







简单的说 编译器 就是语言翻译器,它一般将高级语言翻译成更低级的语言,如 GCC 可将 C/C++ 语言翻译成可执行机器语言,Java 编译器可以将 Java 源代码翻译成 Java 虚拟机可以执行的字节码。
编译器如此神奇,那么它到底是如何工作的呢?本文将简单介绍编译器的原理,并实现一个简单的编译器,使它能编译我们自定义语法格式的源代码。(文中使用的源码都已上传至 GitHub 以方便查看)。
自定义语法
为了简洁易懂,我们的编译器将只支持以下简单功能:
数据类型只支持整型,这样不需要数据类型符;
支持
加(+),减(-),乘(*),除(/)运算支持函数调用
支持
extern(为了调用printf打印计算结果)
以下是我们要支持的源码实例 demo.xy:
extern printi(val)
sum(a, b) {
return a + b
}
mult(a, b) {
return a * b
}
printi(mult(4, 5) - sum(4, 5))
编译原理简介
一般编译器有以下工作步骤:
词法分析(Lexical analysis): 此阶段的任务是从左到右一个字符一个字符地读入源程序,对构成源程序的字符流进行扫描然后根据构词规则识别
单词(Token),完成这个任务的组件是词法分析器(Lexical analyzer,简称Lexer),也叫扫描器(Scanner);语法分析(Syntactic analysis,也叫 Parsing): 此阶段的主要任务是由
词法分析器生成的单词构建抽象语法树(Abstract Syntax Tree ,AST),完成此任务的组件是语法分析器(Parser);目标码生成: 此阶段编译器会遍历上一步生成的抽象语法树,然后为每个节点生成
机器 / 字节码。
编译器完成编译后,由 链接器(Linker) 将生成的目标文件链接成可执行文件,这一步并不是必须的,一些依赖于虚拟机运行的语言(如 Java,Erlang)就不需要链接。
工具简介
对应编译器工作步骤我们将使用以下工具,括号里标明了所使用的版本号:
Flex(2.6.0): Flex 是 Lex 开源替代品,他们都是
词法分析器制作工具,它可以根据我们定义的规则生成词法分析器的代码;Bison(3.0.4): Bison 是
语法分析器的制作工具,同样它可以根据我们定义的规则生成语法分析器的代码;LLVM(3.8.0): LLVM 是构架编译器的框架系统,我们会利用他来完成从
抽象语法树生成目标码的过程。
在 ubuntu 上可以通过以下命令安装这些工具:
sudo apt-get install flex
sudo apt-get install bison
sudo apt-get install llvm-3.8*介绍完工具,现在我们可以开始实现我们的编译器了。
词法分析器
前面提到 词法分析器 要将源程序分解成 单词,我们的语法格式很简单,只包括:标识符,数字,数学运算符,括号和大括号等,我们将通过 Flex 来生成 词法分析器 的源码,给 Flex 使用的规则文件 lexical.l 如下:
%{
#include <string>
#include "ast.h"
#include "syntactic.hpp"
#define SAVE_TOKEN yylval.string = new std::string(yytext, yyleng)
#define TOKEN(t) (yylval.token = t)
%}
%option noyywrap
%%
[ \t\n] ;
"extern" return TOKEN(TEXTERN);
"return" return TOKEN(TRETURN);
[a-zA-Z_][a-zA-Z0-9_]* SAVE_TOKEN; return TIDENTIFIER;
[0-9]+ SAVE_TOKEN; return TINTEGER;
"=" return TOKEN(TEQUAL);
"==" return TOKEN(TCEQ);
"!=" return TOKEN(TCNE);
"(" return TOKEN(TLPAREN);
")" return TOKEN(TRPAREN);
"{" return TOKEN(TLBRACE);
"}" return TOKEN(TRBRACE);
"," return TOKEN(TCOMMA);
"+" return TOKEN(TPLUS);
"-" return TOKEN(TMINUS);
"*" return TOKEN(TMUL);
"/" return TOKEN(TDIV);
. printf("Unknown token!\n"); yyterminate();
%%
我们来解释一下,这个文件被 2 个 %% 分成 3 部分,第 1 部分用 %{ 与 %} 包括的是一些 C++ 代码,会被原样复制到 Flex 生成的源码文件中,还可以在指定一些选项,如我们使用了 %option noyywrap,也可以在这定义宏供后面使用;第 2 部分用来定义构成单词的规则,可以看到每条规都是一个 正则表达式 和 动作,很直白,就是 词法分析器 发现了匹配的 单词 后执行相应的 动作 代码,大部分只要返回 单词 给调用者就可以了;第 3 部分可以定义一些函数,也会原样复制到生成的源码中去,这里我们留空没有使用。
现在我们可以通过调用 Flex 生成 词法分析器 的源码:
flex -o lexical.cpp lexical.l生成的 lexical.cpp 里会有一个 yylex() 函数供 语法分析器 调用;你可能发现了,有些宏和变量并没有被定义(如 TEXTERN,yylval,yytext 等),其实有些是 Flex 会自动定义的内置变量(如 yytext),有些是后面 语法分析器 生成工具里定义的变量(如 yylval),我们后面会看到。
语法分析器
语法分析器 的作用是构建 抽象语法树,通俗的说 抽象语法树 就是将源码用树状结构来表示,每个节点都代表源码中的一种结构;对于我们要实现的语法,其语法树是很简单的,如下:
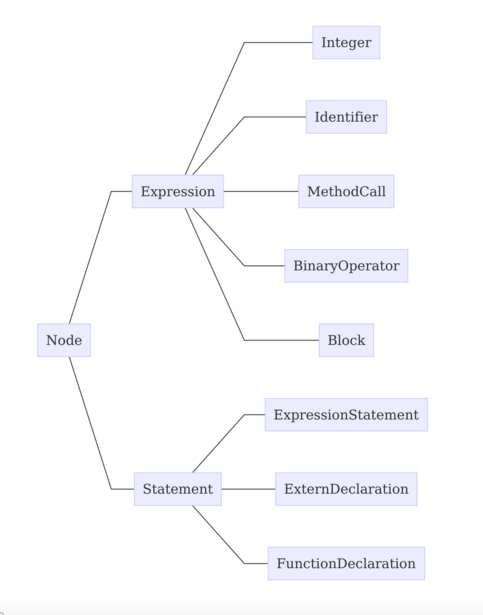
现在我们使用 Bison 生成 语法分析器 代码,同样 Bison 需要一个规则文件,我们的规则文件 syntactic.y 如下,限于篇幅,省略了某些部分,可以通过链接查看完整内容:
%{
#include "ast.h"
#include <cstdio>
...
extern int yylex();
void yyerror(const char *s) { std::printf("Error: %s\n", s);std::exit(1); }
%}
...
%token <token> TLPAREN TRPAREN TLBRACE TRBRACE TCOMMA
...
%%
program:
stmts { programBlock = $1; }
;
...
func_decl:
ident TLPAREN func_decl_args TRPAREN block { $$ = new NFunctionDeclaration(*$1, *$3, *$5); delete $3; }
;
...
%%
是不是发现和 Flex 的规则文件很像呢?确实是这样,它也是分 3 个部分组成,同样,第一部分的 C++ 代码会被复制到生成的源文件中,还可以看到这里通过以下这样的语法定义前面了 Flex 使用的宏:
%token <token> TLPAREN TRPAREN TLBRACE TRBRACE TCOMMA比较不同的是第 2 部分,不像 Flex 通过 正则表达式 通过定义规则,这里使用的是 巴科斯范式(BNF: Backus-Naur Form) 的形式定义了我们识别的语法结构。如下的语法表示函数:
func_decl:
ident TLPAREN func_decl_args TRPAREN block { $$ = new NFunctionDeclaration(*$1, *$3, *$5); delete $3; }
;可以看到后面大括号中间的也是 动作 代码,上例的动作是在 抽象语法树 中生成一个函数的节点,其实这部分的其他规则也是生成相应类型的节点到语法树中。像 NFunctionDeclaration 这是一个我们自己定义的节点类,我们在 ast.h 中定义了我们所要用到的节点,同样的,我们摘取一段代码如下:
...
class NFunctionDeclaration : public NStatement {
public:
const NIdentifier& id;
VariableList arguments;
NBlock& block;
NFunctionDeclaration(const NIdentifier& id,
const VariableList& arguments, NBlock& block) :
id(id), arguments(arguments), block(block) { }
virtual llvm::Value* codeGen(CodeGenContext& context);
};
...
可以看到,它有 标识符(id),参数列表(arguments),函数体(block) 这些成员,在语法分析阶段会设置好这些成员的内容供后面的 目标码生成 阶段使用。还可以看到有一个 codeGen() 虚函数,你可能猜到了,后面就是通过调用它来生成相应的目标代码。
我们可以通过以下命令调用 Bison 生成 语法分析器 的源码文件,这里我们使用 -d 使头文件和源文件分开,因为前面 词法分析器 的源码使用了这里定义的一些宏,所以需要使用这个头文件,这里将会生成 syntactic.cpp 和 syntactic.hpp:
bison -d -o syntactic.cpp syntactic.y目标码生成
这是最后一步了,这一步的主角是前面提到 LLVM,LLVM 是一个构建编译器的框架系统,我们使用他遍历 语法分析 阶段生成的 抽象语法树,然后为每个节点生成相应的 目标码。当然,无法避免的是我们需要使用 LLVM 提供的函数来编写生成目标码的源码,就是实现前面提到的虚函数 codeGen(),是不是有点拗口?不过确实是这样。我们在 gen.cpp 中编写了不同节点的生成代码,我们摘取一段看一下:
...
Value *NMethodCall::codeGen(CodeGenContext &context) {
Function *function = context.module->getFunction(id.name.c_str());
if (function == NULL) {
std::cerr << "no such function " << id.name << endl;
}
std::vector<Value *> args;
ExpressionList::const_iterator it;
for (it = arguments.begin(); it != arguments.end(); it++) {
args.push_back((**it).codeGen(context));
}
CallInst *call = CallInst::Create(function, makeArrayRef(args), "", context.currentBlock());
std::cout << "Creating method call: " << id.name << endl;
return call;
}
...
看起来有点复杂,简单来说就是通过 LLVM 提供的接口来生成 目标码,需要了解更多的话可以去 LLVM 的官网学习一下。
至此,我们所有的工作基本都做完了。简单回顾一下:我们先通过 Flex 生成 词法分析器 源码文件 lexical.cpp,然后通过 Bison 生成 语法分析器 源码文件 syntactic.cpp 和头文件 syntactic.hpp,我们自己编写了 抽象语法树 节点定义文件 ast.h 和 目标码 生成文件 ast.cpp,还有一个 gen.h 包含一点 LLVM 环境相关的代码,为了输出我们程序的结果,还在 printi.cpp 里简单的通过调用 C 语言库函数实现了输出一个整数。
对了,我们还需要一个 main 函数作为编译器的入口函数,它在 main.cpp 里:
...
int main(int argc, char **argv) {
yyparse();
InitializeNativeTarget();
InitializeNativeTargetAsmPrinter();
InitializeNativeTargetAsmParser();
CodeGenContext context;
context.generateCode(*programBlock);
context.runCode();
return 0;
}
我们可以看到其调用了 yyparse() 做 语法分析,(yyparse() 内部会先调用 yylex() 做 词法分析);然后是一系列的 LLVM 初始化代码,context.generateCode(*programBlock) 是开始生成 目标码;最后是 context.runCode() 来运行代码,这里使用了 LLVM 的 JIT(Just In Time) 来直接运行代码,没有链接的过程。
现在我们可以用这些文件生成我们的编译器了,需要说明一下,因为 词法分析器 的源码使用了一些 语法分析器 头文件中的宏,所以正确的生成顺序是这样的:
bison -d -o syntactic.cpp syntactic.y
flex -o lexical.cpp lexical.l syntactic.hpp
g++ -c `llvm-config --cppflags` -std=c++11 syntactic.cpp gen.cpp lexical.cpp printi.cpp main.cpp
g++ -o xy-complier syntactic.o gen.o main.o lexical.o printi.o `llvm-config --libs` `llvm-config --ldflags` -lpthread -ldl -lz -lncurses -rdynamic如果你下载了 GitHub 的源码,那么直接:
cd src
make就可以完成以上过程了,正常会生成一个二进制文件 xy-complier,它就是我们的编译器了。
编译测试
我们使用之前提到实例 demo.xy 来测试,将其内容传给 xy-complier 的标准输入就可以看到运行结果了:
cat demo.xy | ./xy-complier也可以直接通过
make test来测试,输出如下:
...
define internal i64 @mult(i64 %a1, i64 %b2) {
entry:
%a = alloca i64
%0 = load i64, i64* %a
store i64 %a1, i64* %a
%b = alloca i64
%1 = load i64, i64* %b
store i64 %b2, i64* %b
%2 = load i64, i64* %b
%3 = load i64, i64* %a
%4 = mul i64 %3, %2
ret i64 %4
}
Running code:
11
Exiting...可以看到最后正确输出了期望的结果,至此我们简单的编译器就完成了。















 8886
8886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









