







前言
在我们对网页进行多任务爬取时,会产生很长的时间等到,为了快速的完成任务,我们要合理的利用我们的cpu资源
爬取数据的代码
我们搞一下我们北京新发地的菜价:北京新发地
然后具体的爬取过程我就不在概述了
下面这部分代码是我们对北京新发地菜价的爬取代码
正常爬取的话需要很长的一段时间
import requests
import csv
import time
from tqdm import tqdm
header = ['id','prodName','大白菜', 'prodCatid', 'prodCat', 'prodPcatid', 'prodPcat', 'lowPrice', 'highPrice', 'avgPrice','0.85', 'place','冀', 'specInfo', 'unitInfo', '斤', 'pubDate', 'status', 'userIdCreate', 'userIdModified','userCreate','userModified','gmtCreate','gmtModified']
f = open('北京新发地(最终).csv', 'a', newline='',encoding='utf-8')
writer = csv.DictWriter(f, fieldnames=header)
writer.writeheader()
count = 0
url = "http://www.xinfadi.com.cn/getPriceData.html"
def one_page(url,data):
global count
resp = requests.post(url,data)
dic = resp.json()
dic_list = dic["list"]
# print(dic_list)
for i2 in dic_list:
writer.writerow(i2)
resp.close()
if __name__ =="__main__":
for i1 in range(1, 200):
data = {
"limit": "20",
"current": {i1}
}
one_page(url=url,data=data)
利用多进程的方式进行运行
我们将代码修改为以下:
import requests
import csv
from tqdm import tqdm
import time
from concurrent.futures import ThreadPoolExecutor
t0=time.time()
print('显示程序开始的时间:',time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
header = ['id','prodName', 'prodCatid', 'prodCat', 'prodPcatid', 'prodPcat', 'lowPrice', 'highPrice', 'avgPrice', 'place', 'specInfo', 'unitInfo','pubDate', 'status', 'userIdCreate', 'userIdModified','userCreate','userModified','gmtCreate','gmtModified']
f = open('北京新发地(最终1).csv', 'a', newline='',encoding='utf-8')
writer = csv.DictWriter(f, fieldnames=header)
writer.writeheader()
count = 0
def one_page(url,data):
global count
resp = requests.post(url,data)
dic = resp.json()
dic_list = dic["list"]
for i2 in dic_list:
writer.writerow(i2)
resp.close()
if __name__=="__main__":
url = "http://www.xinfadi.com.cn/getPriceData.html"
# 创建线程池
with ThreadPoolExecutor(100) as jp:
# 遍历网址
for i1 in tqdm(range(1,200)):
data = {
"limit": "20",
"current": {i1}
}
# 将任务提交给线程
jp.submit(one_page,url,data)
t1 = time.time()
# 进程结束提示
print("全部下载完成")
print('显示程序结束的时间:', time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())))
print("用时:%.6fs" % (t1 - t0))
这个运行的爬虫程序会大大减少我们的运行时间,也会很好的利用电脑的资源,提高电脑的利用率
使用进程池的方法后的结果
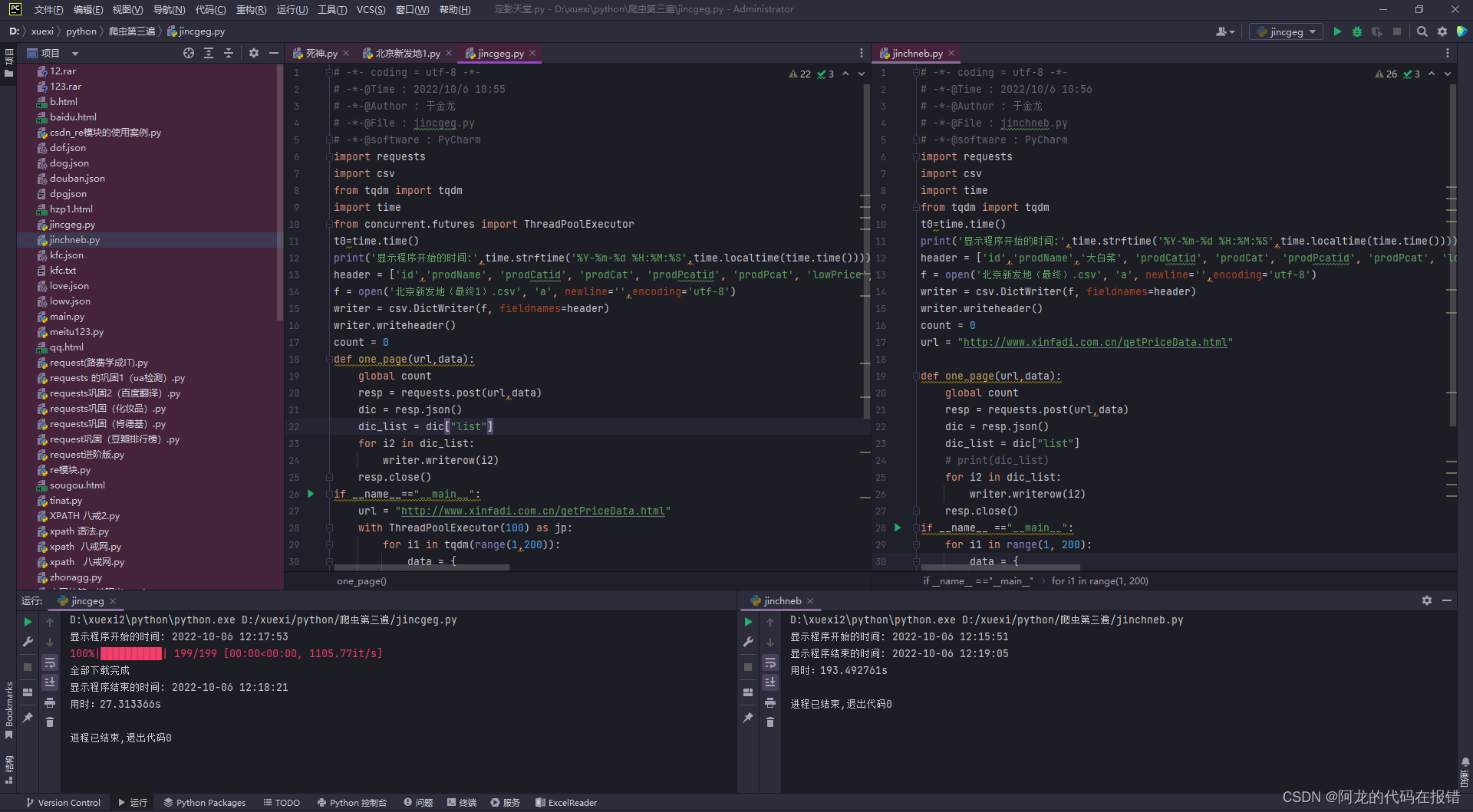
减少了时间的占用和增加了资源的运用

















 439
439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











