







说明
KNIME是一个开源的机器学习平台,有兴趣可以自己查一下怎么用,这里几篇都是关于其中的示例介绍。
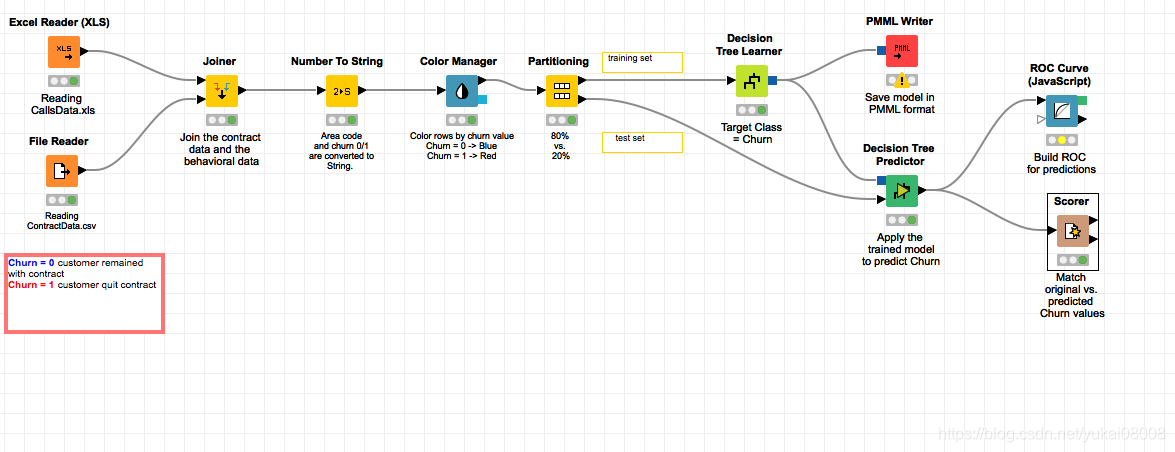
内容
1 获取数据
原始程序读取了两个文件并拼接在一起
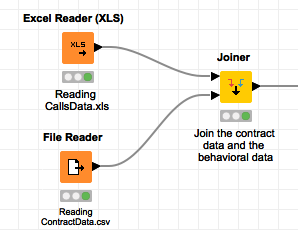
根据节点里的信息找到文件位置,拿出来

从上面可以看到,例子的来源是CallsData.xls, 从根目录下执行查找
find /|grep CallsData.xls
---
...
find: /.DocumentRevisions-V100: Permission denied
/Users/yukai/knime-workspace/Example Workflows/TheData/Customers/CallsData.xls
find: /dev/fd/3: Not a directory
打开文件,因为文件夹的名称有空格,要用单引号括起来
open '/Users/yukai/knime-workspace/Example Workflows/TheData/Customers'
找到了数据

- CallsData 对应行为数据
- ContractData 对应目标数据
# 目标数据
contract_df = pd.read_csv('ContractData.csv')
# churn=1表示流失
contract_df.head()
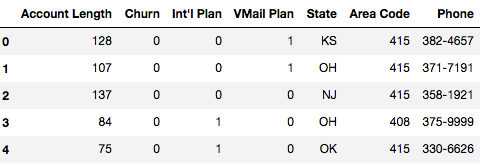
2 将数据连接起来
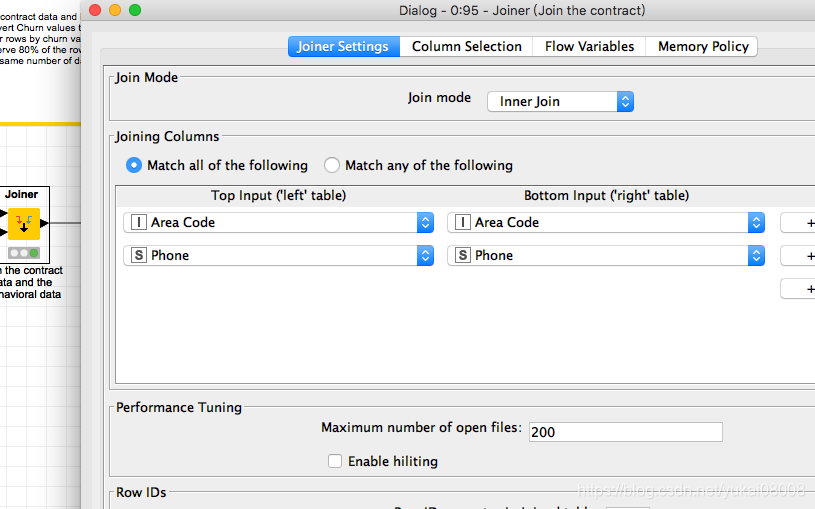
joint_df = pd.merge(left=callsdata_df, right = contract_df, how='inner', on=['Area Code','Phone'])
连接后的数据
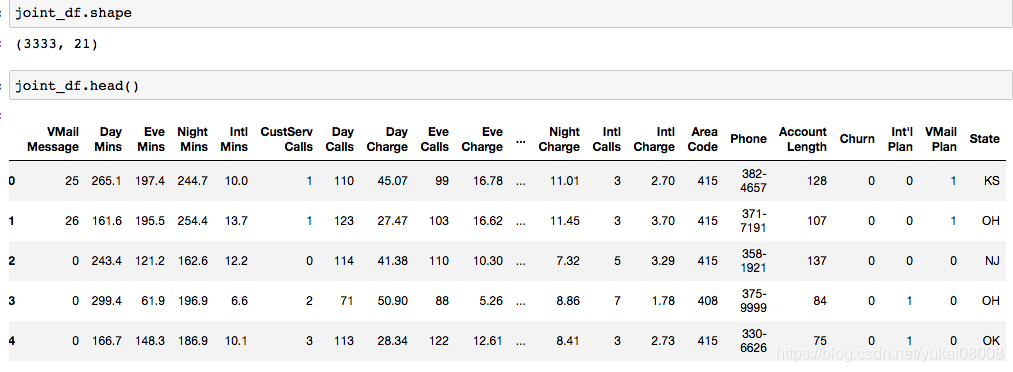
3 将数值转为字符
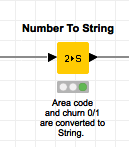
这一步在python里是没有必要的,从某种程度上,sklearn或者深度学习,其实最终反而将数据转为纯数值。
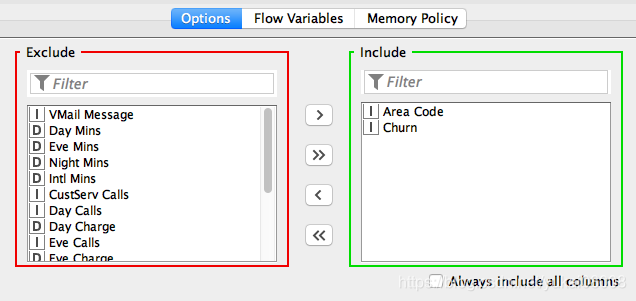
4 将数据进行标记
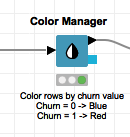
流失客户标记为红色
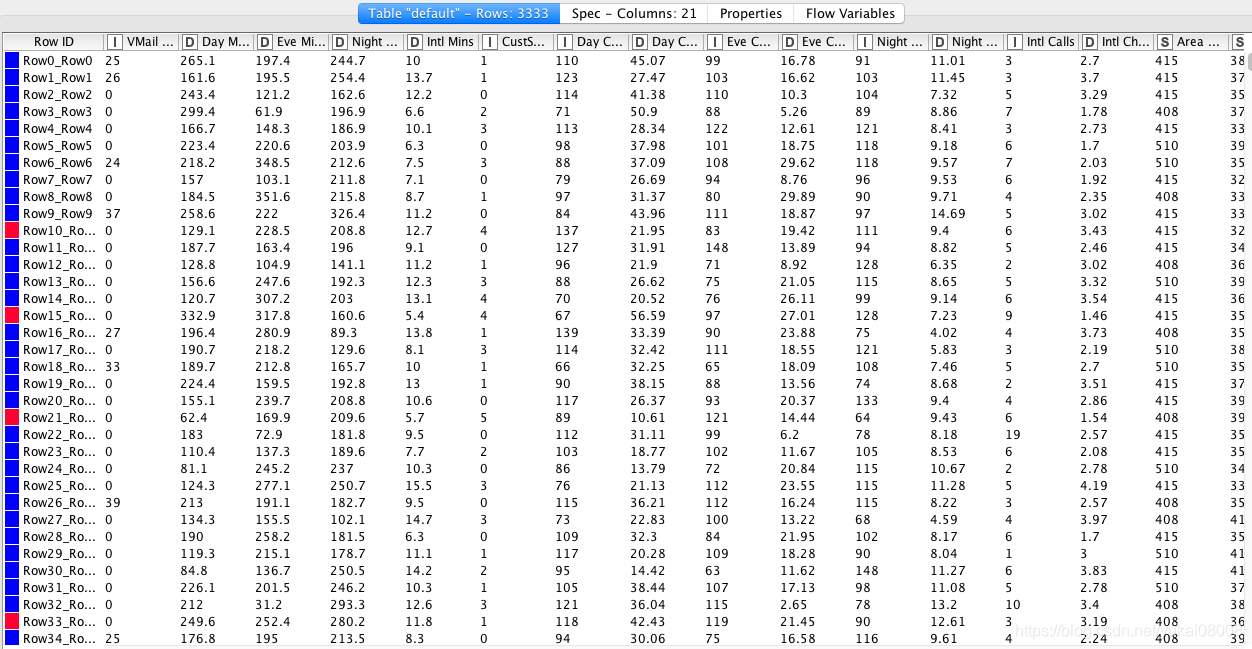
5 分层采样
按照80:20的比例将数据分割
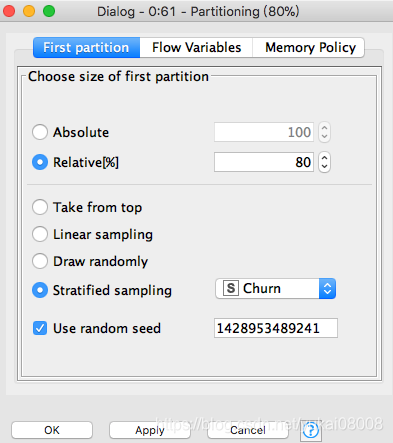
train_df, validate_df = train_validate_split(joint_df,target_varname='Churn',train_ratio=0.8)
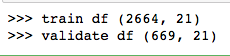
6 模型训练
#导入需要的模块
from sklearn import tree
#实例化
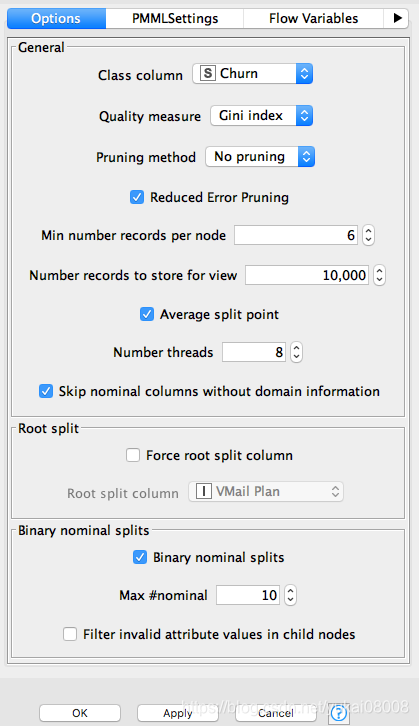
clf = tree.DecisionTreeClassifier(min_samples_leaf=6)
#用训练集数据训练模型
clf = clf.fit(X_train,y_train)
7 样本内测试结果
result = clf.score(X_validate,y_validate)
---
result
0.9312406576980568
这个结果足够好吗?
y_validate.mean()
0.1375186846038864
可以看到测试集中目标比例大约是13.7%,因此我盲猜不流失的准确率是86.3%。目前模型93%,说明是有一定效果的。
对应的jupyter notebook已上传至此处,需要可以下载

















 1399
1399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









