







tensorflow中交叉熵损失函数
引用API:tensorflow.kreas.losses.categorical_crossentropy
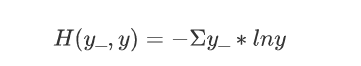
则,tf.losses.categorical_crossentropy(y_, y) #y_为真实值,y为预测值
交叉熵是说明两个概率分布之间的距离,距离越小,说明二者分布越接近
例如:已知真实值y_(1, 1),预测值y1(0.8, 0.6),预测值y2(0.2, 0.4)。这两个预测值哪一个距离真实值最近。
可得:H1((1, 1), (0.8, 0.5)) = -(1 * ln(0.8) + 1 * ln(0.5)) ~0.69
H2((1, 2), (0.2, 0.4)) = -(1 * ln(0.2) + 1 * ln(0.4)) ~0.92
因为H1<H2,所以H1更接近真实值
tensorflow中交叉熵损失函数预测酸奶价格
import tensorflow as tf
import numpy as np
seed = 23456 #定义种子数值
rdm = np.random.RandomState(seed) #生成[0, 1)之间的小数,由于固定seed数值,每次生成的数值都一样
x = rdm.rand(32, 2) #生成32行2列的输入特征x
np.set_printoptions(threshold=6) #概略显示
print("32行2列的特征xs为:", x) # 打印输入特征,概略显示5行
y_ = [[x1 + x2 + (rdm.rand() / 10.0 - 0.05)] for (x1, x2) in x] #从x中取出x1,x2相加,并且加上-0.05到+0.05随机噪声,得到标准答案y_
x = tf.cast(x, dtype = tf.float32) #转换x数据类型
print("转换数据类型后x:", x) #打印转换书籍类型后的x
w1 = tf.Variable(tf.random.normal([2, 1], stddev = 1, seed = 1)) #初始化参数w1,生成两行一列的可训练参数
print("w1为:", w1)
epoch = 15000 #迭代次数为15000次
lr = 0.002 #学习率为0.002
for epoch in range(epoch):
with tf.GradientTape() as tape: #用with上下文管理器调用GradientTape()方法
y = tf.matmul(x, w1) #求前向传播计算结果y
# loss_mse = tf.reduce_mean(tf.square(y_ - y)) #求均方误差loss_mean
loss_mse = tf.losses.categorical_crossentropy(y_, y) # 求交叉熵loss_mean
# print("y为:", y)
# print("loss_mean为:", loss_mse)
grads = tape.gradient(loss_mse, w1) #损失函数对待训练参数w1求偏导
w1.assign_sub(lr * grads) #更新参数w1
if epoch % 500 == 0: #每迭代500轮
print("After %d training steps, w1 is " % epoch) #每迭代500轮打印当前w1参数
print(w1.numpy(), "\n") #打印当前w1参数
print("Final w1 is :", w1.numpy()) #打印最终w1
结果为:
E:\Anaconda3\envs\TF2\python.exe C:/Users/Administrator/PycharmProjects/untitled8/酸奶价格预测.py
32行2列的特征xs为: [[0.32180029 0.32730047]
[0.92742231 0.31169778]
[0.16195411 0.36407808]
...
[0.83554249 0.59131388]
[0.2829476 0.05663651]
[0.2916721 0.33175172]]
转换数据类型后x: tf.Tensor(
[[0.3218003 0.32730046]
[0.9274223 0.31169778]
[0.1619541 0.36407807]
...
[0.8355425 0.5913139 ]
[0.2829476 0.05663651]
[0.29167208 0.33175173]], shape=(32, 2), dtype=float32)
w1为: <tf.Variable 'Variable:0' shape=(2, 1) dtype=float32, numpy=
array([[-0.8113182],
[ 1.4845988]], dtype=float32)>
After 0 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 500 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 1000 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 1500 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 2000 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 2500 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 3000 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 3500 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 4000 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 4500 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 5000 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 5500 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 6000 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 6500 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 7000 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 7500 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 8000 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 8500 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 9000 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 9500 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 10000 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 10500 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 11000 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 11500 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 12000 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 12500 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 13000 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 13500 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 14000 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]After 14500 training steps, w1 is
[[-0.8113182]
[ 1.4845988]]Final w1 is : [[-0.8113182]
[ 1.4845988]]Process finished with exit code 0
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









