









项目场景:
使用pycharm工具将spark分析完的数据存储到MySQL数据库中
—
问题描述
在程序执行过程中发生以下报错:
org.apache.spark.SparkException: Python worker failed to connect back.

原因分析:
可能是我们的环境变量配置的有一些些许的错误所以导致这个错误的发生
解决方案:
这个时候首先打开我们的pycharm工具
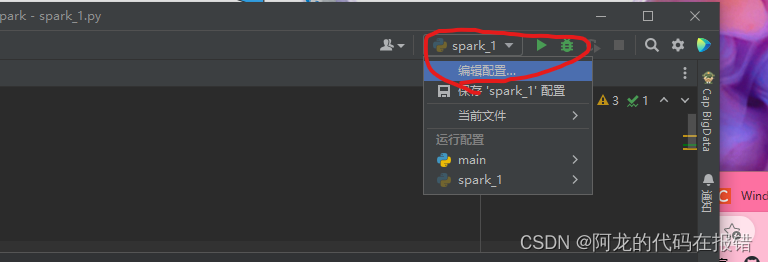
在这个位置点击编辑配置我就会来到下面这个界面

**
>PYTHONUNBUFFERED=1;SPARK_HOME=!!!这里这里这里是重中之中这里要写spark的安装路径!!!;PYSPARK_PYTHON=python
**
成功解决
最后一步就是重启pycharm
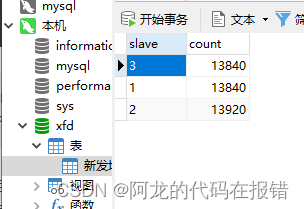
然后可以将数据写入数据库中了
写在最后:
这个是一个小小的个人报错笔记,希望对你有帮助,如果有不足的地方希望大家予以纠正,希望我们大家越来越好

















 3401
3401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











