]['srcUrl']
# 获取到systemTime的数据用于拼凑视频的下载连接
systime = reqs_text['systemTime']
# 拼凑出视频下载的有效连接
srcurl_1 = srcurl.replace(systime,f'cont-{data_ID}')
# 下载视频
## 对视频链接发出请求
reqs_sp = requests.get(srcurl_1)
with open("警花.mp4","wb") as fp:
fp.write(reqs_sp.content)
print('视频下载完成')
print("爬取结束")
# 关闭网络请求
reqs.close()
代码由pycharm实现,希望对你有用



















 190
190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











