






本案例是抓视频网站里面的某个视频。
步骤是:
# 1.拿到contId
# 2.拿到videoStatus.jsp返回的json -> srcURL
# 3.srcURL里面的内容进行修整
# 4.下载视频本次案例是用li视频作为防盗链案例的对象。
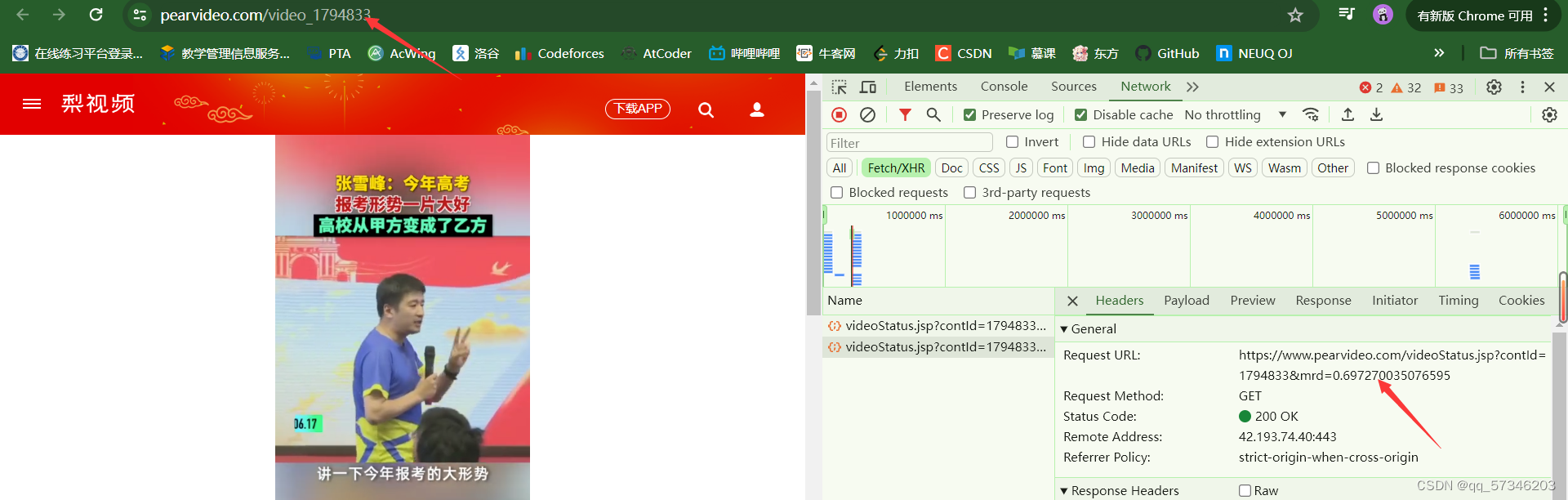
点开该视频以后会发现页面源代码与F12显示的代码并不一样。故需要在F12中选中XHR选项重新刷新一下页面,就会出现箭头所指的
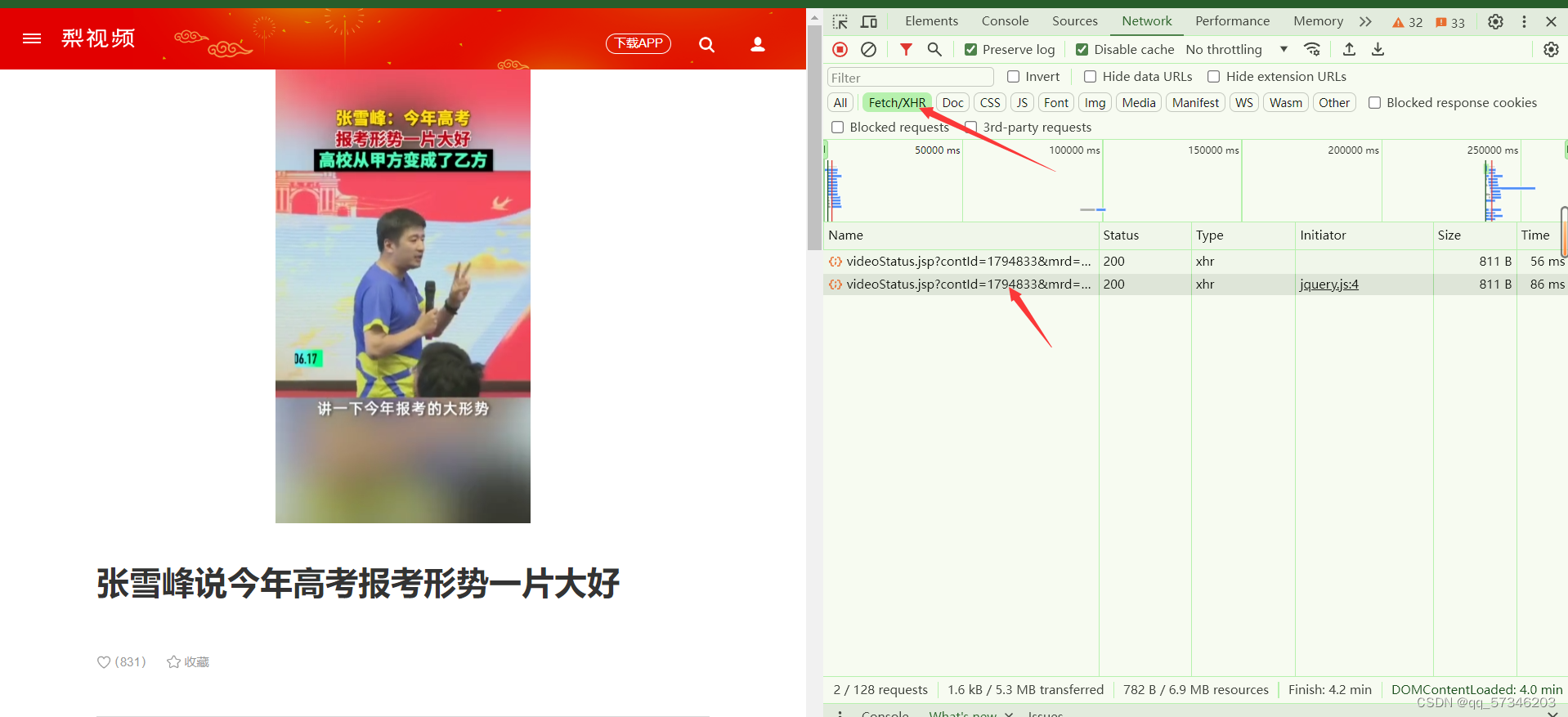
点开以后点开preview,preview中的srcUrl里面的跟视频链接很像,但是srcUrl里面的链接打开以后会是404,所以需要对比哪里不一样
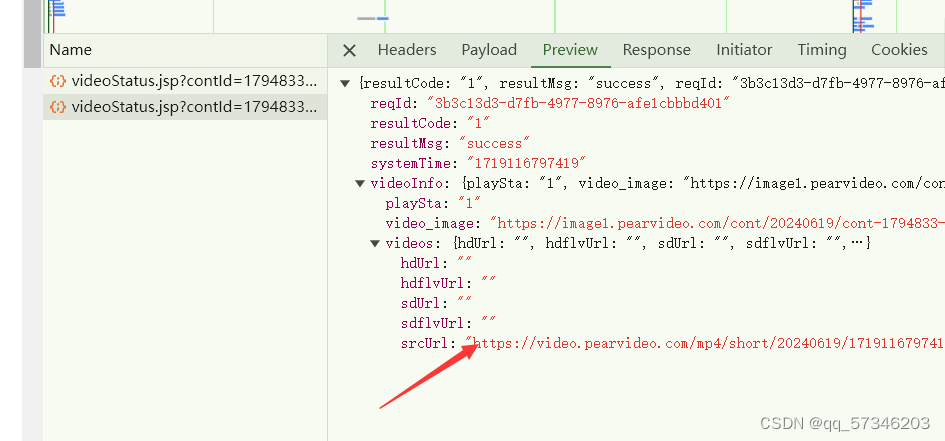
点开Headers箭头指的就是原视频链接
可以发现两个链接的url只有划线处不一样,所以只要提取到srcUrl里面的链接以后,将里面的划线处的数字换成cont-数字就好。可以发现划线处数字就是上述图片里面的systemTime,而cont-后面的数字是下图的contId,故只需提取到srcUrl里面的systemTime将其替换为contId就能获取到视频下载链接并将其下载到本地啦!
1.拿到contId

2.拿到videoStatus.jsp返回的json -> srcURL
videoStatusUrl是网页中videoStatus.jsp中headers里的url
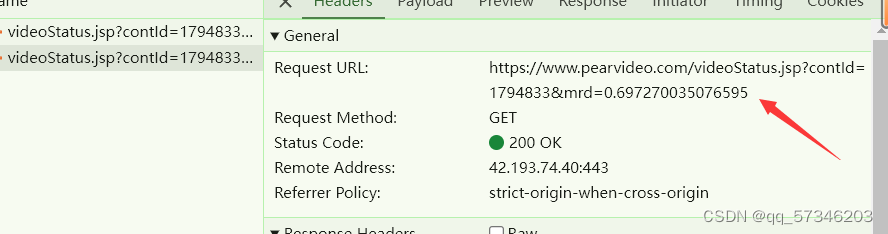
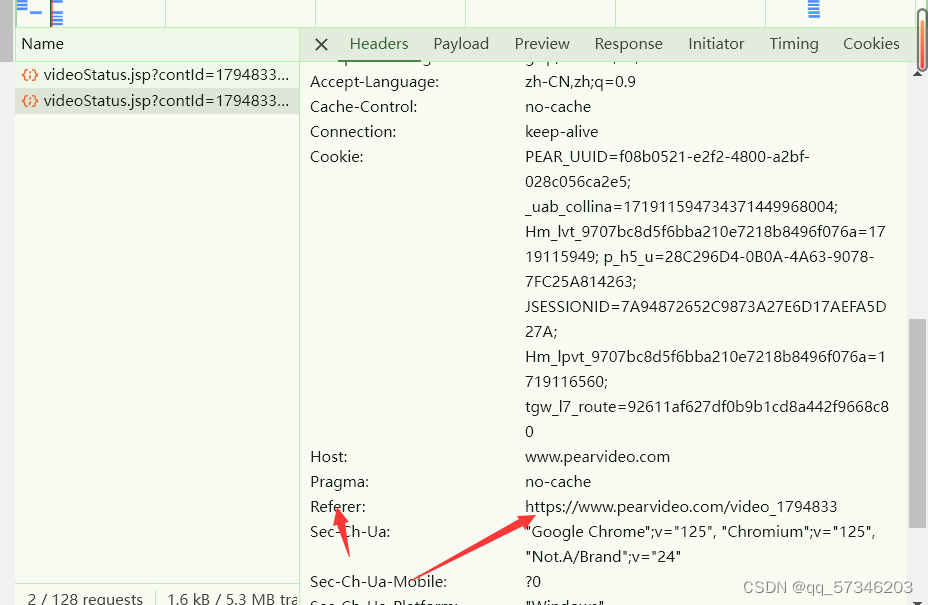
防盗链(反爬的一种方式):溯源,就是访问videoStatus.jsp中headers里的url的上一级是点击https://www.pearvideo.com/video_1794833这个链接访问的,故需要进行溯源到上一级链接。溯源是在headers里面的Referer里面找到上一级链接。
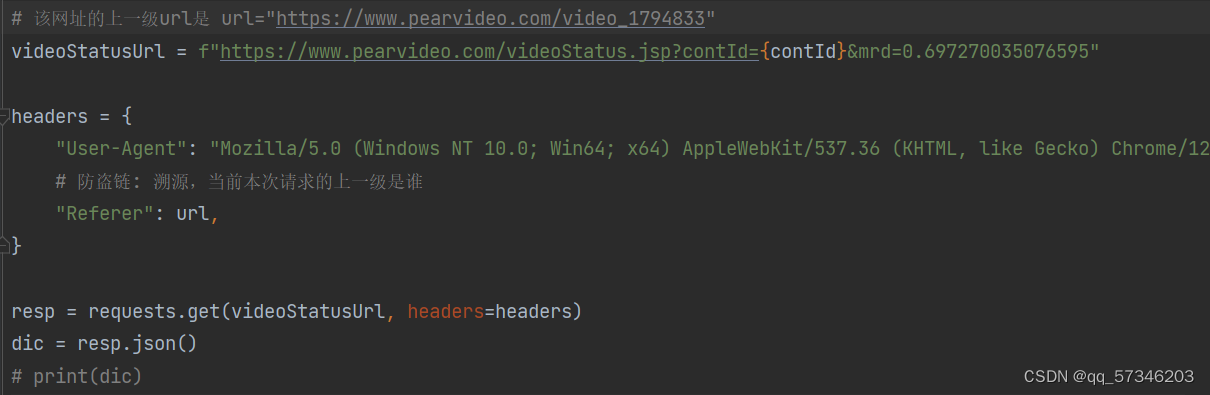
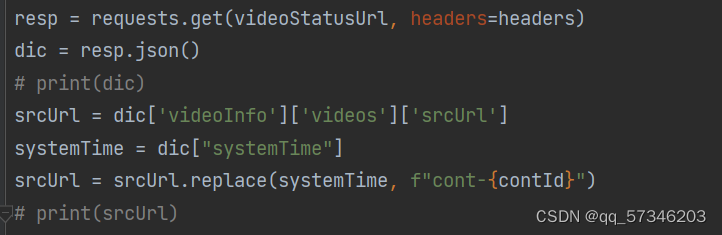
3.srcURL里面的内容进行修整,即将systemTime代表的数字换成cont-{contId}。代码里面用dic["systemTime"]等找systemTime和srcUrl是因为dic = resp.json()返回的是json形式,类似于map。
4.下载视频
三个链接之间的关系:

# 1.拿到contId
# 2.拿到videoStatus.jsp返回的json -> srcURL
# 3.srcURL里面的内容进行修整
# 4.下载视频
import requests
# 在首页点开视频以后视频的网址
url = "https://www.pearvideo.com/video_1794833"
# 从_分开,获取1794833,第0是https://www.pearvideo.com/video,第1是1794833
contId = url.split('_')[1]
# 该网址的上一级url是 url="https://www.pearvideo.com/video_1794833"
videoStatusUrl = f"https://www.pearvideo.com/videoStatus.jsp?contId={contId}&mrd=0.697270035076595"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36",
# 防盗链: 溯源,当前本次请求的上一级是谁
"Referer": url,
}
resp = requests.get(videoStatusUrl, headers=headers)
dic = resp.json()
# print(dic)
srcUrl = dic['videoInfo']['videos']['srcUrl']
systemTime = dic["systemTime"]
srcUrl = srcUrl.replace(systemTime, f"cont-{contId}")
# print(srcUrl)
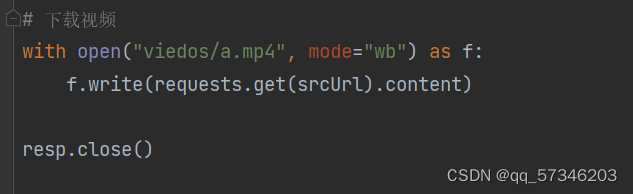
# 下载视频
with open("viedos/a.mp4", mode="wb") as f:
f.write(requests.get(srcUrl).content)
resp.close()
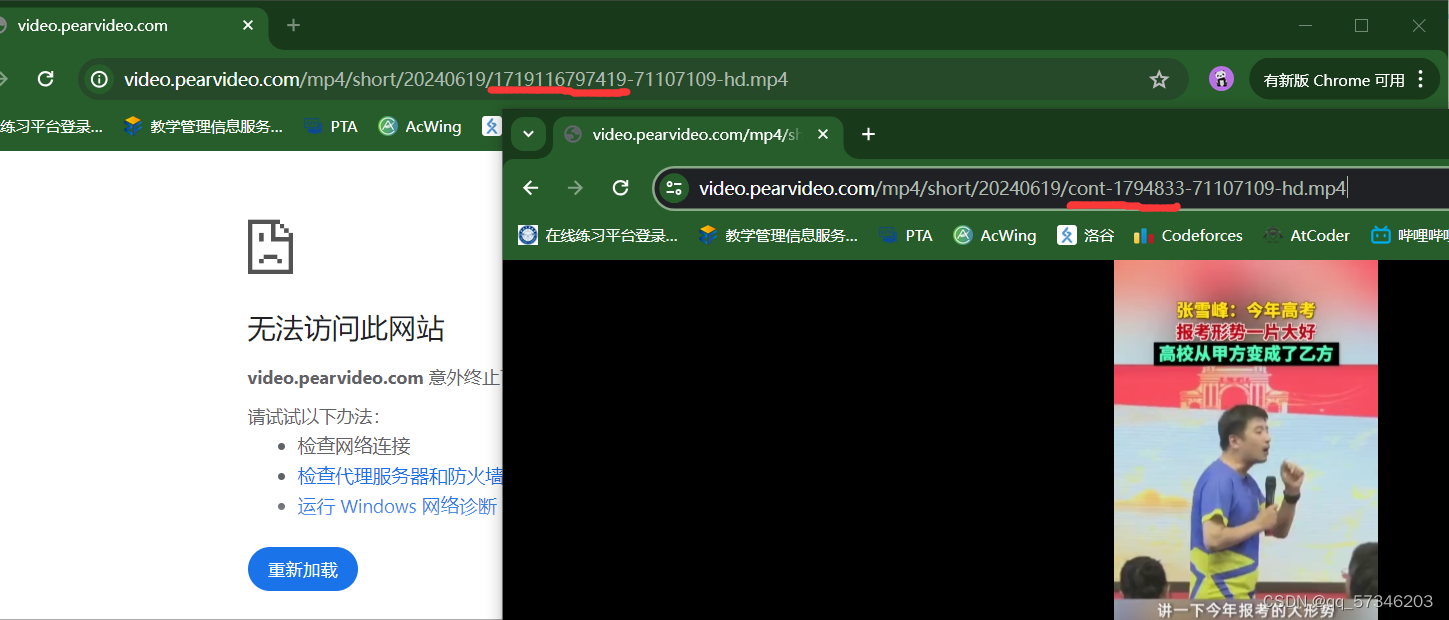
# 视频真实链接:https://video.pearvideo.com/mp4/short/20240619/cont-1794833-71107109-hd.mp4
# 拿到的链接:https://video.pearvideo.com/mp4/short/20240619/1719116797419-71107109-hd.mp4
# 将systemTime替换为cont-{contId}以后:https://video.pearvideo.com/mp4/short/20240619/cont-1794833-71107109-hd.mp4















 1888
1888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









