







十、文件I/O
1、使用pathlib模块操作目录
-
PurePath:代表并不访问实际文件系统的“纯路径”。PurePath只是负责对路径字符串执行操作,至于该字符串是否对应实际的路径,不关心。PurePath有两个子类:PurePosixPath和PureWindowsPath分别代表UNIX(Mac OS X)和Windows的风格。
UNIX风格的路径和WIndows风格的路径的主要区别在于根路径和路径的分隔符:UNIX风格根路径是斜杠(/),Windows风格的根路径是盘符(c:);UNIX风格的分隔符是斜杠(/),Windows风格的分隔符是反斜杠(\)。</> -
Path:代表访问实际文件系统的“真正路径”。Path对象可用于判断对应的文件是否存在、是否为文件、是否为目录等。Path有两个子类:PosixPath和WindowsPath。
1.1、PurePath的基本功能
使用PurePath或两个子类来创建PurePath对象,在UNIX或Mac OS X系统上创建,则返回PosixPath对象;在Windows系统上创建,返回WindowsPath对象。
创建PurePath和Path时,既可以传入单个路径字符串,也可以传入多个路径字符串,PurePath会将它们拼接成一个字符串。
from pathlib import *
# 创建PurePath,实际上使用PureWindowsPath
pp = PurePath('setup.py')
print(type(pp)) # <class 'pathlib.PureWindowsPath'>
pp = PurePath('crazy', 'some/path', 'info')
print(pp) # razy\some\path\info
pp = PurePath(Path('crazy'), Path('info'))
print(pp) # crazy\info
pp = PurePosixPath('crazy', 'some/path', 'info')
print(pp) # crazy/some/path/info
# 如果在创建PurePath时不传入参数,系统默认创建代表的当前路径的PurePath
# 相当于传入点号(.代表当前路径)作为参数
pp = PurePath()
print(pp) # .
如果在创建PurePath时传入的参数包含多个根路径,则只有最后一个根路径及后面的子路径生效。
pp = PurePath('/etc', '/user', '/lib64')
print(pp) # \lib64
在Windows风格的路径中,只有盘符才能算根路径,仅有斜杠是不算的。
pp = PureWindowsPath('C:/Windows', 'lib64')
print(pp) # C:\Windows\lib64
如果在创建PurePath时传入的路径字符串中包含多余的斜杠和点号,系统会直接忽略。(但不会忽略两个点:两个点代表上一级路径)
pp = PurePath("foo//bar")
print(pp) # foo\bar
pp = PurePath("foo/./bar")
print(pp) # foo\bar
pp = PurePath("foo/../bar")
print(pp) # foo\..\bar 相当于找和foo同一级的bar路径
PurePath对象支持各种比较运算符,既可以比较是否相等,也可以比较大小(实际上就是比较路径字符串)
from pathlib import *
# 比较UNIX风格路径,区分大小写
print(PurePosixPath('info') == PurePosixPath('INFO')) # False
# 比较Windows风格路径,不区分大小写
print(PureWindowsPath('info') == PureWindowsPath('INFO')) # TRUE
print(PureWindowsPath('info') in {PureWindowsPath('INFO')}) # TRUE
print(PurePosixPath('D:') < PurePosixPath('c:')) # TRUE
print(PureWindowsPath('D:') < PureWindowsPath('c:')) # False
对于不同风格的PurePath,依然可以比较是否相等(结果总是返回False)不能比较大小,报错
from pathlib import *
print(PurePosixPath('info') == PureWindowsPath('INFO')) # False
print(PurePosixPath('D:') < PureWindowsPath('c:'))
# TypeError: '<' not supported between instances of 'PurePosixPath' and 'PureWindowsPath'
PurePath对象支持斜杠(/)作为运算符,将多个路径链接起来
from pathlib import *
pp = PurePath("info")
print(pp / 'xyz' / 'axc') # info\xyz\axc
PurePath的本质就是字符串,程序可以使用str()将其恢复成字符串对象
from pathlib import *
pp = PureWindowsPath('info', 'xyz', 'axc')
print(str(pp)) # info\xyz\axc
print(type(str(pp))) # <class 'str'>
1.2、PurePath的属性和方法
PurePath提供的属性和方法,主要用于操作路径字符串。
- PurePath.parts:该属性返回路径字符串中包含的各部分
- PurePath.drive:该属性返回路径字符串中的驱动器盘符
- PurePath.root:该属性返回路径字符串中的根路径
- PurePath.anchor:该属性返回路径字符串的盘符和根路径
- PurePath.parents:该属性返回路径字符串的全部父路径
- PurePath.parent:该属性返回当前路径的上一级路径,相当于parents[0]
- PurePath.name:该属性返回当前路径中的文件名
- PurePath.suffixes:该属性返回当前路径中的文件所有后缀名
- PurePath.suffixe:该属性返回当前路径中的文件后缀名,相当于suffixes属性返回的列表中的最后一个元素
- PurePath.stem:该属性返回当前路径中的主文件名
- PurePath.as_posix():将当前路径转换成UNIX风格
- PurePath.as_uri():将当前路径转换成URI,只有绝对路径才可以转换,否则报错ValueError
- PurePath.is_absolute():判断当前路径是否是绝对路径
- PurePath.match:判断当前路径是否匹配指定通配符
- PurePath.relative_to:获取当前路径中去除基准路径之后的结果
- PurePath.with_name:将当前路径中文件名替换成新文件名,若当前路径中没有文件名,则引发错误
- PurePath.with_suffix:将当前路径中的文件后缀替换成新的后缀,若当前路径中没有后缀名,则引发错误
from pathlib import *
print(PureWindowsPath('C:/Program Files/ Users/ Info').parts) # ('C:\\', 'Program Files', ' Users', ' Info')
print(PureWindowsPath('C:/Program Files/').drive) # C:
print(PureWindowsPath('/Program Files/').drive) #
print(PureWindowsPath('C:/Program Files/').root) # \
print(PurePosixPath('/etc/').root) # /
print(PureWindowsPath('C:/Program Files/').anchor) # C:\
pp = PurePath('abc/xyz/info/user')
print(pp.parents[0]) # abc\xyz\info
print(pp.parents[1]) # abc\xyz
print(pp.parents[2]) # abc
print(pp.parents[3]) # .
print(pp.parent) # abc\xyz\info
print(pp.name) # user
pp = PurePath('abc/www/bb.txt.tar.zip')
print(pp.suffixes[0]) # .txt
print(pp.suffixes[1]) # .tar
print(pp.suffixes[2]) # .zip
print(pp.suffix) # .zip
print(pp.stem) # bb.txt.tar
print(pp.as_posix()) # abc/www/bb.txt.tar.zip
# print(pp.as_uri()) # ValueError: relative path can't be expressed as a file URI
pp = PurePath("d:/", "Python", "User/Info")
print(pp.as_uri()) # file:///d:/Python/User/Info
print(pp.is_absolute()) # True
print(PurePath('a/b.py').match('*.py')) # True
pp = PureWindowsPath('d:/Python/User/Info')
print(pp.relative_to('d:')) # \Python\User\Info
print(pp.relative_to('d:/Python')) # User\Info
pp = PureWindowsPath('d:/Python/User/info.txt')
print(pp.with_name('replace_info.txt')) # d:\Python\User\replace_info.txt
pp = PureWindowsPath('d:')
# print(pp.with_name('replace_info.txt')) # ValueError: PureWindowsPath('d:') has an empty name
pp = PureWindowsPath('d:/Python/User/info.txt')
print(pp.with_suffix('.zip')) # d:\Python\User\info.zip
pp = PureWindowsPath('d:')
# print(pp.with_suffix('.zip')) # ValueError: PureWindowsPath('d:') has an empty name
1.3、Path的功能和用法
Path是PurePath的子类,除了支持PurePath的各种操作、属性和方法外,还会真正访问底层的文件系统,包括判断Path对应的路径是否存在,获取Path对应路径的各种属性(如是否只读、是文件夹、文件等),甚至可以对文件进行读写操作。
PurePath和Path的本质区别:
PurePath的本质是字符串,Path会真正访问底层的文件路径</>
Path提供了两个子类:PosixPath和WindowsPath
Path对象包含了大量is_xxx方法,用于判断Path对应的路径是否为:xxx
Path包含exists()方法,判断该Path对应的目录是否存在
Path:iterdir():返回对应目录下的子目录和文件
Path:glob():用于获取Path对应目录及其子目录下匹配指定模式的所有文件
from pathlib import *
p = Path('.')
# 遍历当前目录下的所有文件和子目录
for x in p.iterdir():
print(x)
p = Path("../")
for x in p.glob('**/Login_Page_Locator*.py'):
print(x)
2、使用os.path操作目录
在os.path模块下提供了一些操作目录的方法,函数可以操作系统的目录本身。exists()函数判断该目录是否存在;getctime()目录的创建时间、getmtime()最后一次修改时间、getatime()最后一次访问时间;getsize()获取指定文件的大小
import os
import time
# 获取绝对路径
print(os.path.abspath("abc.txt"))
# 获取共同前缀名
print(os.path.commonprefix(['/user/lib', '/user/info'])) # /user/
# 获取目录
print(os.path.dirname('/Ceshi/111.py')) # /Ceshi
# 判断指定目录是否存在
print(os.path.exists('/Ceshi')) # False
# 获取最近一次访问时间
print(time.ctime(os.path.getatime('222.py'))) # Wed Sep 8 15:08:52 2021
# 获取最后一次修改时间
print(time.ctime(os.path.getmtime('222.py'))) # Wed Sep 8 15:09:57 2021
# 获取创建时间
print(time.ctime(os.path.getctime('222.py'))) # Wed Sep 8 15:09:57 2021
# 获取文件大小
print(os.path.getsize('222.py')) # 31332
# 判断是否为文件
print(os.path.isfile('222.py')) # True
# 判断是否为文件夹
print(os.path.isdir('222.py')) # False
# 判断是否为同一个文件
print(os.path.samefile('222.py', '222.py')) # True
3、使用fnmatch处理文件名匹配
fnmatch匹配支持如下通配符:
- *:可匹配任意个字符
- ?:可匹配任意一个字符
- [字符序列]:可匹配中括号李字符序列中的任意字符
- [!字符序列]:可匹配不在中括号里字符序列中的任意字符
- fnmatch.fnmatch(filename,pattern):判断指定文件名是否匹配指定pattern
- fnmatch.fnmatchcase(filename,pattern):判断指定文件名是否匹配指定pattern(区分大小写)
- fnmatch.filter(names,pattern):对names列表进行过滤
- fnmatch.translate(pattern):将一个UNIX shell风格的pattern转换成正则表达式pattern
from pathlib import *
import fnmatch
for file in Path('.').iterdir():
if fnmatch.fnmatch(file, '*2.py'):
print(file)
import fnmatch
names = ['a.py', 'b.py', 'c.py', 'd.py']
sub = fnmatch.filter(names, '[ac].py')
print(sub) # ['a.py', 'c.py']
4、打开文件
Python提供了一个内置的open()函数,该函数用于打开指定文件。
open(file_name [,access_mode][,buffering])
- file.closed:该属性返回文件是否已经关闭
- file.mode:该属性返回被打开文件的访问模式
- file.name:该属性返回文件的名称
f = open('222.py')
print(f.encoding) # cp936
print(f.closed) # False
print(f.mode) # r
print(f.name) # 222.py
4.1、文件打开模式
open()函数支持的文件打开模式如下表:
| 模式 | 意义 |
|---|---|
| r | 只读模式 |
| w | 写模式 |
| a | 追加模式 |
| + | 读写模式 |
| b | 二进制模式 |
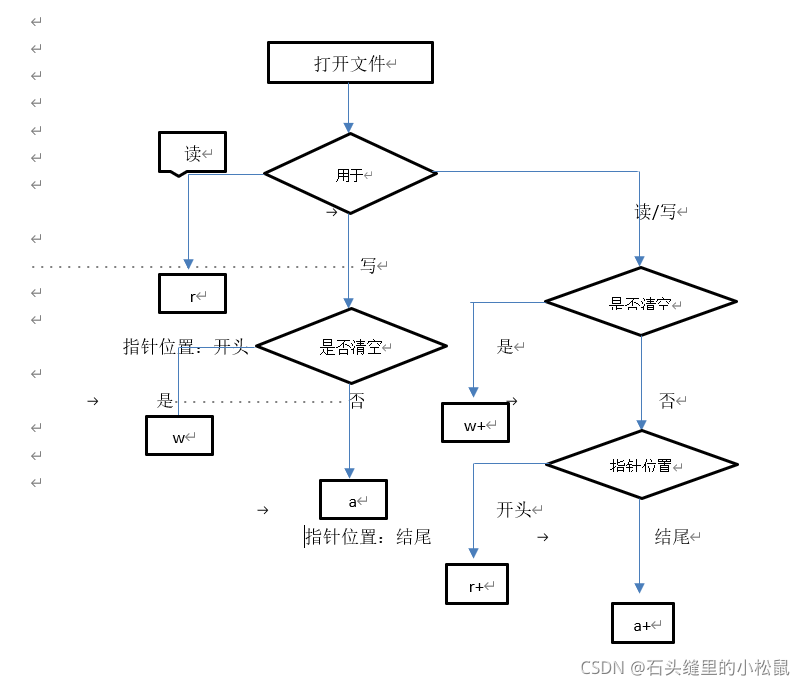
使用r或r+模式打开文件,则要求被打开的文件本身是存在的。(r/r+模式不能穿件文件)。使用w/w+/a/a+模式打开文件,文件可以不存在,open()函数可以自动创建文件。
4.2、缓冲
使用open函数时,第三个参数为0(False)时,函数打开的文件不带缓冲;1(True)带缓冲
5、读取文件
5.1、按字节或字符读取
文件对象提供read()方法来按照字节或字符读取文件内容,读取字节/字符取决于是否使用了b模式。使用b模式,每次读取一个字节;没有使用b模式,每次读取一个字符。
f = open('ceshi.txt', 'r', encoding='utf-8')
try:
while True:
ch = f.read(1)
if not ch:
break
print(ch, end='')
finally:
f.close()
如果调用read()函数时不传入参数,默认读取全部文件的内容
f = open('ceshi.txt', 'r', encoding='utf-8')
print(f.read())
f.close()
5.2、按行读取
- readline([n]):读取一行内容。如果指定了参数n,则只读取此行内的n个字符
- readlines():读取文件内所有行
f = open('ceshi.txt', 'r', encoding='utf-8')
# print(f.read())
# f.close()
try:
while True:
line = f.readline()
if not line:
break
print(line, end='')
finally:
f.close()
5.3、使用fileinput读取多个输入流(后续学习)
5.4、文件迭代器(后续学习)
5.5、管道输入(后续学习)
5.6、使用with语句
with语句管理资源关闭,不需要显示关闭文件
语法格式:
with context_expression [as target(s)]:
with代码块
with open('ceshi.txt', 'r', encoding='utf-8') as f:
for line in f:
print(line, end='')
6、写文件(后续学习)
7、os模块的文件和目录函数
7.1、与目录相关的函数
- os.getcwd():获取当前目录
- os.chdir(path):改变当前目录
- os.fchdir(fd):通过文件描述符改变当前目录














 2050
2050











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









