







导语
上篇系列文 混部之殇-论云原生资源隔离技术之CPU隔离(一) 介绍了云原生混部场景中CPU资源隔离核心技术:内核调度器,本系列文章《Linux内核调度器源码分析》将从源码的角度剖析内核调度的具体原理和实现,我们将以 Linux kernel 5.4 版本(TencentOS Server3 默认内核版本)为对象,从调度器子系统的初始化代码开始,分析 Linux 内核调度器的设计与实现。
调度器(Scheduler)子系统是内核的核心子系统之一,负责系统内 CPU 资源的合理分配,需要能处理纷繁复杂的不同类型任务的调度需求,还需要能处理各种复杂的并发竞争环境,同时还需要兼顾整体吞吐性能和实时性要求(本身是一对矛盾体),其设计与实现都极具挑战。
为了能够理解 Linux 调度器的设计与实现,我们将以 Linux kernel 5.4 版本(TencentOS Server3 默认内核版本)为对象,从调度器子系统的初始化代码开始,分析 Linux 内核调度器的设计与实现。
本(系列)文通过分析 Linux 调度器(主要针对 CFS)的设计与实现,希望能够让读者了解:
- 调度器的基本概念
- 调度器的初始化(包括调度域相关的种种)
- 进程的创建、执行与销毁
- 进程切换原理与实现
- CFS 进程调度策略(单核)
- 如何在全局系统的调度上保证 CPU 资源的合理使用
- 如何平衡 CPU 缓存热度与 CPU 负载之间的关系
- 很 special 的调度器 features 分析
调度器的基本概念
在分析调度器的相关代码之前,需要先了解一下调度器涉及的核心数据(结构)以及它们的作用
运行队列(rq)
内核会为每个 CPU 创建一个运行队列,系统中的就绪态(处于 Running 状态的)进程(task)都会被组织到内核运行队列上,然后根据相应的策略,调度运行队列上的进程到 CPU 上执行。
调度类(sched_class)
内核将调度策略(sched_class)进行了高度的抽象,形成调度类(sched_class)。通过调度类可以将调度器的公共代码(机制)和具体不同调度类提供的调度策略进行充分解耦,是典型的 OO(面向对象)的思想。通过这样的设计,可以让内核调度器极具扩展性,开发者通过很少的代码(基本不需改动公共代码)就可以增加一个新的调度类,从而实现一种全新的调度器(类),比如,deadline调度类就是3.x中新增的,从代码层面看只是增加了 dl_sched_class 这个结构体的相关实现函数,就很方便的添加了一个新的实时调度类型。
目前的5.4内核,有5种调度类,优先级从高到底分布如下:
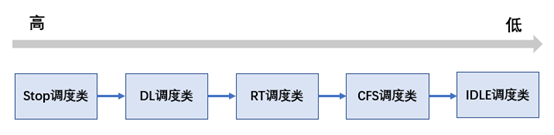
stop_sched_class:
优先级最高的调度类,它与 idle_sched_class 一样,是一个专用的调度类型(除了 migration 线程之外,其他的 task 都是不能或者说不应该被设置为 stop 调度类)。该调度类专用于实现类似 active balance 或 stop machine 等依赖于 migration 线程执行的“紧急”任务。
dl_sched_class:
deadline 调度类的优先级仅次于 stop 调度类,它是一种基于 EDL 算法实现的实时调度器(或者说调度策略)。
rt_sched_class:
rt 调度类的优先级要低于 dl 调度类,是一种基于优先级实现的实时调度器。
fair_sched_class:
CFS 调度器的优先级要低于上面的三个调度类,它是基于公平调度思想而设计的调度类型,是 Linux 内核的默认调度类。
idle_sched_class:
idle 调度类型是 swapper 线程,主要是让 swapper 线程接管 CPU,通过 cpuidle/nohz 等框架让 CPU 进入节能状态。
调度域(sched_domain)
调度域是在2.6里引入内核的,通过多级调度域引入,能够让调度器更好的适应硬件的物理特性(调度域可以更好的适配 CPU 多级缓存以及 NUMA 物理特性对负载均衡所带来的挑战),实现更好的调度性能(sched_domain 是为 CFS 调度类负载均衡而开发的机制)。
调度组(sched_group)
调度组是与调度域一起被引入内核的,它会与调度域一起配合,协助 CFS 调度器完成多核间的负载均衡。
根域(root_domain)
根域主要是负责实时调度类(包括 dl 和 rt 调度类)负载均衡而设计的数据结构,协助 dl 和 rt 调度类完成实时任务的合理调度。在没有用 isolate 或者 cpuset cgroup 修改调度域的时候,那么默认情况下所有的CPU都会处于同一个根域。
组调度(group_sched)
为了能够对系统里的资源进行更精细的控制,内核引入了 cgroup 机制来进行资源控制。而 group_sched 就是 cpu cgroup 的底层实现机制,通过 cpu cgroup 我们可以将一些进程设置为一个 cgroup,并且通过 cpu cgroup 的控制接口配置相应的带宽和 share 等参数,这样我们就可以按照 group 为单位,对 CPU 资源进行精细的控制。
调度器初始化(sched_init)
下面进入正题,开始分析内核调度器的初始化流程,希望能通过这里的分析,让大家了解:
1、运行队列是如何被初始化的
2、组调度是如何与 rq 关联起来的(只有关联之后才能通过 group_sched 进行组调度)
3、CFS 软中断 SCHED_SOFTIRQ 注册
调度初始化(sched_init)
start_kernel
|----setup_arch
|----build_all_zonelists
|----mm_init
|----sched_init 调度初始化
调度初始化位于 start_kernel 相对靠后的位置,这个时候内存初始化已经完成,所以可以看到 sched_init 里面已经可以调用 kzmalloc 等内存申请函数了。
sched_init 需要为每个 CPU 初始化运行队列(rq)、dl/rt 的全局默认带宽、各个调度类的运行队列以及 CFS 软中断注册等工作。
接下来我们看看 sched_init 的具体实现(省略了部分代码):
void __init sched_init(void)
{
unsigne 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 702
702











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









