







目录
svm与knn对比
相似点:都是分类算法
不同点:分类依据不同(svm是划定一个线性边界,再对未知量进行分类;knn是当预测一个新的值x的时候,根据它距离最近的K个点是什么类别来判断x属于哪个类别)
svm:
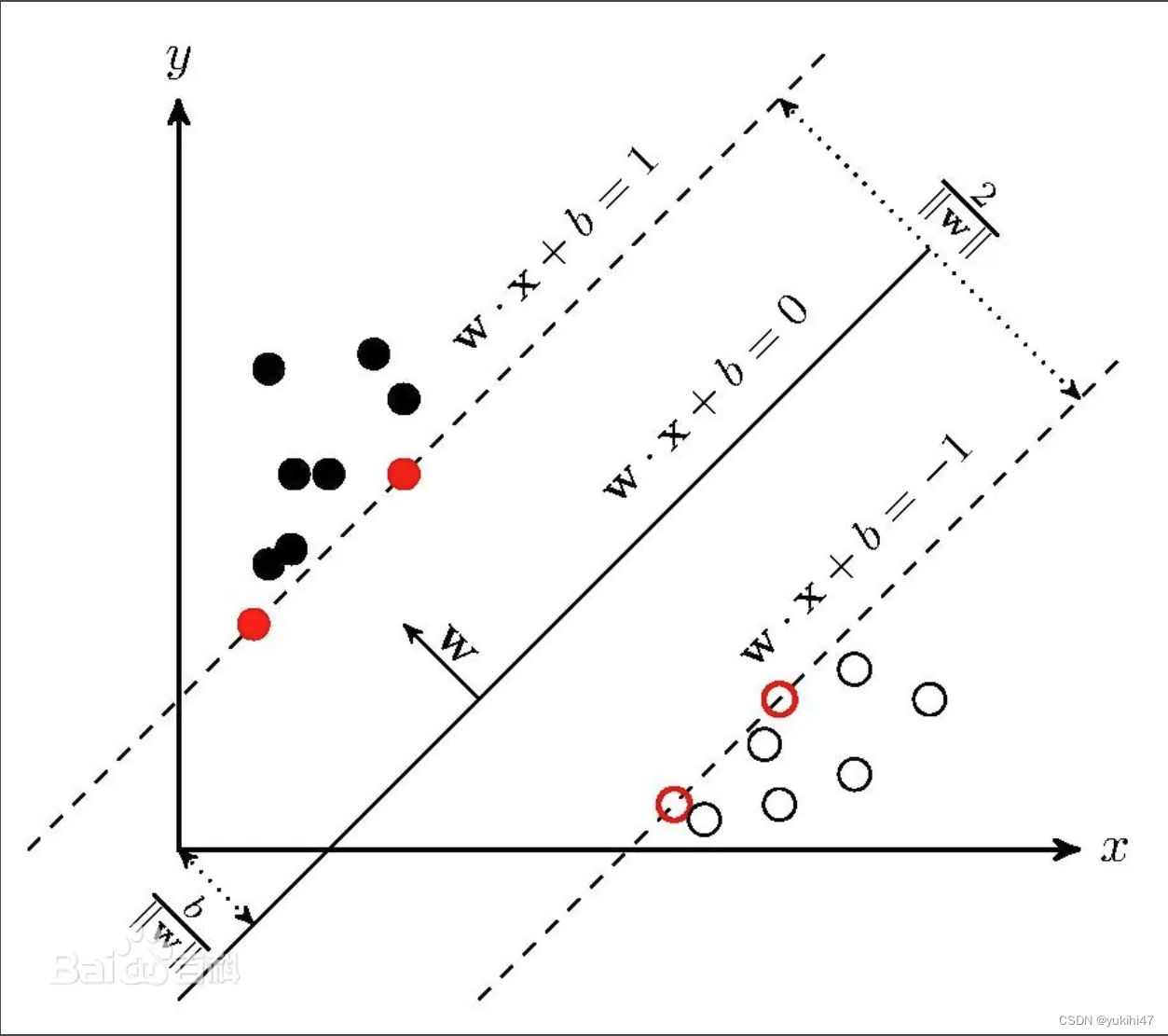
knn:
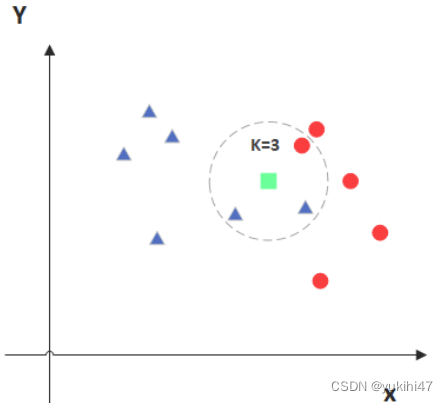
svm原理
“三八线”可以看作二维空间中SVM的形象解释,它传递出了以下几点重要的信息:
1.是一条直线(线性函数);
2.能将桌面分为两个部分,分别属于你和我(具有分类功能,是一种二值分类);
3.位于课桌正中间,不偏向任何一方(注重公平原则,才能保证双方利益最大化)。
以上三点也正是SVM分类器的中心思想所在。这是因为:SVM本质模型是特征空间中最大化间隔的线性分类器,是一种二分类模型。
首先,线性分类器指的就是线性函数;其次,最大化间隔离不开公平原则;再者,其解决的是二值分类问题(分两类);而特征空间则表明了其学习分类的对象是样本的特征数据。
之所以叫支持向量机,因为其核心理念是:支持向量样本会对识别的问题起关键性作用。那什么是支持向量(Support vector)呢?支持向量也就是离分类超平面(Hyper plane)最近的样本点。
如下图所示,有两类样本数据(橙色和蓝色的小圆点),中间的红线是分类超平面,两条虚线上的点(橙色圆点3个和蓝色圆点2个)是距离超平面最近的点,这些点即为支持向量。简单地说,作为支持向量的样本点非常非常重要,以至于其他的样本点可以视而不见。而这个分类超平面正是SVM分类器,通过这个分类超平面实现对样本数据一分为二。
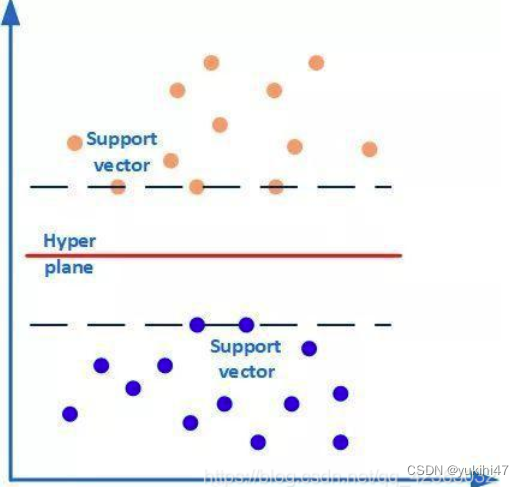
线性可分的时候,我们有很多条线(超平面)可以把这两类区分开。我们需要找到最优的超平面,即以这个超平面划分能让我们的数据尽可能的分开。所以支持向量机就是来求这个超平面的。尽可能分开的意思是:这两组数据离这个超平面最近的距离最大。
svm在百度飞桨的运行截图
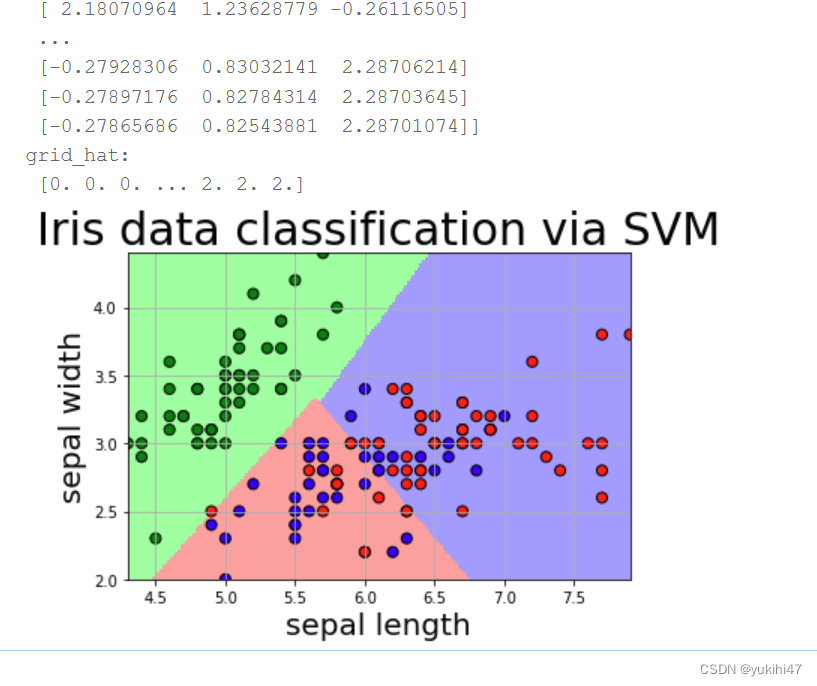

构建模型
# SVM分类器构建
def classifier():
clf = svm.SVC(C=0.5, # 误差惩罚系数,默认1
kernel='linear', # 线性核
decision_function_shape='ovr') # 决策函数
return clf训练模型
def train(clf, x_train, y_train): #将训练数据导入,将分类器参数导入,进行模型训练
clf.fit(x_train, #训练集特征向量
y_train.ravel()) #训练集目标值
# 2 定义模型 SVM模型定义
clf = classifier()
# 3 训练模型
train(clf, x_train, y_train)














 3708
3708











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









