






目标:我们的集群需要设计对于某些表不做compaction,客户提出来可以提高compaction Threshold文件个数从默认的3到10来避免这个问题,但是这样会导致集群的通用型降低,而且会有损meta表的查询性能。
再不做这些改变的情况下,探索hbase现在有的设计中,如何规避compaction发生
本文主要根据http://www.wtoutiao.com/p/g6a0wA.html中给出的流程图进行部分代码走读
1
2
3
首先开始的位置是
HRegionServer.java
他包含如下两个thread进行compact操作
compactSplitThread //负责进行compact处理
compactionChecker //周期性的唤醒,进行检查是否需要compact,如果需要,会提交compact requst到compactSplitThread中
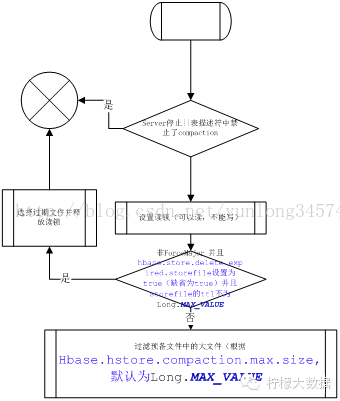
1compactionChecker 进行检查的时候是根据配置的policy来进行判断
protected void chore() {
for (Region r : this.instance.onlineRegions.values()) {
if (r == null)
continue;
for (Store s : r.getStores()) {
try {
long multiplier = s.getCompactionCheckMultiplier();
assert multiplier > 0;
if (iteration % multiplier != 0) continue;
if (s.needsCompaction()) {
// Queue a compaction. Will recognize if major is needed.
this.instance.compactSplitThread.requestSystemCompaction(r, s, getName()
+ " requests compaction");
} else if (s.isMajorCompaction()) {
if (majorCompactPriority == DEFAULT_PRIORITY
|| majorCompactPriority > ((HRegion)r).getCompactPriority()) {
this.instance.compactSplitThread.requestCompaction(r, s, getName()
+ " requests major compaction; use default priority", null);
} else {
this.instance.compactSplitThread.requestCompaction(r, s, getName()
+ " requests major compaction; use configured priority",
this.majorCompactPriority, null, null);
}
}
} catch (IOException e) {
LOG.warn("Failed major compaction check on " + r, e);
}
}
}
iteration = (iteration == Long.MAX_VALUE) ? 0 : (iteration + 1);
}这里的s.needsCompaction
HStore.java
public boolean needsCompaction() {
return this.storeEngine.needsCompaction(this.filesCompacting);
}默认情况下是defaultEngine,注册的policy是
ExploringCompactionPolicy,继承自RatioBasedCompactionPolicy,主要特点就是根据文件个数和大小进行查找compact的最优解,这个网上有很多介绍
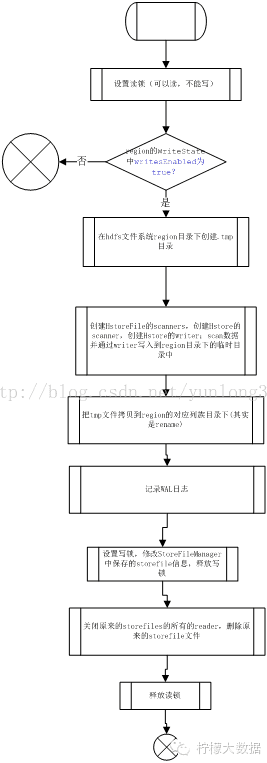
确定好需要做之后,会提交compaction request到compactSplitThread
this.instance.compactSplitThread.requestSystemCompaction(r, s, getName()
+ " requests compaction");下面看一下CompactSplitThread.java
private synchronized CompactionRequest requestCompactionInternal(final Region r, final Store s,
final String why, int priority, CompactionRequest request, boolean selectNow, User user)
throws IOException {
if (this.server.isStopped()
|| (r.getTableDesc() != null && !r.getTableDesc().isCompactionEnabled())) {
return null;
}这里需要注意一点, 他会判断表的TableDesc,查看是否CompactionEnabled,默认是ture,但是可以自行设置。这里的配置是全表级别,而且很明显,一旦设置好之后,不会对这个表做任何compaction
这里对应的jira:https://issues.apache.org/jira/browse/HBASE-7875
但是上面的jira中的例子并不对,禁止表发生compaction的配置应该是如下(这里很坑爹,官方的例子竟然是错误的):
hbase(main):002:0> disable 'xinglwang_test0126'
0 row(s) in 3.2380 seconds
hbase(main):003:0> alter 'xinglwang_test0126',{METHOD => 'table_att', COMPACTION_ENABLED => 'FALSE'}
Unknown argument ignored: COMPACTION_ENABLED
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 2.7980 seconds
hbase(main):004:0> disable 'xinglwang_test0126'
0 row(s) in 0.0330 seconds
hbase(main):005:0> describe 'xinglwang_test0126'
Table xinglwang_test0126 is DISABLED
xinglwang_test0126, {TABLE_ATTRIBUTES => {METADATA => {'COMPACTION_ENABLED' => 'false'}}
COLUMN FAMILIES DESCRIPTION
{NAME => 'f1', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'f2', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'f3', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
3 row(s) in 0.0300 secondsBULK Load文件
StoreFile.java中有一个meta参数,这个参数最终影响了minorCompaction中的文件选择,bulkload文件会被排除出去。但是如果是major compaction的话,bulkload文件也是会被compact的
public boolean excludeFromMinorCompaction() {
return this.excludeFromMinorCompaction;
}RationBasedCompactionPolicy.java
private ArrayList<StoreFile> filterBulk(ArrayList<StoreFile> candidates) {
candidates.removeAll(Collections2.filter(candidates,
new Predicate<StoreFile>() {
@Override
public boolean apply(StoreFile input) {
return input.excludeFromMinorCompaction();
}
}));
return candidates;
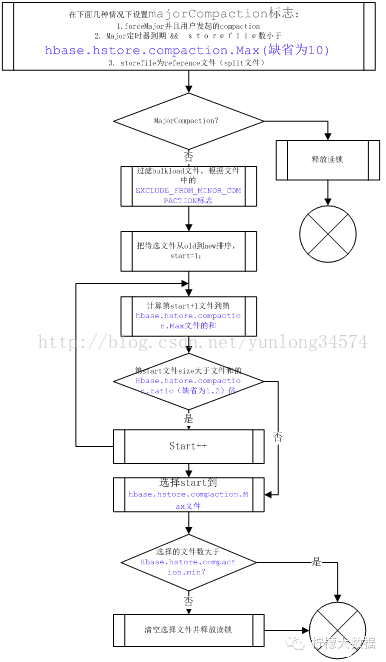
}public CompactionRequest selectCompaction(Collection<StoreFile> candidateFiles,
final List<StoreFile> filesCompacting, final boolean isUserCompaction,
final boolean mayUseOffPeak, final boolean forceMajor) throws IOException {
// Preliminary compaction subject to filters
ArrayList<StoreFile> candidateSelection = new ArrayList<StoreFile>(candidateFiles);
// Stuck and not compacting enough (estimate). It is not guaranteed that we will be
// able to compact more if stuck and compacting, because ratio policy excludes some
// non-compacting files from consideration during compaction (see getCurrentEligibleFiles).
int futureFiles = filesCompacting.isEmpty() ? 0 : 1;
boolean mayBeStuck = (candidateFiles.size() - filesCompacting.size() + futureFiles)
>= storeConfigInfo.getBlockingFileCount();
candidateSelection = getCurrentEligibleFiles(candidateSelection, filesCompacting);
LOG.debug("Selecting compaction from " + candidateFiles.size() + " store files, " +
filesCompacting.size() + " compacting, " + candidateSelection.size() +
" eligible, " + storeConfigInfo.getBlockingFileCount() + " blocking");
// If we can't have all files, we cannot do major anyway
boolean isAllFiles = candidateFiles.size() == candidateSelection.size();
if (!(forceMajor && isAllFiles)) {
candidateSelection = skipLargeFiles(candidateSelection);
isAllFiles = candidateFiles.size() == candidateSelection.size();
}
// Try a major compaction if this is a user-requested major compaction,
// or if we do not have too many files to compact and this was requested as a major compaction
boolean isTryingMajor = (forceMajor && isAllFiles && isUserCompaction)
|| (((forceMajor && isAllFiles) || isMajorCompaction(candidateSelection))
&& (candidateSelection.size() < comConf.getMaxFilesToCompact()));
// Or, if there are any references among the candidates.
boolean isAfterSplit = StoreUtils.hasReferences(candidateSelection);
if (!isTryingMajor && !isAfterSplit) {
// We're are not compacting all files, let's see what files are applicable
candidateSelection = filterBulk(candidateSelection);
candidateSelection = applyCompactionPolicy(candidateSelection, mayUseOffPeak, mayBeStuck);
candidateSelection = checkMinFilesCriteria(candidateSelection);
}
candidateSelection = removeExcessFiles(candidateSelection, isUserCompaction, isTryingMajor);
// Now we have the final file list, so we can determine if we can do major/all files.
isAllFiles = (candidateFiles.size() == candidateSelection.size());
CompactionRequest result = new CompactionRequest(candidateSelection);
result.setOffPeak(!candidateSelection.isEmpty() && !isAllFiles && mayUseOffPeak);
result.setIsMajor(isTryingMajor && isAllFiles, isAllFiles);
return result;
}CompactSplitThread.java
private CompactionContext selectCompaction(final Region r, final Store s,
int priority, CompactionRequest request) throws IOException {
CompactionContext compaction = s.requestCompaction(priority, request);
if (compaction == null) {
if(LOG.isDebugEnabled()) {
LOG.debug("Not compacting " + r.getRegionInfo().getRegionNameAsString() +
" because compaction request was cancelled");
}
return null;
}
assert compaction.hasSelection();
if (priority != Store.NO_PRIORITY) {
compaction.getRequest().setPriority(priority);
}
return compaction;
}之所以说blukload不会幸免major compaction
RationBasedCompactionPolicy.java
/ Try a major compaction if this is a user-requested major compaction,
// or if we do not have too many files to compact and this was requested as a major compaction
boolean isTryingMajor = (forceMajor && isAllFiles && isUserCompaction)
|| (((forceMajor && isAllFiles) || isMajorCompaction(candidateSelection))
&& (candidateSelection.size() < comConf.getMaxFilesToCompact()));
// Or, if there are any references among the candidates.
boolean isAfterSplit = StoreUtils.hasReferences(candidateSelection);
if (!isTryingMajor && !isAfterSplit) {
// We're are not compacting all files, let's see what files are applicable
candidateSelection = filterBulk(candidateSelection);














 293
293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









