







介绍下本人。中山大学,医学生+计科学生的集合体,机器学习爱好者。此处分享两次面试。
【一、总记】
由于一个契机,笔者联系到了本校数据院的老师,老师看了我的简历同意安排一个简单的面试来考察一下我的能力。接着笔者会分享两次不同团队的面试的回答记录,还请各位大佬批评指正。
【二、准备工作】
1、复习一下传统CNN、DenseNet、FastRCNN、Lightgbm、Xgboost、GBDT等常用算法的原理。
2、复习吴恩达深度学习笔记。
【三、第一次面试——20190909 15:00-16:00,面对面】
一、技术类(只记录技术类)
1、医学数据的特点
(1)数据不平衡。
(2)数据少。
2、医学数据不平衡有什么办法
(1)降采样。
(2)过采样。
3、医学数据量少有什么办法
(1)数据增强,比如图像拉伸旋转扭曲。
4、用什么框架
(1)一般用tensorflow
(2)百度开发者大赛用过paddlepaddle。
5、矩阵的秩的概念
(没答上来,忘记了)
(1)百度答案
①在线性代数中,一个矩阵A的列秩是A的线性独立的纵列的极大数目。
②类似地,行秩是A的线性无关的横行的极大数目。即如果把矩阵看成一个个行向量或者列向量,秩就是这些行向量或者列向量的秩,也就是极大无关组中所含向量的个数。
6、贝叶斯公式
(答错一半)
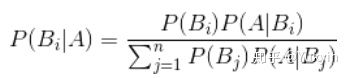
7、梯度和导数的区别
(1)梯度其实可以理解为导数。
(2)比如对权重系数(比如logistics回归里面的w、b)通过反向传播来修正。
(3)从而逐步减小代价函数cost。
【四、第二次面试——20190917 20:00-21:00,电话面试】
一、个人经历
1、自我介绍
(1)现在中山大学附属第一医院外科学研二,本科郑州大学临床医学。
(2)参加过数据算法比赛和学科交叉类比赛(创新大赛、电子设计大赛)。
(3)发表过论文壁报,授权实用新型专利,主要是医疗器械类,因为更好结合专业。
2、根据自我介绍的提问
(1)项目中的角色
①本科学科交叉比赛:开始是提出idea,做负责人,主要统筹协调。之后自学一些内容,可以编写单片机部分功能的代码,设计部分电路。
②数据算法类比赛:solo,会跟群里小伙伴交流,群里同学提出的名词会去网上查询原理和自己实现相关代码。
(2)做了多久机器学习,机器学习相关内容平时有人请教吗,周围有同学做吗
①一年半。
②平时会跟参加比赛的同学们交流。
③周围医学同学不做,因为医学大部分是单因素、多因素回归,之后最多会使用决策树,很少在方法学改进。
(3)平时是分类任务多吗
①是的。大部分是二分类的。
②CCF比赛中有做过多分类的。
(4)代码仓库有整理吗
①习惯整理到本地。
(5)课题组也做机器学习相关内容吗
①是的,临床研究中心。
②做肝癌的精准治疗,会辅助人工智能进行预测预后和提出诊断方法。
(6)医学为什么数据那么少
①因为根据不同课题的入排标准而定。
②而且医学数据还有不平衡的问题,可能需要降采样。
(7)有学过计算机基础课吗
①自学数据结构、组成原理。
②刷leetcode喜欢用c和python。
2、介绍一个你印象深刻的项目(我说了我的课题)
(1)算法
①主要是densenet,效果比resnet好。
②最近有一篇H-denseUnet的文章,想尝试。
(2)流程
①(我说了一遍我的课题摘要,此处暂时不方便分享)
(3)数据量
①目前100+。
②计划1000+。
(4)是否自己添加网络层
①还没有,现在是套用源码进行修改。
②因为数据量比较小,而且标签有多套。
(5)开源代码还是自己写
①开源代码修改。
(6)计算资源从哪里来
①小数据用笔记本,1660Ti,大数据用在线平台。
②因为课题组的服务器主要是看图的(适合绘图),主要是cpu服务器。
③医学数据也比较少,课题组没什么gpu服务器。
(7)做了什么预处理
①常规数据增强、缺失值填充、归一化。
②一些比较复杂的预处理比如CPCD不太会。
(8)准确率怎么样
①自己课题目前只有0.7+。因为数据量小且多套标签,标签不太准。
②之前做的生信测序的课题lgb效果不好。怀疑是数据量小,所以节点分不开。
用rf也只有0.6+。因为数据量只有60+,特征维度有10w,各种降维方法都不太好。
3、还做过什么深度学习相关的项目
(1)医疗数据比赛
①高血压患者三年期的冠心病发病风险,心脏彩超数据。
②普通的CNN提取特征后当做特征向量放入lgb。
(2)百度开发者大赛
①行人识别,paddlepaddle,使用了预训练模型。
②但平时主要用tensorflow。
二、技术
1、卷积神经网络的特点
(1)卷积是特征提取的过程。
(2)原始的特征矩阵可以分成多个特征矩阵,用卷积核和特征矩阵做外积可以提取部分特征。
(3)之后进行padding。
(4)再池化进一步提取特征,即为降维,增加泛化能力。一般是最大池化。
(5)最后全连接softmax进行分类。
2、卷积神经网络和普通神经网络的区别(这个问题开始没听懂,面试的大师兄翻译为全连接层和其他层的区别)
(1)其它层是中间有一些隐层,并不是全连接。
(2)全连接是最后池化之后才连接各个神经元。
(3)不然如果每一层都全连接,那特征维度太高,很容易过拟合。
3、过拟合的解决办法
(1)正则化。
(2)dropout随机丢弃一些神经元,比如设置为0.8。
(3)增大样本量。
(4)k折交叉验证,k一般选5。(不记得是不是这个问题我回答的答案了)
4、激活函数类别和特点
(1)一般最后一层二分类就是用sigmoid,多分类用softmax。中间层用relu效果好。
(2)sigmoid是个类似正弦函数的东西(其实不是…),最大值趋近于1,最小值趋近于0。①一般激活函数起作用在中间的线性部分。
②而如果输入值过大或者过小,会进入平台那里,就无法起作用。
(3)tanh是类似sigmoid下移,最大值趋近于1,最小值趋近于-1。
①因为是奇函数,数据平均值是0,有数据中心化的作用,也有利于下一层学习。
(4)relu负半部分是x轴,正半部分是y=x。
①所以对正性样本响应明显,而对负性样本全部过滤掉,这样会丢失一些特征。
②所以有个改进叫leaky relu,负半部分有个随机值,并不是全部丢弃。
③其他还有一些基于relu改进的函数,不常用。
5、用什么语言,用的这几种语言有什么区别
(1)数据算法用python,单片机开发用c。
(2)python是高级语言,底层是c++写的,运行比较慢。c运行快,但c需要定义变量及类型,一个简单的功能实现都要写很多代码。
6、准确率和召回率是什么,一般用什么评价函数
(1)(准确率和召回率,没回答出来,只说了个混淆矩阵。)
(2)评价函数一般用auc,有些比赛会用logloss,也有一些是自定义的比如f1 score。
三、未来畅想聊天类
1、未来课题方向想法
(1)希望能在方法学有所改进。
(2)因为医学idea其实很多都有人做了,方法学都很像,所以想在方法学改进。
2、要读博吗,做什么方向
(1)肯定读的。
(2)希望做偏底层的,理论多一点,当然也要结合实践,毕竟AI是需要应用到各个场景,但还是希望能多学一些理论方面的内容。
3、有什么问题(我问大师兄回答)
(1)实习是要做什么:方法学改进,算法方面。
(2)课题组节奏:995。
(3)安排:小组形式做课题。
(4)组会:一周一次,这一周提出一个idea,下一周需要有一个版本的模型。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









