









从预训练模型到生成式大模型发展方向研究简述
为了解决同一模型在不同下游任务上的泛化水平,自然语言处理在2019年开始学习了计算机视觉的解决方案,采用一个基础的模型,然后在此基础上进行微调。这种思路出发点诞生了基于“预训练的模型”。预训练主要分为两大分支,一支是自编码语言模型(Autoencoder Language Model),自回归语言模型(Autoregressive Language Model)
自回归语言模型是根据上文内容预测下一个可能的单词,就是常说的自左向右的语言模型任务,或者反过来也行,就是根据下文预测前面的单词。GPT 就是典型的自回归语言模型。
优点
其实跟下游NLP任务有关,比如生成类NLP任务,比如文本摘要,机器翻译等,在实际生成内容的时候,就是从左向右的,自回归语言模型天然匹配这个过程。
缺点
只能利用上文或者下文的信息,不能同时利用上文和下文的信息。
自编码语言模型是对输入的句子随机Mask其中的单词,然后预训练过程的主要任务之一是根据上下文单词来预测这些被Mask掉的单词,那些被Mask掉的单词就是在输入侧加入的噪音。BERT就是典型的自编码类语言模型。
优点
它能比较自然地融入双向语言模型,同时看到被预测单词的上文和下文。
缺点
主要在输入侧引入[Mask]标记,导致预训练阶段和Fine-tuning阶段不一致的问题,因为Fine-tuning阶段是看不到[Mask]标记的。而Bert这种自编码模式,在生成类NLP任务中,就面临训练过程和应用过程不一致的问题,导致生成类的NLP任务到目前为止都做不太好。


自然语言预训练模型(BERT;GPT;GLM)
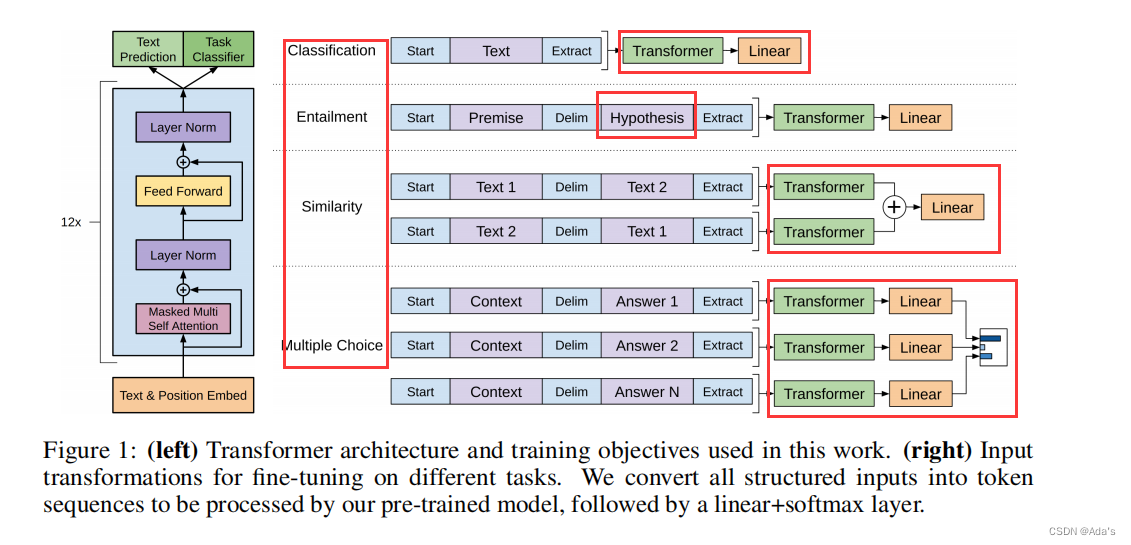
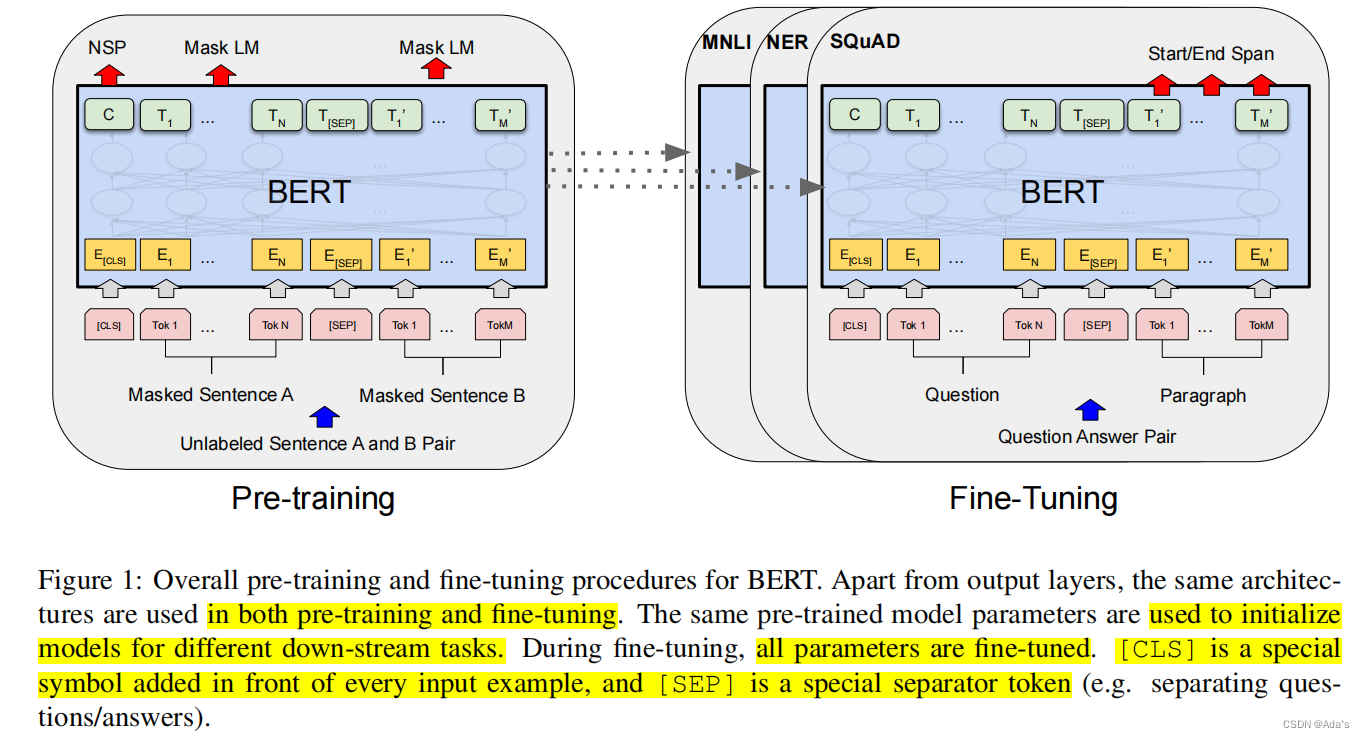
【BERT】作为自编码语言模型的代表,它并没有完全使用Transformer的编码器,模型主要的创新是预训练模型方法上。通过使用语言随机掩码模型MLM对大量的无监督学习数据中一句话的任意词替换和遮挡,然后让模型通过上下文关系进行预测该部分内容,然后计算损失时候,只计算被替换和遮挡部分的损失其他不计。
这样做的好处,BERT并不知道mask的哪一个词,而且一句中任意词都有可能被mask。这种通过句子的上下文来预测被掩码的部分使其语义连续性更加准确。
与此同时,它还包括使用了NSP这种结构用来判断两个句子是否存在前后关系,同时在被分析的两个句子开头加[CLS]和句子末尾分别加上[SEP]标识符。拼接组装当长度超过规定范围,又开始从头或尾部标记。通过这种做法保证了句子的完整度,通过正负样本等比例方式实现了二分类(正样本上下文两个句子,负样本上文一句,其他下文段落取一句)。这样通过MLM解决了词之间的关系,通过NSP解决了句子之间关系甚至可以表达段落关系。
【GPT】最为自回归语言模型代表,相比自编码,这种自回归更大的优势在生成领域。通过多头注意力获取的信息反馈到句子中可以捕捉长依赖关系,并且具有高效的并行能力。
在结构上它是采用了decoder-only总体设计思想,GPT是比BERT早提出。而BERT采用了decoder-encoder结构。
生成式大语言模型(InstructGPT;ChatGLM)
多模态生成式模型
智能体与具身智能
异构多模态认知智能(区别其他模型核心:结构因果表示学习)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









