







前言
这篇文章主要介绍一下 Elasticsearch 里面的基本概念,包括索引、文档、REST API、集群、节点、分片、副本。
基本概念
传统数据库和 ElasticSearch 的区别
| 数据库(RDBMS) | Elasticsearch |
|---|---|
| Table | Index(Type) |
| Row | Document |
| Column | Filed |
| Schema | Mapping |
| SQL | DSL |
- Document(文档):是所有可搜索数据的最小单位,文档会被序列化成 JSON 格式,每个文档都有一个唯一的ID,这个ID可以自己指定,也可以自动生成。
- 元数据:用于标注文档的相关信息

- _index:文档所属的索引名
- _type:文档所属的类型名,7.0以后统一只能指定一种类型_doc
- _id:文档唯一的 id
- _source:文档的原始 Json 数据
- _score:相关性打分
- _version:上图没有显示出来,这个版本号代表文档的版本信息
- Index:索引是文档的容器,是一类文档的集合。名词:一个 ES 集群中,可以创建很多不同的索引(B树索引)。动词:保存一个文档到 ES 的过程也叫索引,比如创建一个倒排索引的过程。

- 索引中的 Mapping 定义了文档字段的类型、Settings 定义了不同的数据分布,分布在几个分片等信息。
- Index 是逻辑空间的概念,每个索引都有自己的 Mapping 定义,用于定义包含的文档的字段名和字段类型。
- Shard 是物理空间的概念,索引中的数据分散在分片上
- Type:7.0以前,一个 Index 可以设置多个 Type。7.0开始,一个索引只能创建一个 Type - “_doc”
- REST API:可以很容易被各种语言调用。例如:PUT products 创建 Index,GET movies/_mapping 查看 mapping
- 节点:节点是一个 Elasticsearch 的实例,本质就是一个 Java 进程,一台机器可以运行多个 Elasticsearch 进程实例,生产上建议一台机器只运行一个实例;每一个节点都有名字,可以通过配置文件指定,也可以启动时用
-E node.name=node1指定;节点在启动后,会分配一个 UID,保存在 data 目录下。开发环境中一个节点可以承担多种角色,生产中,应该设置单一的角色节点:
| 节点类型 | 配置参数 | 默认值 |
|---|---|---|
| master eligible | node.master | true |
| data | node.data | true |
| ingest | node.ingest | true |
| coordinating only | / | 每个节点默认都是,设置其他类型全部为 false就可以指定为 coordinating 节点 |
| machine learning | node.ml | true(需要 enable x-pack) |
- 每个节点启动后,默认就是 Master eligible 节点,可以参加选主流程,第一个节点启动时,会将自己选举成 Master 节点,可通过
node.master:fasle设置为禁用。 - 每个节点上都保存了集群的状态,只有 Master 节点才能修改集群状态(Cluster State)信息,集群信息包括:所有节点信息;所有的索引和其相关的 Mapping 和 Setting 信息;分片的路由信息。
- Data Node:可以保存数据的节点,为数据扩展起到了重要的作用。
- Coordinating Node:负责接受 Client 的请求,将请求分发到合适的节点,最后把结果汇到一起。每个节点默认都起到了 Coordinating Node 的职责。
- Hot & Warm Node:不同硬件配置的 Data Node,用来实现 Hot & Warm 架构,降低集群部署成本。
- Machine Learning Node:负责跑机器学习的 JOB,用来做异常检测。
- 分片(Primary Shard & Replica Shard):生产中对分片的设定,需要提前做好容量规划。如果分片数设置过小,会导致后续无法增加节点实现水平扩展。如果分片数设置过大,会影响搜索结果相关性打分,影响统计结果的准确性,同时导致资源浪费,影响性能。
- 主分片(Primary Shard):用来解决数据水平扩展的问题,通过主分片,可以将数据分布到集群内的所有节点上。一个分片是一个运行的 Lucene 的实例,主分片数在索引创建时指定,后续不允许修改,如果要修改,需要 Reindex。
- 副本分片(Replica Shard):用来解决数据高可用问题,是主分片的拷贝。副本分片数,可以动态调整,增加副本数,可以一定程序上提高服务的可用性。
总结
这里介绍了 Elasticsearch 的基本概念,一个 Cluster 包含多个 Node,一个 Node 包含多个 Shard,每个 Shard 上面有多个 index,一个 index 又可以分布在多个 Shard 上(索引是逻辑空间,分片是物理空间)。一个 index 可以有多个 Document。下图可能更加清楚的了解各个概念之间的关系。
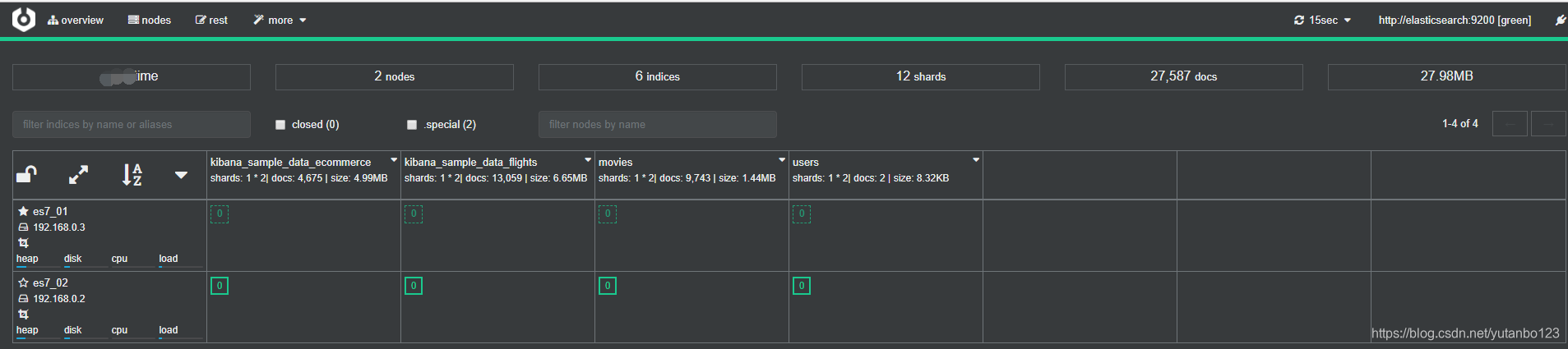
这是一个本地的 Cluster (集群),有两个 Node (节点,表格中每一行表示一个节点),12个 Shard (分片,绿色的小框),6个 indices (索引,表格中每一列表示,每个索引分布在不同的分片中),2万多个文档(在图中看到只有8个绿色小框,但是上面写的有12个 Shard,这是因为我之前建了索引删掉了,好像分片不会减少的原因)。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









