







一:简介
*1. 什么是Hadoop*
What Is Apache Hadoop? The Apache™ Hadoop® project develops
open-source software for reliable, scalable, distributed computing.
根据Hadoop官网介绍。Hadoop是一个开源的,分布式的,可靠的,灵活的 计算系统。很多大公司都在定制自己的Hadoop版本。
解决问题:
海量数据的存储(HDFS)
海量数据的分析(MapReduce)作者:Doug Cutting
Doug Cutting简介:生活中,可能所有人都间接用过他的作品,他是Lucene、Nutch 、Hadoop等项目的发起人。是他,把高深莫测的搜索技术形成产品,贡献给普通大众;还是他,打造了在云计算和大数据领域里如日中天的Hadoop 。
受Google三篇论文的启发(GFS、MapReduce、BigTable)
- -
HDFS:
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。HDFS是Apache Hadoop Core项目的一部分。
HBase:
是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
2.Hadoop2.0之后出现了YARN
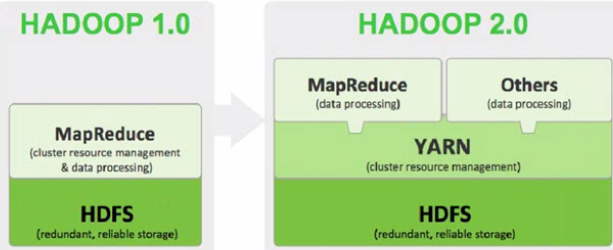
在Hadoop1.0的时候,Hadoop只能运行MapReduce,Hadoop2.0出现之后,使下一代的MapReduce(MRv2/Yarn)框架具有更好的扩展性、可用性、可靠性、向后兼容性和更高的资源利用率以及能支持除了MapReduce计算框架外的更多的计算框架。
3.hadoop最擅长的

hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
4.哪些公司在使用Hadoop

5.Hadoop在淘宝

6.Hadoop Ecosystem Map
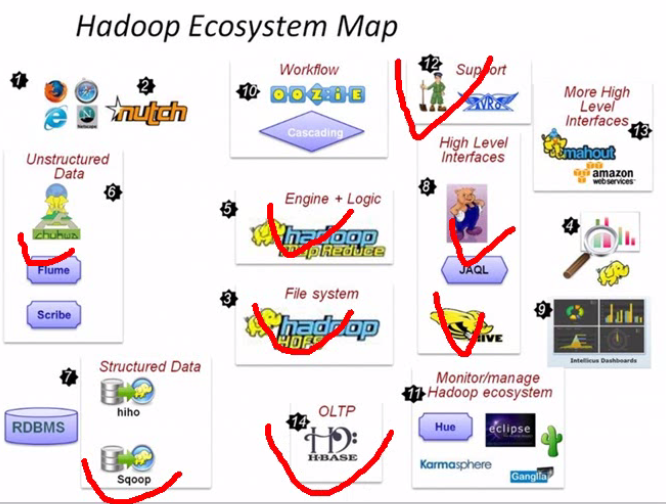
7.Hadoop核心

8.Hadoop1.0与2.0比较
二:简介
HDFS的架构
- 主从节点
-主节点,只有一个:namenode
-从节点,有很多:nadanodes namenode负责:
-接受用户操作请求
-维护文件系统的目录结构
-管理文件与block之间关系,block与datanode之间关系nadanodes负责:
- 存储文件
- 文件被分为block存储在磁盘上
- 为保证数据安全,文本会有很多副本
怎么解决海量存储问题 ?
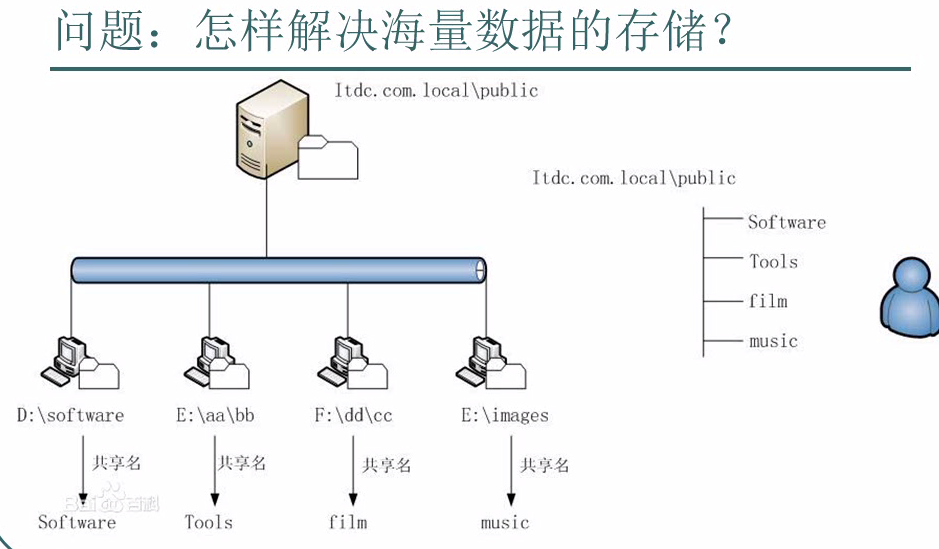
答:HDFS 解决海量数据的存储
怎么解决海量存储问题 ?
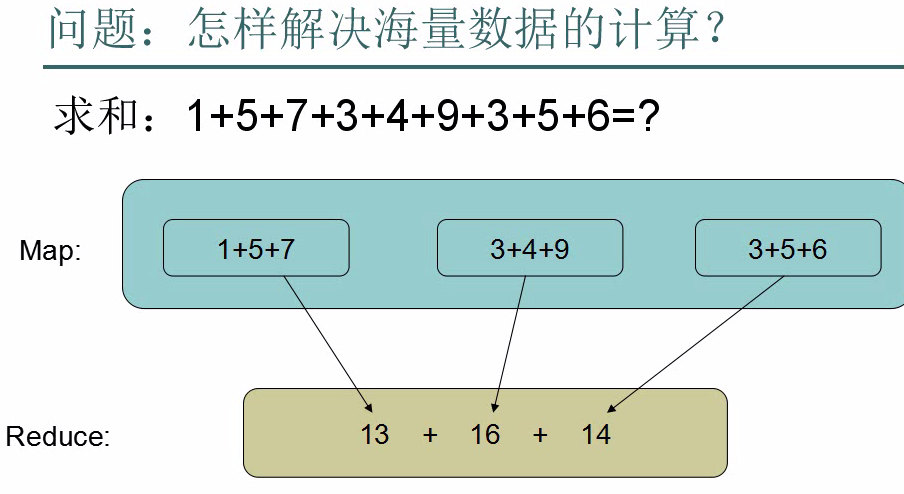
答:MapReduce解决海量数据计算的问题
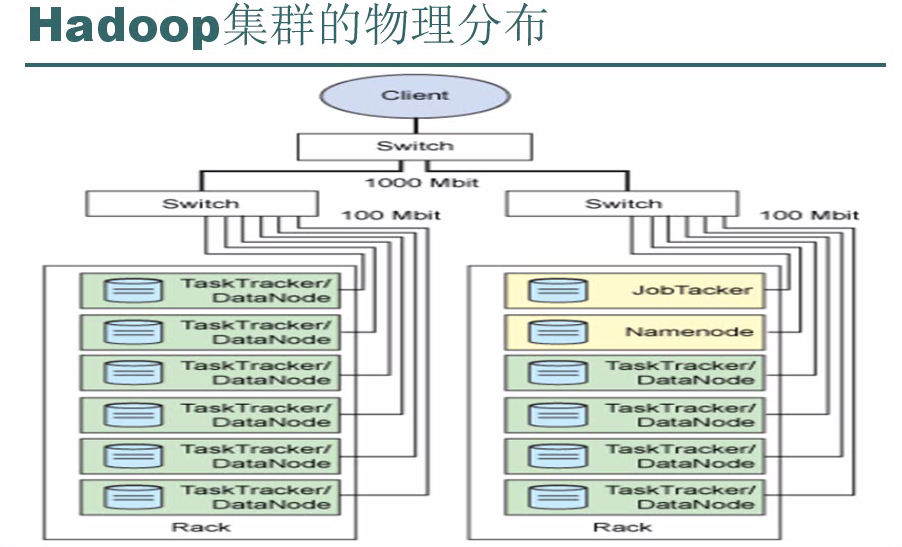
Hadoop集群的物理分布
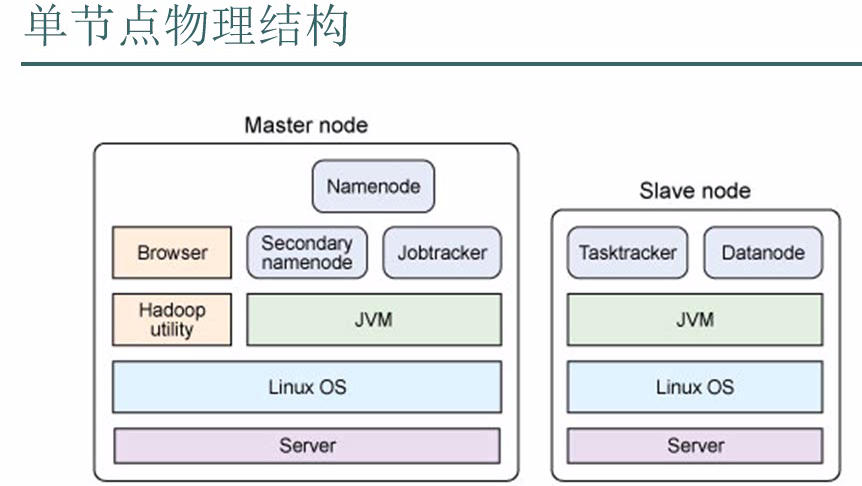
单节点物理结构
Hadoop的部署方式
- 本地模式(用来调试的)
- 伪分布式()
- 集群环境(生产环境)















 3823
3823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









