




开篇
近日,由阿里云计算平台大数据基础工程技术团队主导,与南京大学、宾夕法尼亚州立大学、清华大学等高校合作,解释时间序列预测模型的论文《Explaining Time Series via Contrastive and Locally Sparse Perturbations》被机器学习领域顶会ICLR 2024接收。该论文提出了一种创新的基于扰动技术的时间序列解释框架ContraLSP,该框架主要包含一个学习反事实扰动的目标函数和一个平滑条件下稀疏门结构的压缩器。论文在白盒时序预测,黑盒时序分类等仿真数据,和一个真实时序数据集分类任务中进行了实验,ContraLSP在解释性能上超越了SOTA模型,显著提升了时间序列数据解释的质量。
背景
在金融、游戏和医疗保健等领域,为机器学习模型所做的预测提供可靠的解释具有极高的重要性,因为透明度和可解释性通常是道德和法律的先决条件。如图1所示,学者们经常处理复杂的视觉、文本、图结构数据通过选择最显著的因子,但是对解释时间序列模型的方法的研究仍然是一个未充分探索的前沿。此外,将最初为不同数据类型设计的解释器进行适配带来了挑战,因为它们的归纳偏差可能难以适应时间序列数据本质上的复杂性和较低的可解释性。
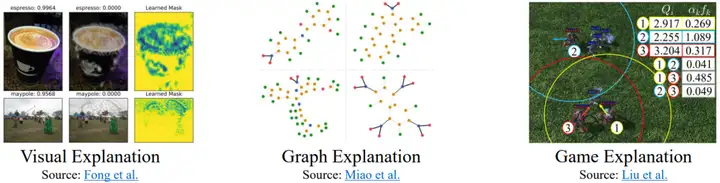
图一:基于显著图的解释在视觉、图数据、游戏场景的应用
挑战
现有的解释方法涉及使用显著性方法,这些方法的解释区分取决于它们与任意模型的交互方式。一些工作建立了显著图,例如,结合梯度或构造注意力机制,以更好地处理时间序列特征,而它们难以发现时间序列模式。其他替代方法,包括Shapley值或LIME,通过加权线性回归在局部近似模型预测,为我们提供解释。这些方法主要提供实例级别的显著图,但特征间的互相关常常导致显著的泛化误差。在时间序列中最常见的基于扰动的方法通常通过基线、生成模型或使数据无信息的特征来修改数据,但这些扰动的非显著区域并不总是无意义的并且存在不在数据分布内的样本,导致解释模型存在偏差,如图二所示。我们的工作通过样本间反事实扰动,专注于理解模型在不同群组间的整体和具体行为。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3638
3638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









