







1. 背景
ZooKeeper(ZK)是一个诞生于 2007 年的分布式应用程序协调服务。尽管出于一些特殊的历史原因,许多业务场景仍然不得不依赖它。比如,Kafka、任务调度等。特别是在 Flink 混合部署 ETCD 解耦 时,业务方曾要求绝对的稳定性,并强烈建议不要使用自建的 ZooKeeper。出于对稳定性的考量,采用了阿里的 MSE-ZK。自从 2022 年 9 月份开始使用至今,得物技术团队没有遇到任何稳定性问题,SLA 的可靠性确实达到了 99.99%。
在 2023 年,部分业务使用了自建的 ZooKeeper(ZK)集群,然后使用过程中 ZK 出现了几次波动,随后得物 SRE 开始接管部分自建集群,并进行了几轮稳定性加固的尝试。接管过程中得物发现 ZooKeeper 在运行一段时间后,内存占用率会不断增加,容易导致内存耗尽(OOM)的问题。得物技术团队对这一现象非常好奇,因此也参与了解决这个问题的探索过程。
2. 探索分析
2.1 确定方向
在排查问题时,非常幸运地发现了一个测试环境的故障现场,该集群中的两个节点恰好处于 OOM 的边缘状态。

有了故障现场,那么一般情况下距离成功终点只剩下 50%。内存偏高,按以往的经验来看,要么是非堆,要么是堆内有问题。从火焰图和 jstat 都能证实:是堆内的问题。

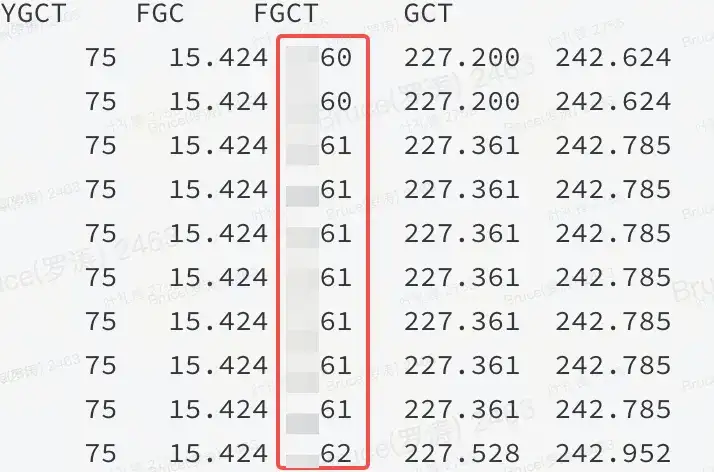
如图所示:说明 JVM 堆内存在某种资源占用了大量的内存,并且 FGC 都无法释放。
2.2 内存分析
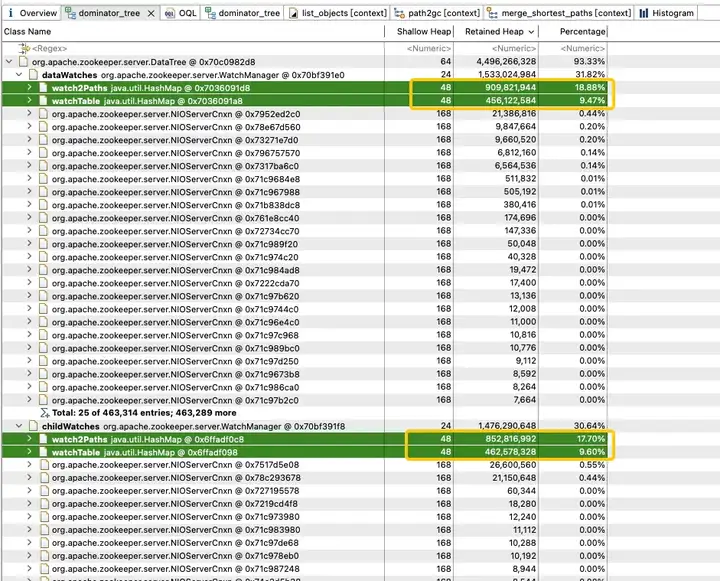
为了探究 JVM 堆中内存占用分布,得物技术团队立即做了一个 JVM 堆 Dump。分析发现 JVM 内存被 childWatches 和 dataWatches 大量占用。
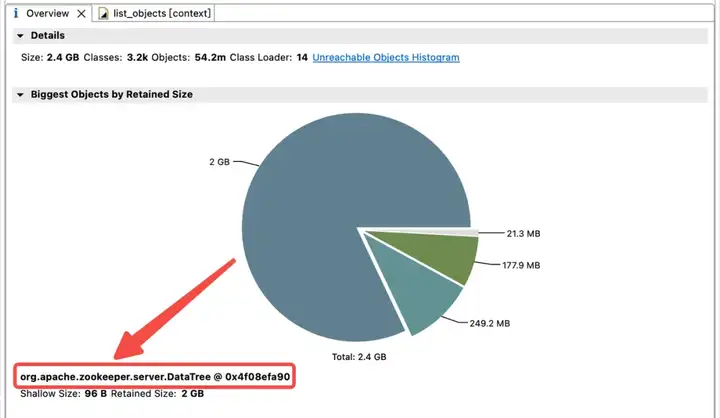
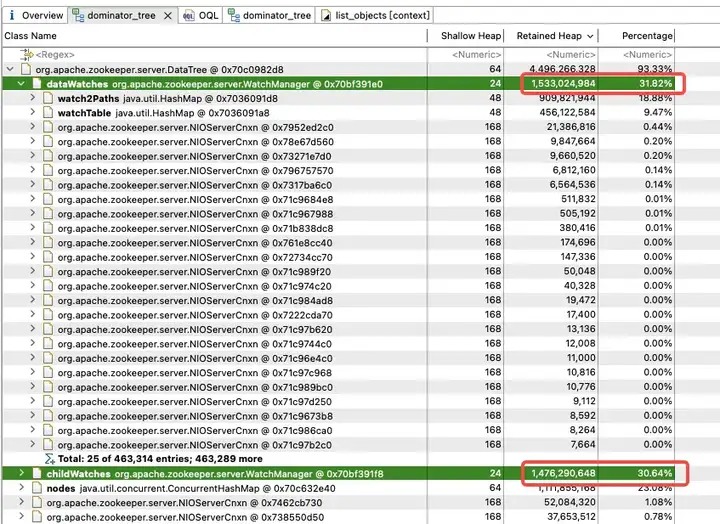
dataWatches:跟踪 znode 节点数据的变化。
childWatches:跟踪 znode 节点结构 (tree) 的变化。
childWatches 和 dataWatches 同源于 WatcherManager。
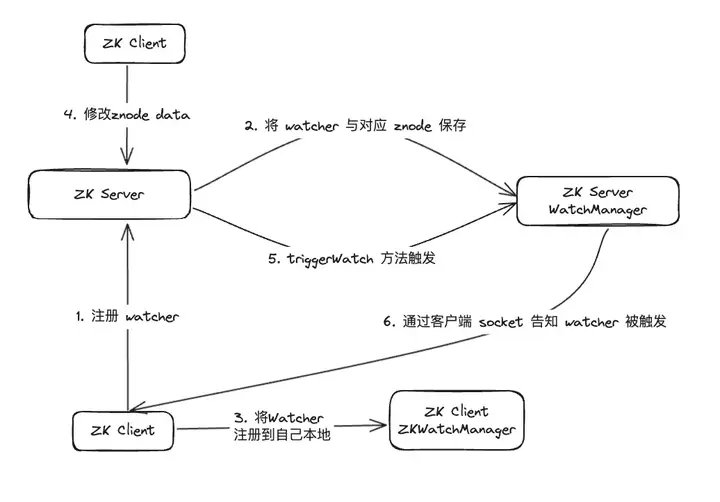
经过资料排查,发现 WatcherManager 主要负责管理 Watcher。ZooKeeper(ZK)客户端首先将 Watcher 注册到 ZooKeeper 服务器上,然后由 ZooKeeper 服务器使用 WatcherManager 来管理所有的 Watcher。当某个 Znode 的数据发生变更时,WatchManager 将触发相应的 Watcher,并通过与订阅该 Znode 的 ZooKeeper 客户端的 socket 进行通信。随后,客户端的 Watch 管理器将触发相关的 Watcher 回调,以执行相应的处理逻辑,从而完成整个数据发布/订阅流程。
进一步分析 WatchManager,成员变量 Watch2Path、WatchTables 内存占比高达 (18.88+9.47)/31.82 = 90%。
而 WatchTables、Watch2Path 存储的是 ZNode 与 Watcher 正反映射关系,存储结构图所示:
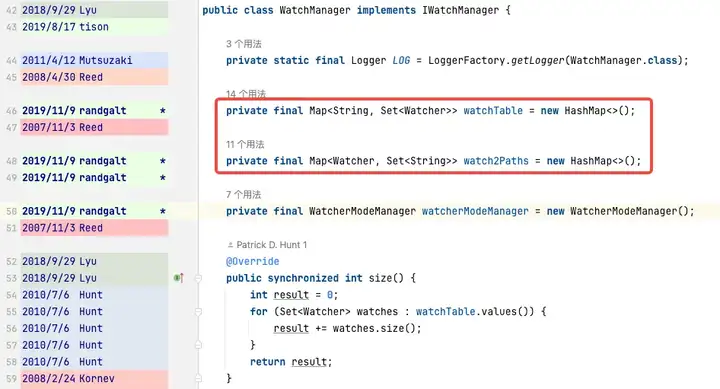
WatchTables【正向查询表】HashMap>
场景:某个 ZNode 发生变化,订阅该 ZNode 的 Watcher 会收到通知。
逻辑:用该 ZNode,通过 WatchTables 找到
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2012
2012

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









