







 本文深入探讨了决策树模型,包括其原理、构建过程和信息增益概念。介绍了ID3算法,强调了其在处理分类任务中的优势和不足。此外,还讨论了决策树的优缺点,并提及了其他如C4.5等算法。通过对相亲场景的举例,解释了如何将决策过程转化为决策树结构。
本文深入探讨了决策树模型,包括其原理、构建过程和信息增益概念。介绍了ID3算法,强调了其在处理分类任务中的优势和不足。此外,还讨论了决策树的优缺点,并提及了其他如C4.5等算法。通过对相亲场景的举例,解释了如何将决策过程转化为决策树结构。
机器学习中,决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。
当一个女孩家人push他去相亲,这时候见与不见就需要斟酌斟酌。
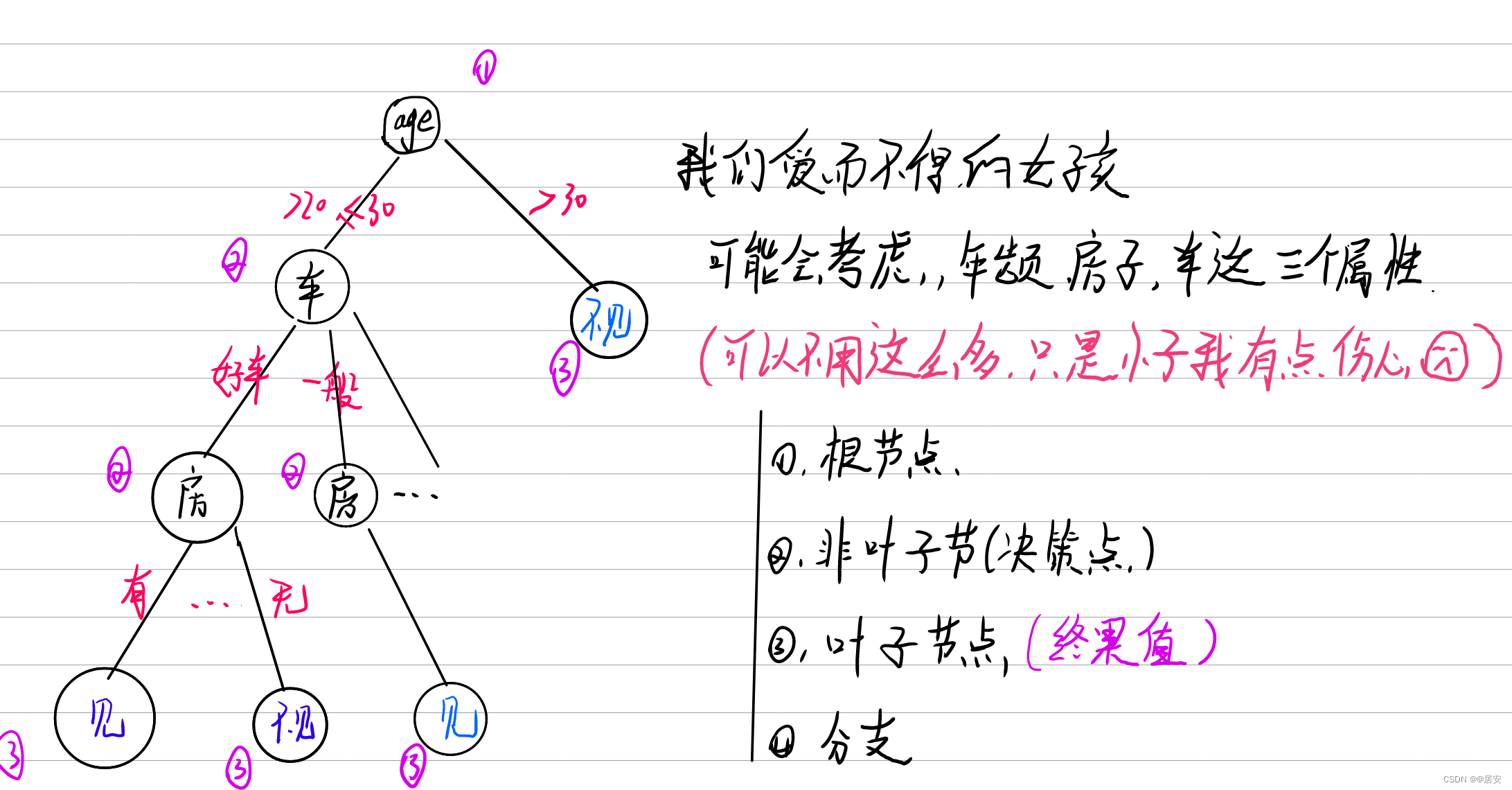
上图女生选择见与不见就是一个决策的过程,我们的每一个非叶子节点都是我们一个决策点,上述的过程也是可以转换成我们的if-then规则的过程的:由决策树的根节点到叶节点的每一条路径构建一条规则,叶节点的类对应着规则的结论。同时决策树的一条路径都具有if-then的一个重要的性质:互斥且完备,可以这要去理解上述的决策树。这时候你可能有许多的疑问,上述的年龄为啥作为根节点,且年龄为啥划分为20-30,>30,且听我娓娓道来。
决策树的构造
决策树的算法通常都是递归最优特征,对这个特征的训练集合进行分割,使得我们的各个子数据集都有一个很好的分类
1,开始:创立根节点(权值比较大的),并根据这个特征值对训练集分类。
2,如果子集已经被正确分类,那么构建叶节点,并将子集对应到相应的叶节点上去。
3,如果没有正确分类,那么对这些子集选取最优特征,并根据这个特征值对训练集合进行分割, 构建节点,递归到所有的子集训练子集被正确分类或者找不到合适的为止。
4,每个子集都被分到一个叶子结点,即有了结果标签。
#creat()
if 标签清一色: return 标签;
else
寻找最佳特征值;
划分特征值区间;
创建支节点;
for 遍历特征值区间:
调用creat()函数,对当前特征值空间划分
return 支节点;信息增益
2.1 熵
高中我们化学中熵用来衡量化学式子的混乱程度的,后来香农提出,一条信息的信息量大小和它的不确定性有直接的关系。比如说,我们要搞清楚一件非常非常不确定的事,或是我们一无所知的事情,就需要了解大量的信息。相反,如果我们对某件事已经有了较多的了解,我们不需要太多的信息就能把它搞清楚。所以,从这个角度,我们可以认为,信息量的度量就等于不确定性的多少。

2.2特征值的选择
特征值的选择在于对训练数据具有分类能力的特征。这样可以提高决策树的学习效率,我们可以这样理解,我去完成一件工作,可以分成两步,四步,五步去完成,我肯定要选择两步的情况。对照决策树节点分类的过程, 分两步,分四步都是一个熵值下降的过程(每个类里面的个体都越来越来确定了)熵是急剧下降就是我们我们想要的路径,得到的树的高度就越矮。如果利用一个特征进行分类的结果与随机分类的结果没有太大的差距,则称这个特征是没有分类能力的,经验上扔掉这样的特征对决策树学习的精度影响不大。

我们看到熵值熵在概率为1,或者为0的时候熵值为0了,因为概率为1,都是必然事件了,哪还有不确定性了。
2.3信息增益
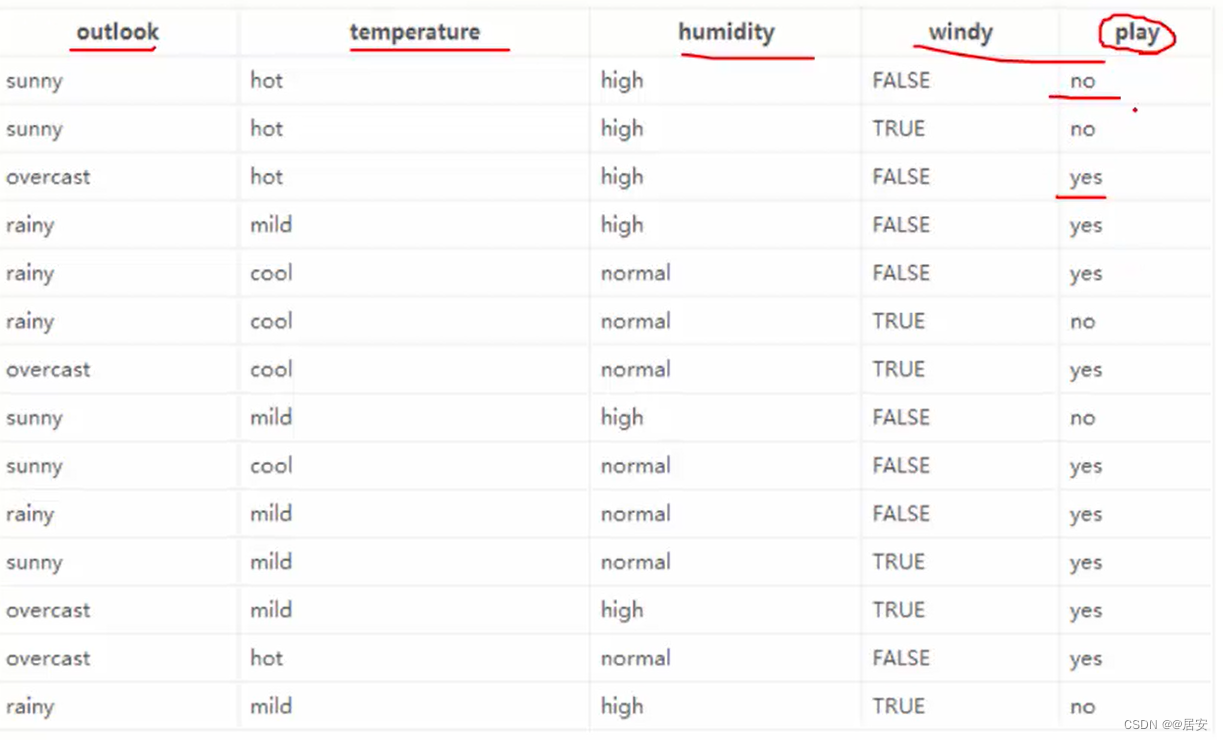
有上图这样的数据,是关于我要不要出去打球。我要开始决策这件事情了。根据以往的数据我们今天去打球的概率为9/14,不去打球的概率为5/14,此时我们自身的熵值为![]()
这时候我们需要查看选择特征点,我们先来看看outlook这个属性,
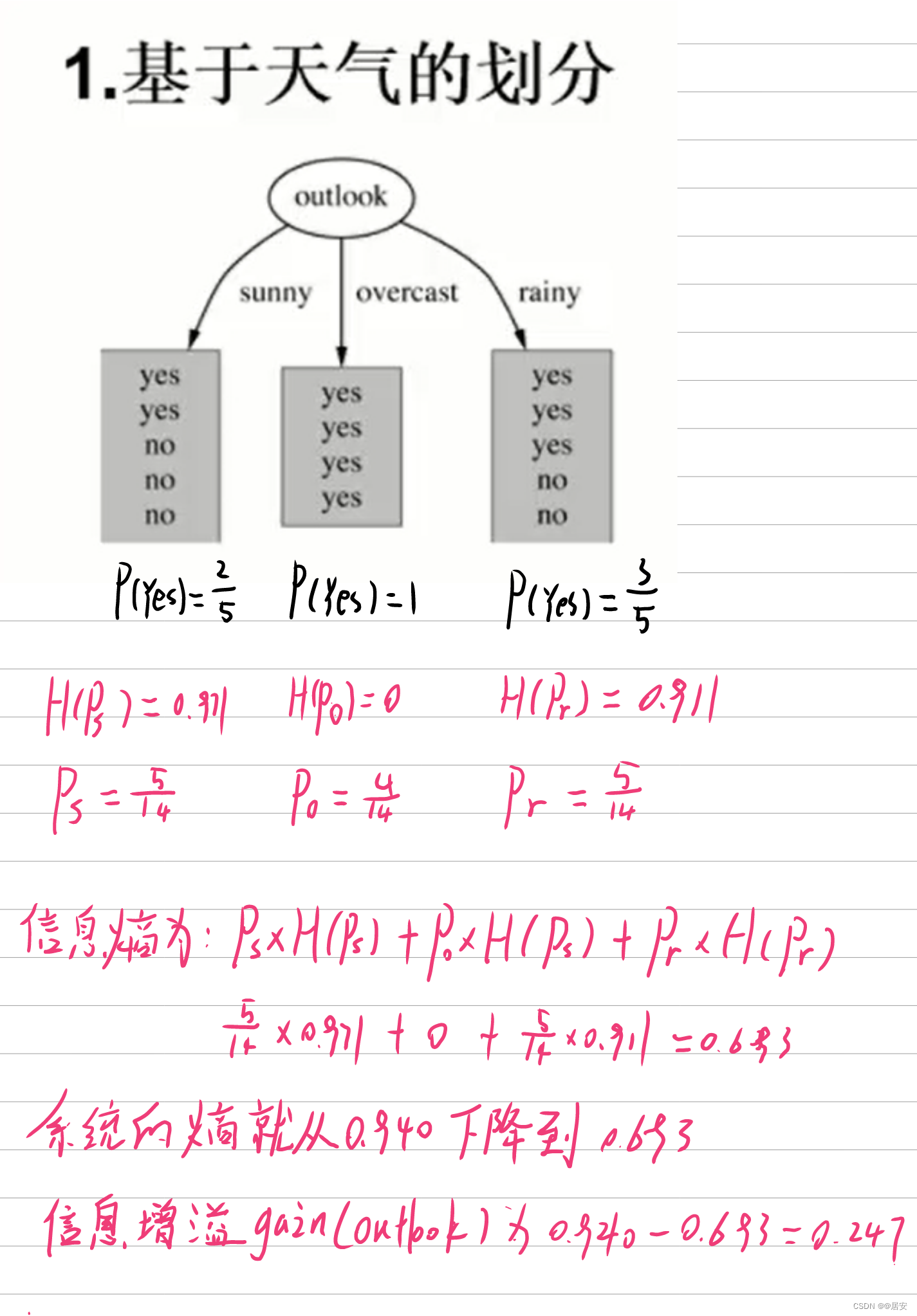
上图中我们给出了overlook这个属性的熵值过程,下一步就是计算所有特征点的熵,选出其中熵值最大的,作为我们分类的一个支点,其中信息增益是原先系统的熵值与分类后系统熵值得差,用来衡量分类前后熵值的变化,我们希望我们熵值迅速的降低,就是让我们的信息增益越大。如此下去我们的决策树就可以完美的构建出来。
决策树的优缺点
决策树是一种监督学习。根据决策树的结构决策树可分为二叉决策树和多叉树,例如有的决策树算法只产生二叉树(其中,每个内部节点正好分叉出两个分支),而另外一些决策树算法可能产生非二叉树。
决策树是从有类别名称的训练数据集中学习得到的决策树。它是一种树形结构的判别树,树内部的每个非叶子节点表示在某个属性的判别条件,每个分支表示该判别条件的一个输出,而每个叶子节点表示一个类别名称。树的首个节点是根节点。
在决策树模型构建完成后,应用该决策模型对一个给定的但类标号未知的元组X进行分类是通过测试该元组X的属性值,得到一条由根节点到叶子节点的路径,而叶子节点就存放着该元组的类测。这样就完成了一个未知类标号元组数据的分类,同时决策树也可以表示成分类规则。
常见决策树
(1)、CLS算法:是最原始的决策树分类算法,基本流程是,从一棵空数出发,不断的从决策表选取属性加入数的生长过程中,直到决策树可以满足分类要求为止。CLS算法存在的主要问题是在新增属性选取时有很大的随机性。
(2)、ID3算法:对CLS算法的最大改进是摒弃了属性选择的随机性,利用信息熵的下降速度作为属性选择的度量。ID3是一种基于信息熵的决策树分类学习算法,以信息增益和信息熵,作为对象分类的衡量标准。ID3算法结构简单、学习能力强、分类速度快适合大规模数据分类。但同时由于信息增益的不稳定性,容易倾向于众数属性导致过度拟合,算法抗干扰能力差。
ID3算法的核心思想:根据样本子集属性取值的信息增益值的大小来选择决策属性(即决策树的非叶子结点),并根据该属性的不同取值生成决策树的分支,再对子集进行递归调用该方法,当所有子集的数据都只包含于同一个类别时结束。最后,根据生成的决策树模型,对新的、未知类别的数据对象进行分类。
ID3算法优点:方法简单、计算量小、理论清晰、学习能力较强、比较适用于处理规模较大的学习问题。
ID3算法缺点:倾向于选择那些属性取值比较多的属性,在实际的应用中往往取值比较多的属性对分类没有太大价值、不能对连续属性进行处理、对噪声数据比较敏感、需计算每一个属性的信息增益值、计算代价较高。
还有C4.5,SLIQ,CART这几种算法,读者自行查阅。
上述的例子是来自




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











